对抗知识焦虑,从看懂这条开始
App 下载
AI写代码速度翻5倍,我们靠验收标准守住质量
开发团队|PR合并量|自动化代码审核|代码验收标准|AI编码工具|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载开发团队|PR合并量|自动化代码审核|代码验收标准|AI编码工具|AI产业应用|人工智能
凌晨三点,程序员小李打开电脑,发现AI代理已经自动生成并提交了5个代码PR——这要是换做以前,他得熬两个通宵才能写完。但盯着屏幕上密密麻麻的代码,他突然慌了:这些代码真的符合业务需求吗?会不会藏着没被发现的bug?
2026年的今天,像小李这样的场景正在全球开发团队上演。AI编码工具让PR合并量从每周10个暴涨到50个,但随之而来的是96%的开发者都不完全信任AI生成的代码。传统人工审核已经追不上AI的速度,而AI自己测自己写的代码,不过是在做“自我表扬”。我们到底该怎么信任这些“看不见创作者”的代码?
解决问题的答案,藏在一个被很多团队忽略的环节里——验收标准驱动开发(Acceptance Criteria Driven Development),简单说就是先写清楚“代码要做成什么样”,再让AI去写代码。
这有点像餐厅点菜:你不能只说“我要吃辣的”,得明确说“要一份麻婆豆腐,麻辣度3星,豆腐要嫩,不能有焦糊味”。AI就是那个厨师,验收标准就是你的点菜单,写得越具体,AI做出来的东西就越符合你的预期。比如做登录功能,不能只说“实现登录”,得拆成:
这些标准必须是“可验证”的——要么符合,要么不符合,没有模糊地带。早在AI编码普及之前,验收标准就是敏捷开发的核心工具,但直到AI把代码量推到新高度,它的价值才真正凸显:它把人类的业务判断,变成了AI和测试工具都能看懂的“硬指标”。
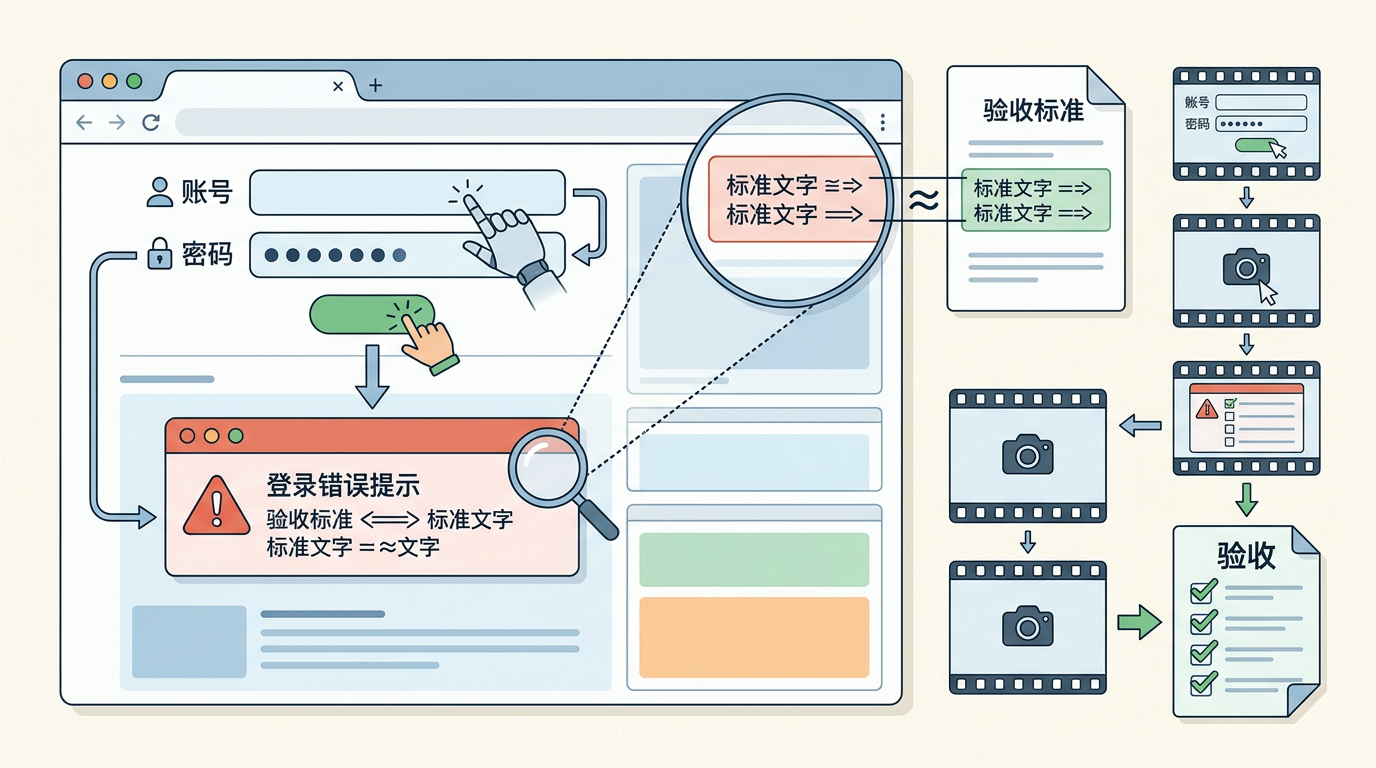
有了验收标准,接下来需要一个“自动批改作业”的老师——这就是Playwright这类自动化测试工具。
你可以把Playwright想象成一个不知疲倦的测试员,它能模拟真实用户操作浏览器:输入账号密码、点击按钮、截图保存结果,然后对照验收标准一条一条检查。比如测试登录错误提示,它会故意输错密码,然后截图对比页面上的文字是不是和验收标准里写的一字不差。
整个流程分成四步:第一步是“预检”,用脚本检查开发环境是否正常,避免白忙活;第二步是“规划”,让AI分析验收标准和代码,找出需要测试的关键点;第三步是“并行测试”,同时启动多个“虚拟测试员”,分头验证每一条标准,把原本需要几小时的测试压缩到几分钟;最后一步是“AI判定”,把所有测试结果汇总,给每条标准打上“通过”“失败”或“需要人工复核”的标签。
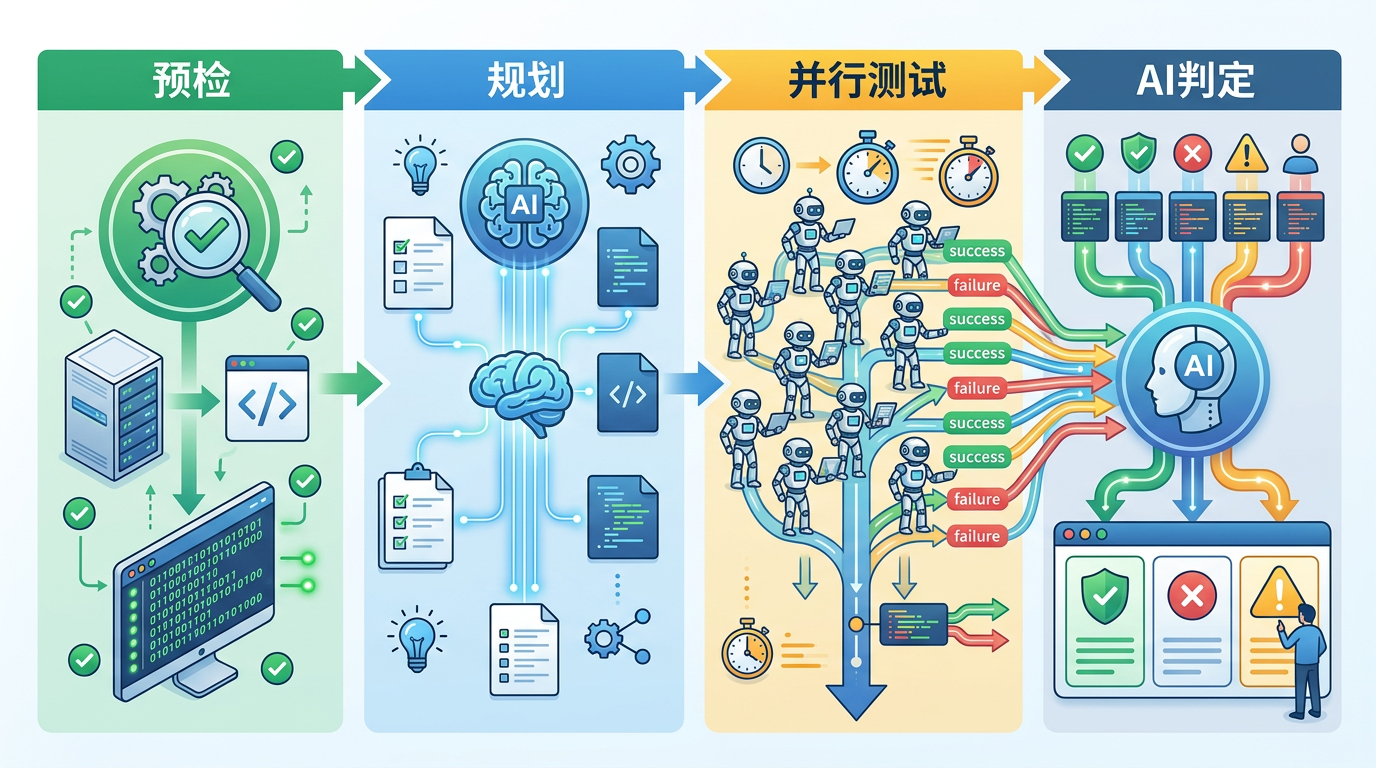
这套流程最聪明的地方在于,开发者不用再去看成千上万行的代码差异,只需要聚焦那些“失败”的项——就像老师改卷只看错题,效率直接拉满。
不过这套机制也不是万能的。如果验收标准本身写错了,比如把“连续输错5次锁定”写成了“3次”,那AI和测试工具只会坚定地执行错误指令——这就是所谓的“语义鸿沟”,AI听不懂你没写出来的真实需求。
更棘手的是安全问题。2025年的一份报告显示,AI生成的代码里,安全漏洞数量是人类代码的2.74倍,其中45%包含OWASP Top 10高危漏洞。自动化测试能找出功能错误,但藏在代码逻辑里的安全隐患,比如硬编码的密钥、未验证的用户输入,还得靠人类开发者的经验去发现。
这也是为什么我一直强调:AI是助手,不是替代者。开发者的角色正在从“代码编写者”变成“验证设计师”——你要学会怎么给AI提要求,怎么设计测试标准,怎么在AI的输出里挑出问题。就像导演不会自己去演每一个角色,但他要把控整个电影的方向和质量。
当AI的代码生成速度越来越快,我们真正要解决的不是“怎么写得更快”,而是“怎么信得过”。验收标准加自动化测试的组合,本质上是把人类的判断力,变成了一套可执行的规则体系——既给了AI明确的方向,也给了我们足够的安全感。
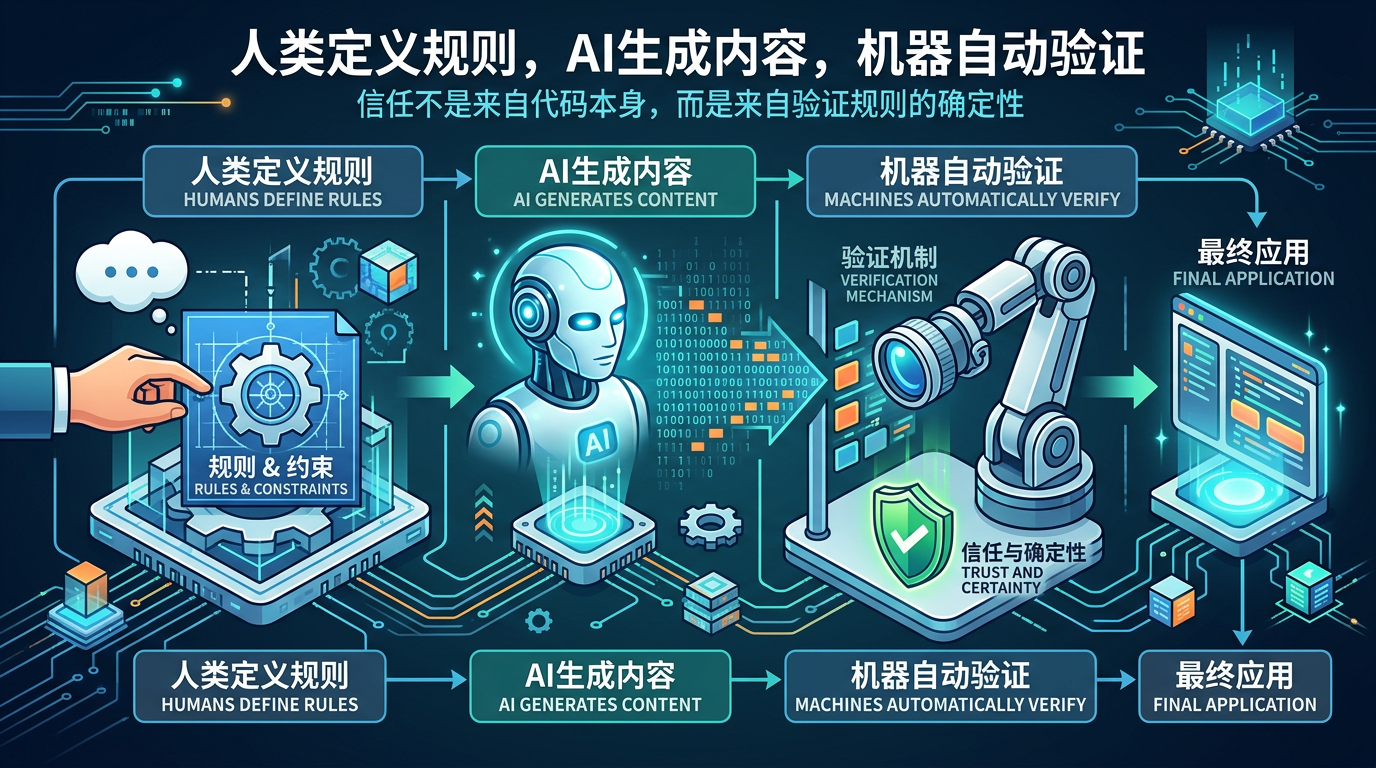
未来的开发场景里,可能不会有“纯人类写的代码”,也不会有“纯AI写的代码”,只会有“人类定义规则,AI生成内容,机器自动验证”的协同模式。信任不是来自代码本身,而是来自验证规则的确定性。
毕竟,在这个AI越来越聪明的时代,我们最该守住的,是对“正确”的定义权。