对抗知识焦虑,从看懂这条开始
App 下载
填数字的学问:越高阶的算法未必越准确
数值计算|离散数据点|误差分析|插值算法|应用数学|数理基础
对抗知识焦虑,从看懂这条开始
App 下载数值计算|离散数据点|误差分析|插值算法|应用数学|数理基础
1960年代的实验室里,堆满了砖头厚的函数表——天文学家查行星轨道,工程师算机械应力,都得对着密密麻麻的数字,用直尺在坐标纸上描线估数。这种靠手算填补数字间隙的工作,如今早被计算机接了过去,但背后的逻辑却没变:从已知的离散数据点,估算出中间未知点的数值,这就是插值(Interpolation)。
你或许会想,用越多的已知点、越高阶的算法,结果肯定越准?但事实恰恰相反:当年有人用29个点算π对应的函数值,误差反而比只用4个点的三次插值大了几百倍。这到底是为什么?
要理解插值的误差,得先把它拆成两部分——你可以把插值想象成用积木拼一张完整的地图:一部分误差是积木本身的大小决定的,另一部分是积木拼接时的缝隙被放大导致的。
第一部分是截断误差,对应公式里的 (c h^{n+1}):(h) 是相邻两个已知点的间距,(n) 是插值的阶数,(c) 由函数的光滑程度决定。简单说,用的点越多((h) 越小)、阶数越高((n) 越大),这部分误差理论上会快速缩小——就像用越小的积木,越能拼出精细的细节。
第二部分是数据误差放大,对应公式里的 (λδ):(δ) 是已知数据本身的精度误差,比如函数表上的数字只精确到了小数点后15位;(λ) 是误差放大系数,它会随着阶数 (n) 呈指数增长——就像你拼接积木时,每多一块,缝隙的错位就会被放大几倍,到最后整个地图都歪了。
这两部分误差此消彼长:阶数太低,截断误差太大;阶数太高,数据误差被放大到失控。
插值的终极目标,是找到那个刚好让截断误差等于数据误差的阶数——再往上加阶数,不仅不会更准,反而会帮倒忙。
拿自然对数表举例:当已知点的间距是0.001时,线性插值(1阶)的截断误差约为 (10^{-6}),但表格本身的精度是 (10^{-15}),这时候提升阶数还能明显缩小误差。但到了4阶插值,截断误差已经降到了 (10^{-16}),几乎和数据本身的精度持平,再升到5阶,误差反而跳到了 (10^{-8})——这就是放大系数 (λ) 开始起作用了。
再看贝塞尔函数表:因为已知点的间距宽到0.1,数据本身的精度是15位,这时候得用到11阶插值,才能让截断误差降到能接受的程度。要是换成线性插值,误差会大到根本没法用。
更麻烦的是**龙格现象**:当你用等间距的点做高阶插值时,多项式会在区间的两端剧烈振荡,就像你拼地图时,边缘的积木突然翘了起来。当年有人用29个等间距点算π的函数值,就是因为触发了龙格现象,误差直接爆炸。
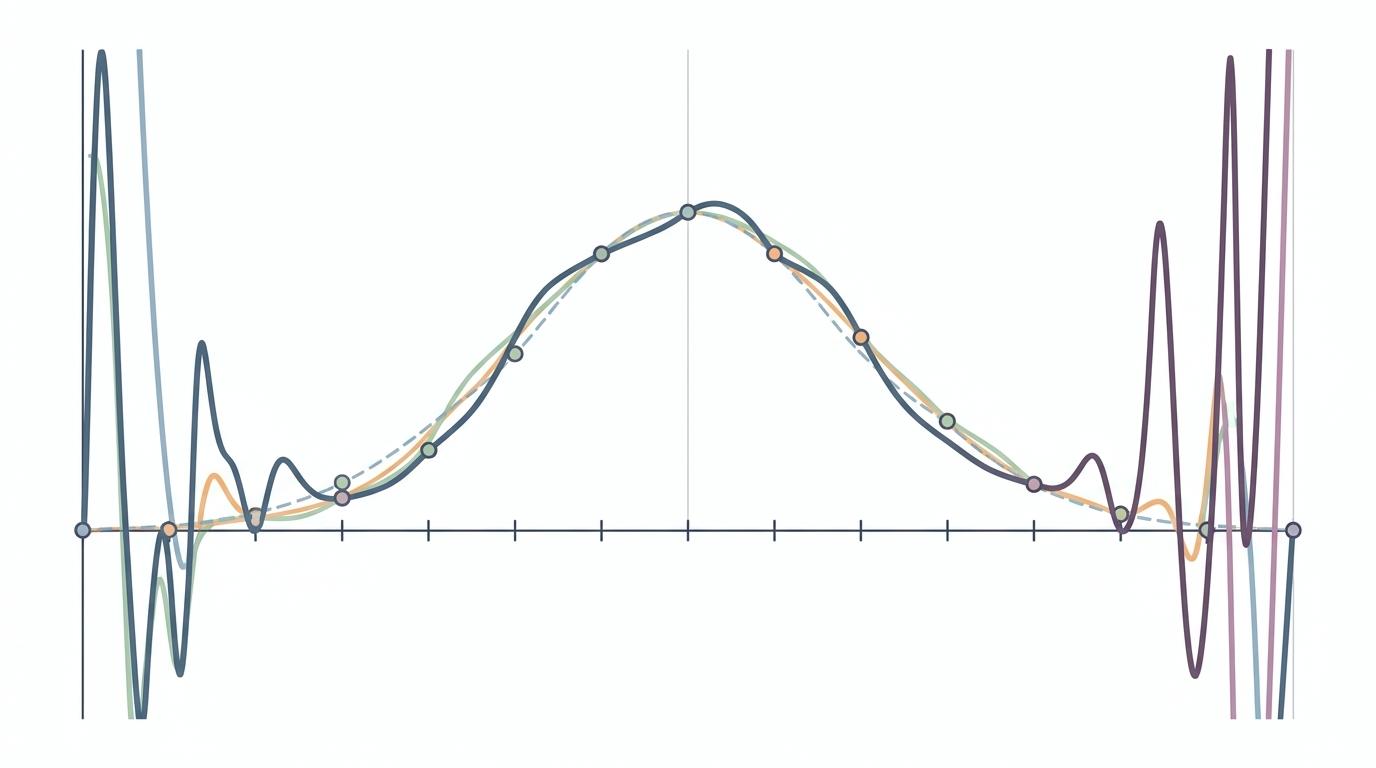
当然,你可以用切比雪夫节点来缓解龙格现象——这种节点在区间两端更密集,能把放大系数 (λ) 的增长从指数级降到对数级。但现实中,我们用的函数表几乎都是等间距的,这种理论上的最优解,在实际应用中根本派不上用场。
如今没人再抱着函数表算了,但插值算法反而无处不在:手机放大照片时的像素填充,自动驾驶里的路径平滑,甚至AI模型的潜空间补全,本质上都是插值。
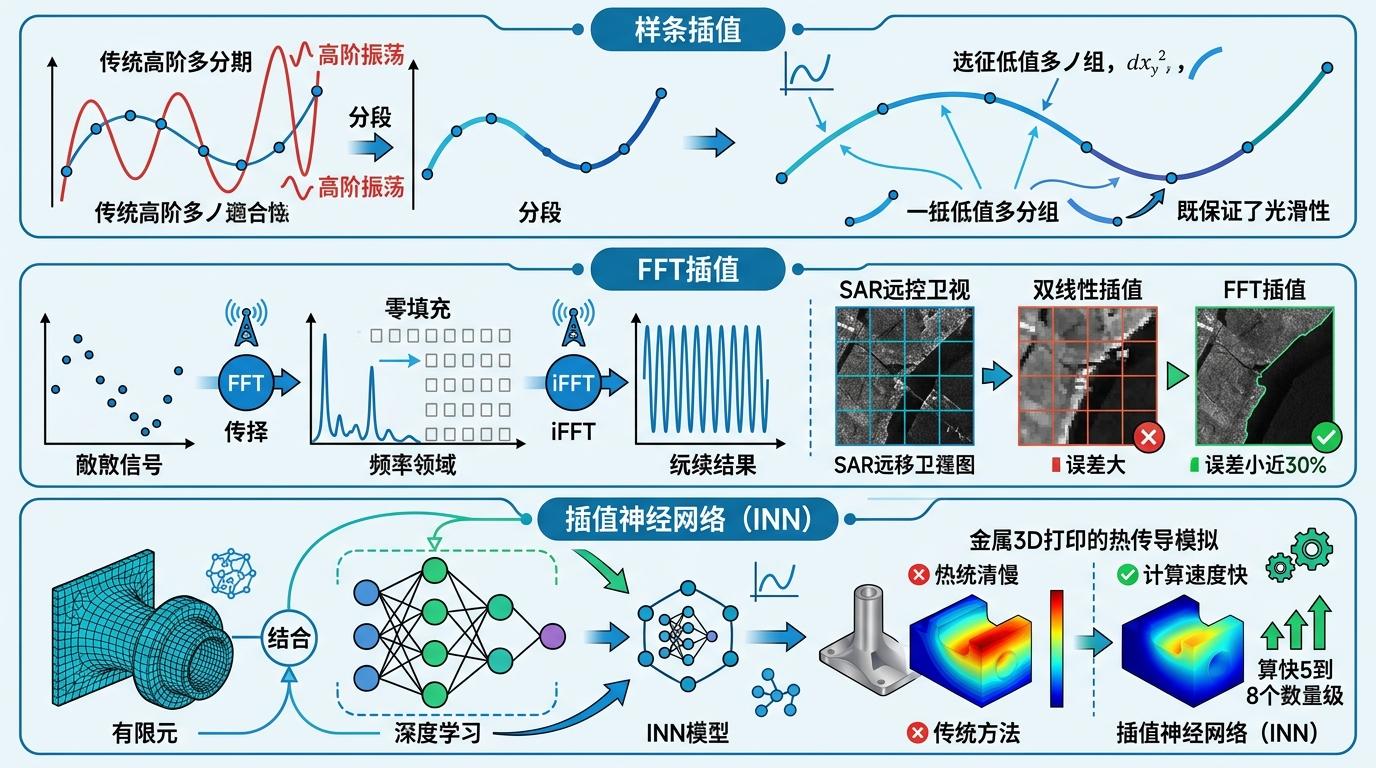
现代的插值算法早已跳出了多项式的框架:样条插值用分段的低阶多项式拼接,既保证了光滑性,又避免了高阶振荡;FFT插值通过频域的零填充实现信号重构,在SAR遥感图像的精度验证中,比双线性插值的误差小了近30%;就连最新的插值神经网络(INN),也是把有限元的插值思想和深度学习结合,在金属3D打印的热传导模拟中,计算速度比传统方法快了5到8个数量级。
但不管算法怎么变,核心逻辑还是没变:你得在精度和稳定性之间找平衡。就像现在的AI模型,参数越多不一定越准,关键是要摸到数据本身的精度天花板——再往上,就是过拟合的陷阱。
费曼说过,任何事深挖下去都很有趣。没人会想到,当年为了填函数表间隙的小技巧,背后藏着如此精妙的误差平衡逻辑。它像一面镜子,照出了人类认知的边界:我们永远没法超越数据本身的精度,就像用积木拼不出比积木本身更精细的图案。
精度的本质,是与误差的和解。 无论是当年手算函数表的科学家,还是现在训练AI的工程师,我们一直在做的,不过是在已知的边界里,找到那个刚刚好的平衡点——不多,也不少。