对抗知识焦虑,从看懂这条开始
App 下载
并行生成追上自回归,靠的是AI学会自我检查
参数效率|内省一致性|自我检查机制|扩散语言模型|I-DLM模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载参数效率|内省一致性|自我检查机制|扩散语言模型|I-DLM模型|大语言模型|人工智能
当你用AI写代码或解数学题时,可能从未想过:那些看似流畅的文字,背后是模型一个词一个词“挤”出来的——这就是自回归模型的死规矩,必须按顺序生成,快不起来。后来人们发明了扩散语言模型,能一次性蹦出一串词,速度直接翻几倍,可写出来的东西却常犯低级错误:上句说“1+1=2”,下句就推导“所以3-1=3”。直到2026年4月,一支跨机构团队推出的I-DLM模型,第一次让并行生成的AI,写出了和同规模自回归模型一样靠谱的内容,甚至用一半参数赢了更大的模型。这一切的核心,居然是让AI学会了一件人类早就会的事:自我检查。
你可以把自回归模型想象成一个写作文的学生:每写一句话,都会回头读一遍前文,确保逻辑连贯,不会写出“我今天去了公园,昨天吃了火锅”这种病句——这种“写完就检查”的本能,就是内省一致性。它靠两个机制实现:一是因果掩码,让模型只能看到已经写出来的内容,绝不能“偷看”还没生成的部分;二是logit偏移,相当于给模型加了个“逻辑校正器”,让它更倾向于生成符合前文的内容。
但扩散模型就像一个急着交卷的学生:它不管上下文,一次性把所有空填满,写完也不检查。它只学会了“从混乱里整理出通顺的句子”,却没学会“判断自己写的句子对不对”。数据最能说明问题:传统扩散模型的内省接受率只有0.699,意思是它自己写的内容,有近30%连自己都不认可;而I-DLM的内省接受率达到了0.984,几乎完全认可自己的输出。
这就是关键差距:自回归模型的生成和检查是同步的,而扩散模型只负责生成,把检查这步给丢了。
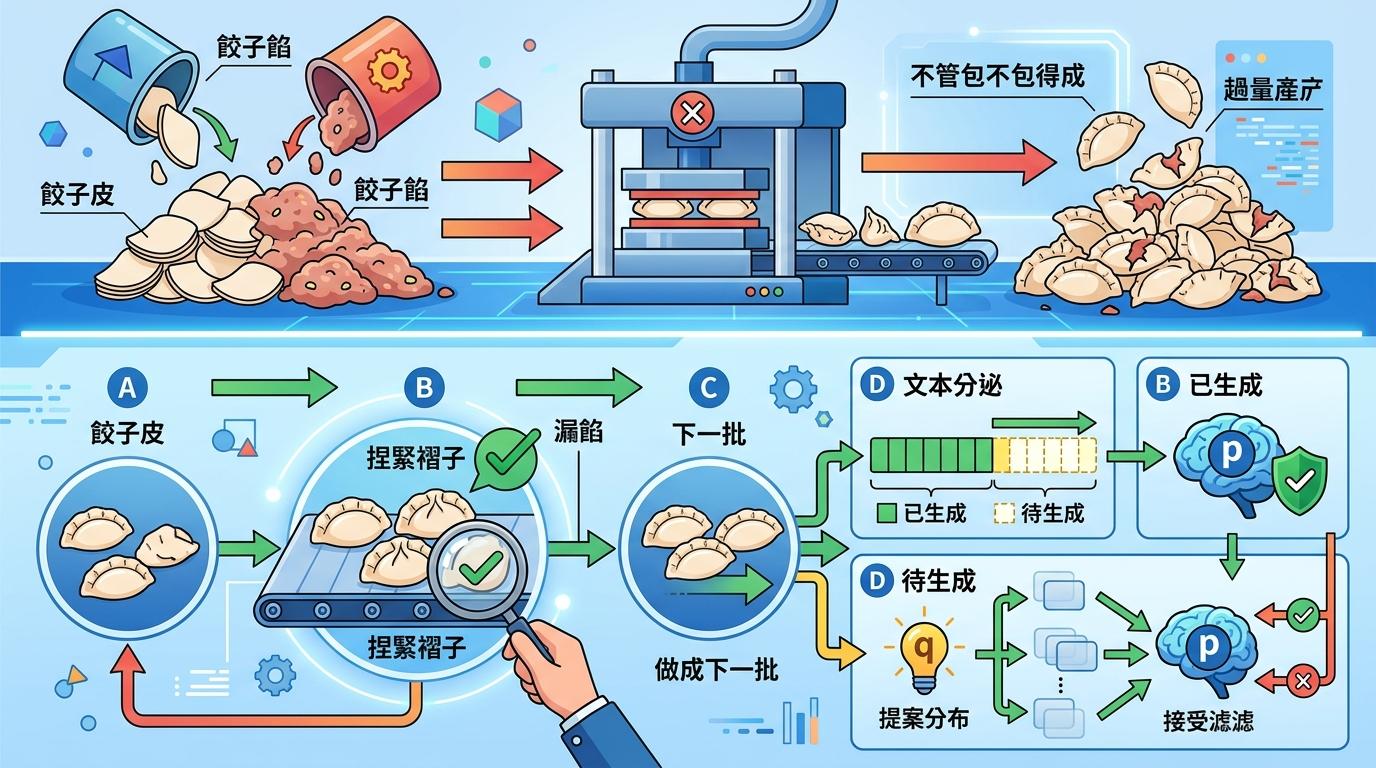
I-DLM解决问题的核心,是内省跨步解码(ISD)——简单说,就是让模型在一次计算里,同时做两件事:生成新内容,检查旧内容。
你可以把这个过程类比成包饺子:以前的扩散模型是把所有饺子皮和馅一次性堆出来,不管包不包得成;而ISD是包几个饺子,就立刻捏紧褶子检查有没有漏馅,没问题了再继续包下一批。具体到技术上,模型会把文本分成“已生成”和“待生成”两块:对已生成的部分,用模型的“认知”(锚定分布p)去验证;对待生成的部分,先提出候选内容(分布q),再用p/q接受准则判断:如果候选内容符合模型的认知,就保留,否则就重新生成。
这种机制带来了两个质变:一是质量追上了自回归模型,I-DLM-8B在15个基准测试中第一次和同规模自回归模型打平;二是速度优势彻底发挥,在高并发场景下,吞吐量是传统模型的2.9-4.1倍。更绝的是,它用了门控LoRA技术,能实现“位对位无损加速”——就像把文件压缩后再解压,内容完全不变,但传输速度快了好几倍。
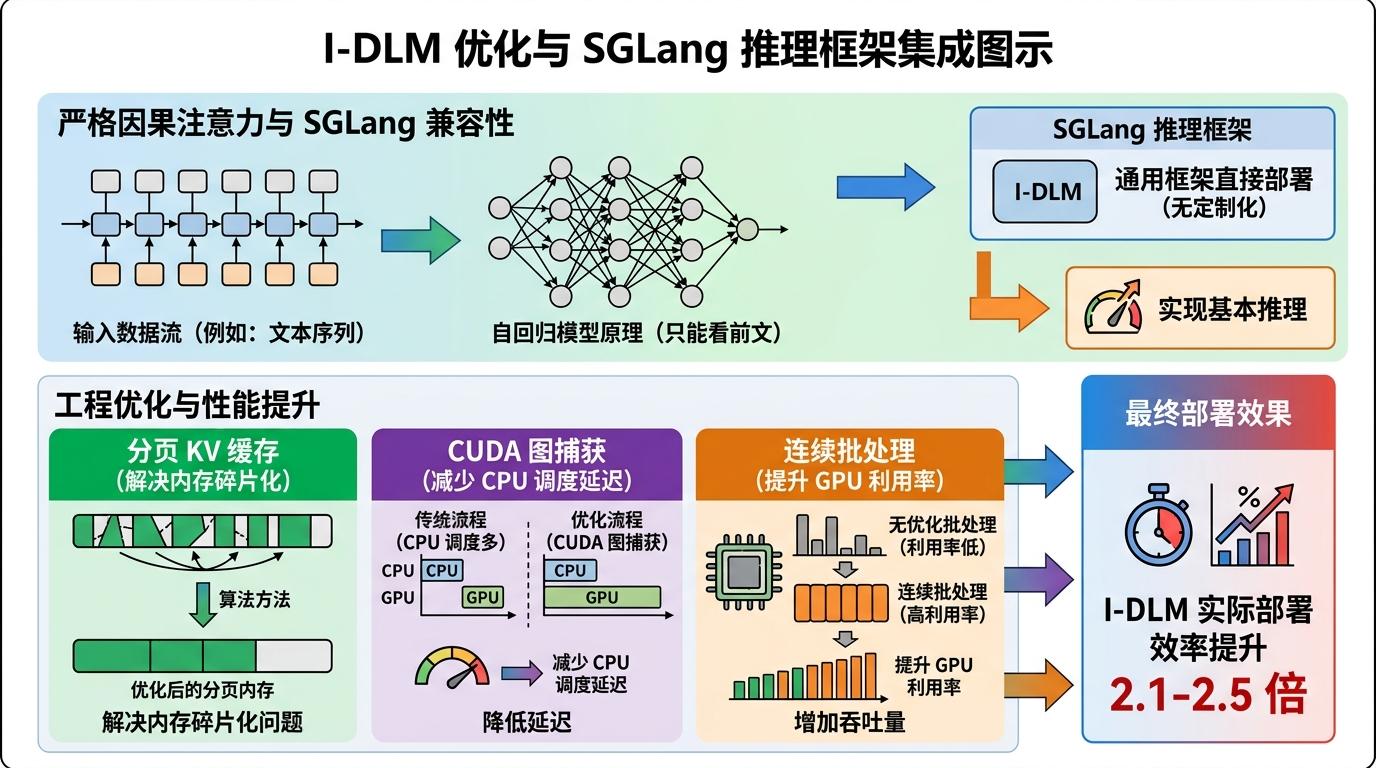
很多AI技术看起来厉害,但落地时要推翻整个现有系统,企业根本不敢用。I-DLM的聪明之处,在于它完全兼容自回归模型的基础设施。
它用了严格因果注意力——就是自回归模型那套“只能看前文”的规则,所以能直接塞进SGLang这类成熟的推理框架里,不用做任何定制化改造。研究团队还做了一系列工程优化:用分页KV缓存解决内存碎片化问题,用CUDA图捕获减少CPU调度的延迟,用连续批处理提升GPU的利用率。这些优化加起来,让I-DLM的实际部署效率又提升了2.1-2.5倍。
最能体现它实力的是对比数据:I-DLM-8B只用80亿参数,就在AIME-24数学推理任务上比160亿参数的LLaDA-2.1-mini高了26分,在LiveCodeBench-v6代码任务上高了15分——相当于用一半的“脑子”,干成了甚至超过了两倍参数模型的事。

从自回归模型的“慢而准”,到扩散模型的“快而乱”,再到I-DLM的“又快又准”,AI生成技术的进化,本质上是在补全人类早就具备的能力:一边前进,一边回头看。
这背后藏着一个更重要的信号:AI的进化不再只是堆参数、算更多数据,而是开始模仿人类的思考逻辑——不是一股脑往前冲,而是时不时停下来,检查自己的脚步。
生成的速度不重要,对自己的输出负责才重要。 这句话不仅适用于AI,也适用于每一个在信息洪流里赶路的人。