对抗知识焦虑,从看懂这条开始
App 下载
AI时代算力即命运,谷歌凭基建领跑全球
光纤网络|数据中心|TPU芯片|谷歌|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载光纤网络|数据中心|TPU芯片|谷歌|AI算力|人工智能
当你在手机上发出一句AI提问,后台正发生一场看不见的算力竞速:你的请求要穿过全球光纤网络,在百万级芯片组成的集群里完成计算,再毫厘不差地送回屏幕——这一切必须在300毫秒内完成,慢一秒,你可能就会切换到另一个APP。2026年初的财报季,谷歌用10%的股价涨幅证明了这场竞速的残酷:当AI模型的性能差距正在快速收窄,谁能把算力铺得更密、跑得更快,谁就能握住用户的注意力。而谷歌的底气,藏在它布局了十年的算力基建里。
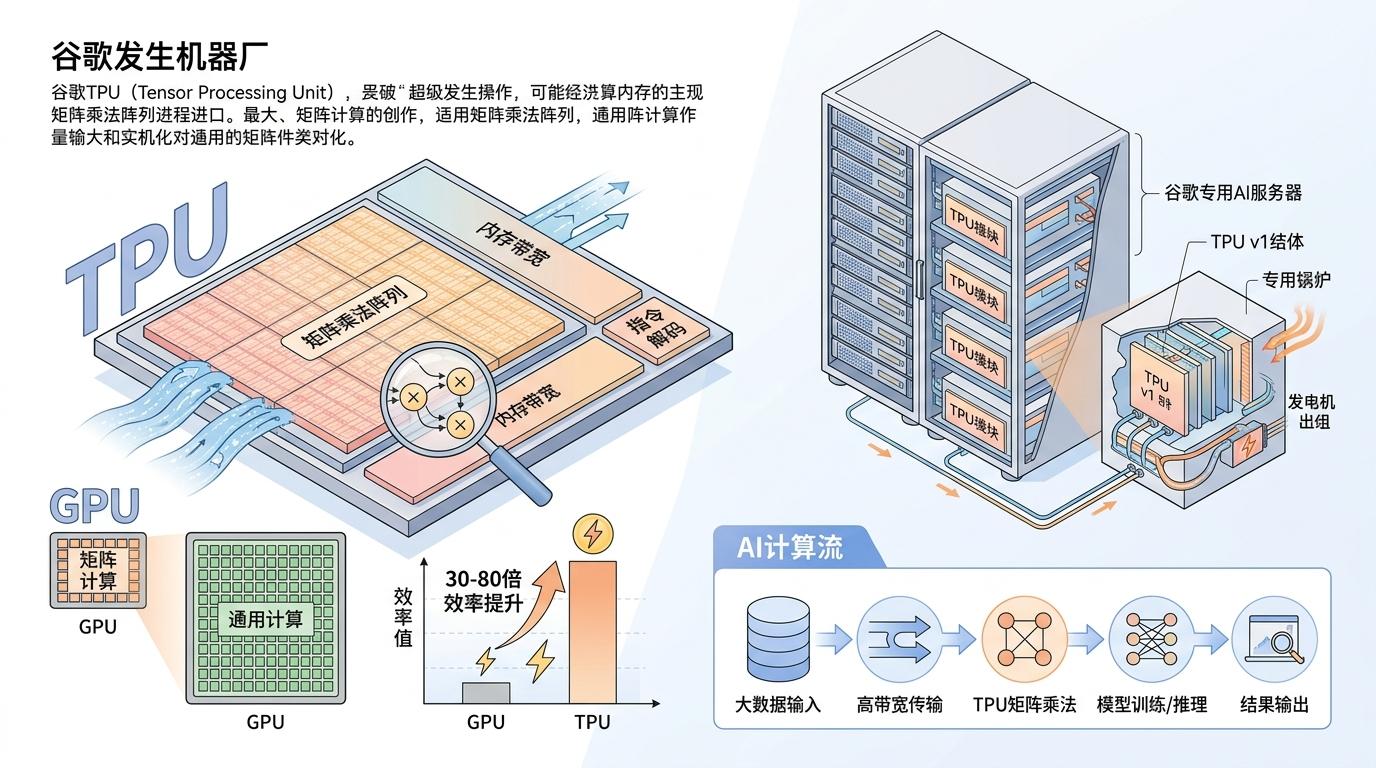
你可以把AI算力理解成“数字发电厂”:芯片是发电机组,数据中心是发电站,光纤网络是输电线,而TPU就是谷歌专为AI定制的“超级发电机组”。2015年谷歌推出第一代TPU时,行业还在通用GPU上挤性能——TPU放弃了通用计算的冗余设计,把所有算力都堆在AI最需要的矩阵乘法上,就像只烧一种燃料的专用锅炉,效率比通用GPU高出30到80倍。
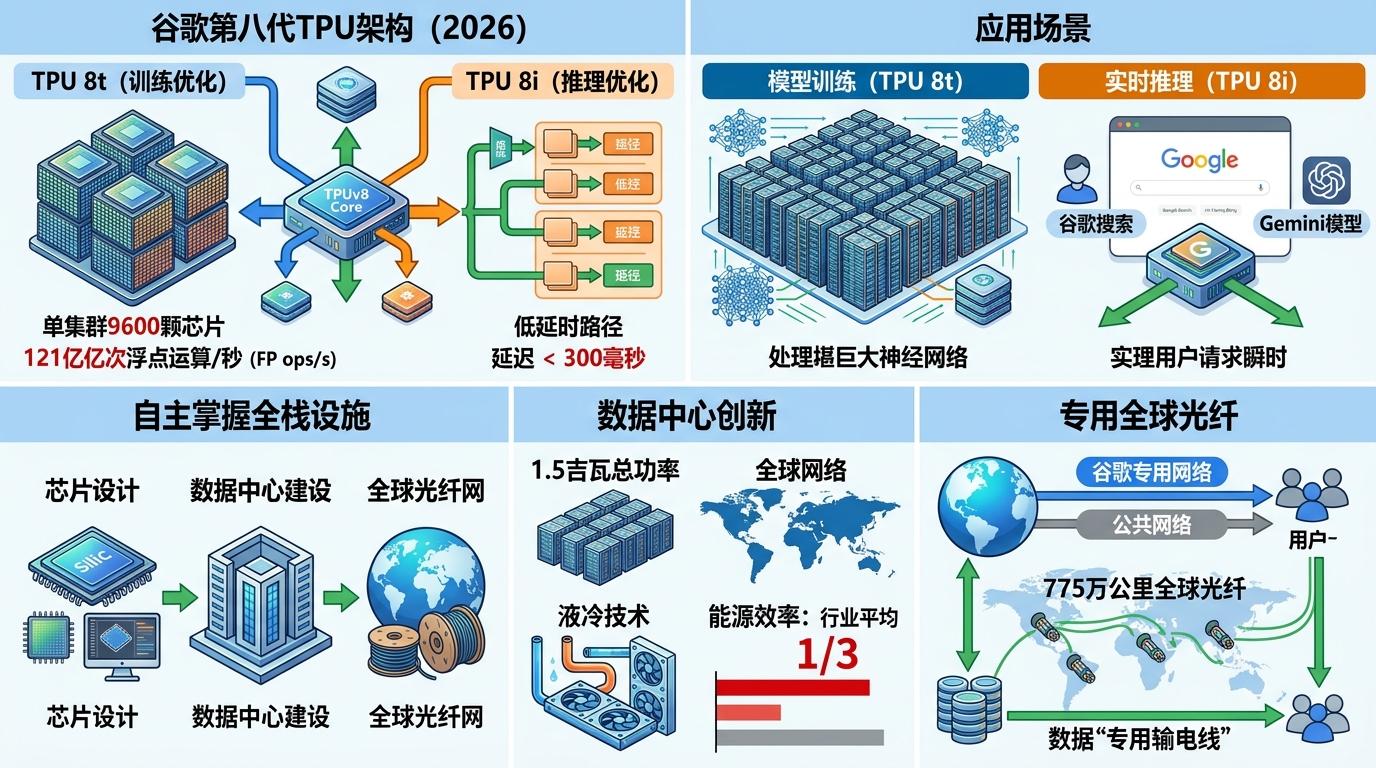
到2026年的第八代TPU,谷歌已经把这套逻辑玩到了极致:TPU 8t专为训练设计,单集群能塞下9600颗芯片,算力相当于121亿亿次浮点运算/秒;TPU 8i则盯着推理优化,把延迟压到300毫秒内,支撑着谷歌搜索、Gemini模型等10亿级用户的实时请求。更关键的是,谷歌把芯片、数据中心、光纤网攥在自己手里:它在全球建了1.5吉瓦功率的数据中心网络,用液冷技术把能源效率压到行业平均的1/3,还铺了775万公里的全球光纤,让数据能绕开公共网络,在自己的“专用输电线”里跑。
这种垂直整合的威力,在财报上一目了然:谷歌云收入增速68%,搜索业务靠AI增强再涨19%,而竞争对手的云业务却因为算力分流陷入增长瓶颈。
谷歌对速度的执念,早在上个搜索时代就刻进了基因。2009年拉里·佩奇主导的“Speed Matters”研究里有个扎心的数字:搜索结果慢400毫秒,用户使用量就会降0.5%——在谷歌的规模里,这就是每年几十亿美元的损失。到了AI时代,这个数字的权重翻了几倍:一次AI聊天的算力消耗是搜索的几十倍,延迟超过1秒,用户跳出率就会飙升90%。
这也是为什么科技巨头们在基建上砸下万亿级的投入:微软把云业务的部分算力转向自家AI工具,导致增长放缓;OpenAI因为算力不足,不得不砍掉部分新项目;Anthropic干脆直接向谷歌采购百万级TPU算力。而谷歌的提前布局,让它既能喂饱内部的Gemini模型,又能把富余的算力卖给客户,形成“算力→AI产品→更多算力投入”的飞轮。
但这场竞速也埋下了隐忧。全球数据中心的电力消耗已经占到全球的1.5%,谷歌的数据中心每年要耗掉相当于50万个家庭的电量,而且还在快速增长。为了维持算力优势,谷歌一边抢着和能源公司签可再生能源协议,一边开始测试小型核反应堆——当AI的算力需求以指数级增长,地球的能源供给,正在成为下一个看不见的瓶颈。
当谷歌、微软们在超级数据中心里较劲时,全球的算力格局正在悄悄分化。美国靠着70%的高端AI算力和4700亿美元的累计投资,牢牢占据第一梯队;欧洲靠着EuroHPC网络试图摆脱依赖;而中东、东南亚等地区则在疯狂砸钱建数据中心——沙特单是引入谷歌云就花了数十亿美元。
但算力的集中也正在制造新的数字鸿沟:新兴经济体拥有50%的互联网用户,却只占不到10%的数据中心容量,本地企业要么依赖海外算力,要么只能用性能受限的小型模型。更现实的是,AI基建的门槛正在变得越来越高:建一个超级数据中心需要上百亿美元,还要解决电力、土地、供应链等一堆问题,小公司连入场券都拿不到。
这也让“算力普惠”成了新的命题。谷歌把TPU通过云平台开放给开发者,微软推出AI即服务模式,试图让中小企业也能用上高端算力。但本质上,这更像是巨头们在自己的护城河上开了一扇小门——真正的普惠,可能要等专用小型AI模型、边缘计算这些技术成熟,让算力能从云端下沉到更多角落。
当我们谈论AI的未来时,总习惯盯着模型的参数、聊天的流畅度,却常常忽略了那些藏在地下的光纤、轰鸣的服务器、发烫的芯片——正是这些看不见的基建,决定了AI能跑多快、能走多远。谷歌的股价涨幅,不过是给“算力即命运”这句话盖了个章:在AI时代,算法是引擎,而算力就是燃料和公路。
算力决定AI的边界,基建定义时代的格局。当我们为每一次AI的新奇体验惊叹时,别忘了,它的背后是一场关于能源、技术和资本的全球竞速,而这场竞速的终点,可能就是未来世界的数字版图。