
10 天前
10 天前
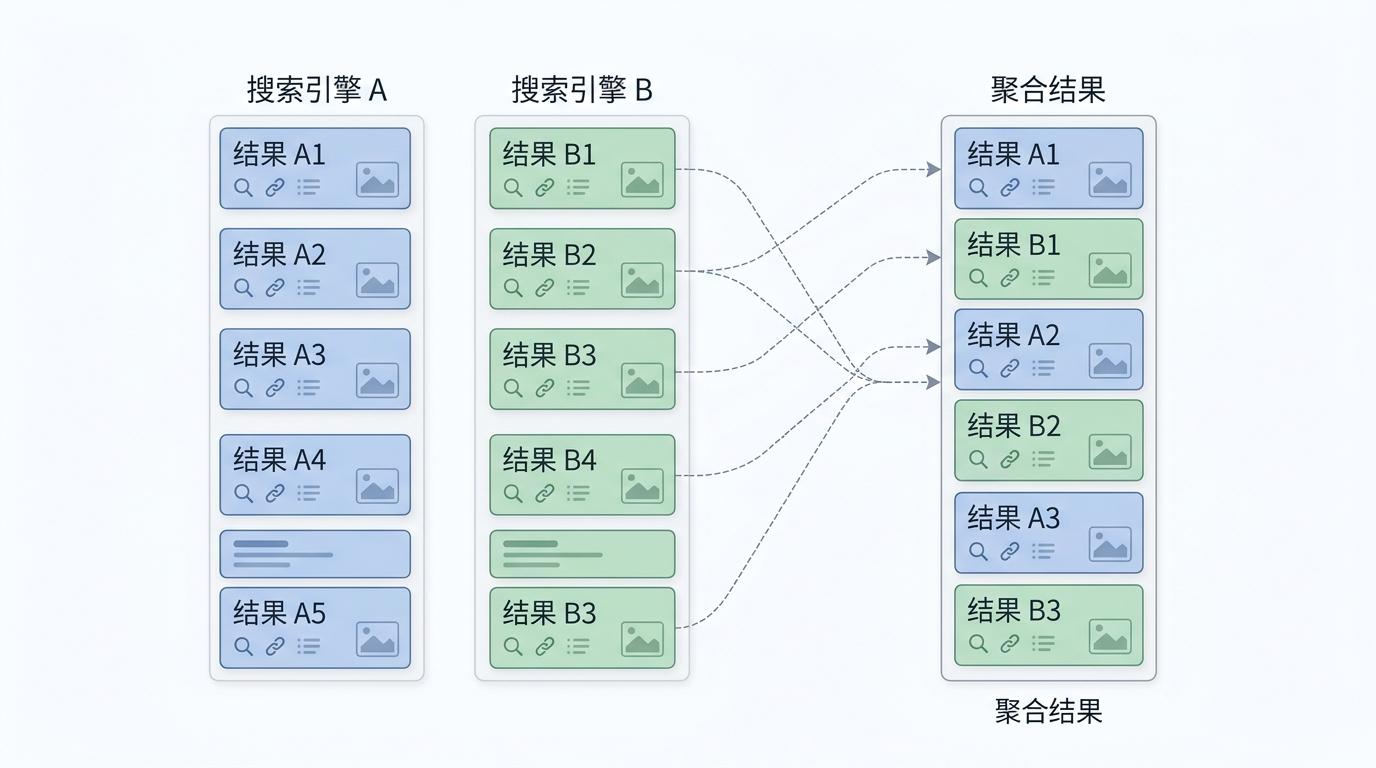
当你在搜索框敲下“可持续咖啡胶囊”,屏幕上跳出的10条结果,可能来自3个不同的搜索引擎。你以为是某个算法算出的最优答案,其实是一场精心编排的“结果交响乐”——没有一个搜索引擎能独自覆盖所有信息,也没有单一排序逻辑能满足所有需求。这就是多源聚合搜索:一个不生产内容的“指挥家”,协调多个独立引擎的结果,再用一套复杂算法把它们揉成你看到的列表。为什么要这么麻烦?因为单一引擎的偏见、盲区和过时数据,早就在悄悄限制你获取信息的边界。
你可以把多源聚合的过程想象成拼乐高:每个搜索引擎提供一堆带排序的积木,聚合系统要把它们拼成一个既整齐又好看的新模型。最基础的拼法是轮询合并——从第一个引擎拿第1条,第二个引擎拿第1条,再第一个拿第2条,第二个拿第2条,以此类推。这种方法简单公平,能保证每个引擎的结果都有曝光,但缺点也明显:完全不管内容质量,可能把无关结果硬塞进前排。
更聪明的拼法是**递归排名融合(RRF)**,这是当前行业的“标准指挥棒”。它的逻辑很简单:一个结果在越多引擎里排得越靠前,就越可能是用户真正需要的。具体来说,每个结果的最终得分是它在各个引擎中排名倒数的加权和——排名第1的结果得1/(60+1),排名第2的得1/(60+2),以此类推,最后把所有引擎的得分加起来。这里的60是个平滑参数,用来避免单个引擎的极端排名影响整体。
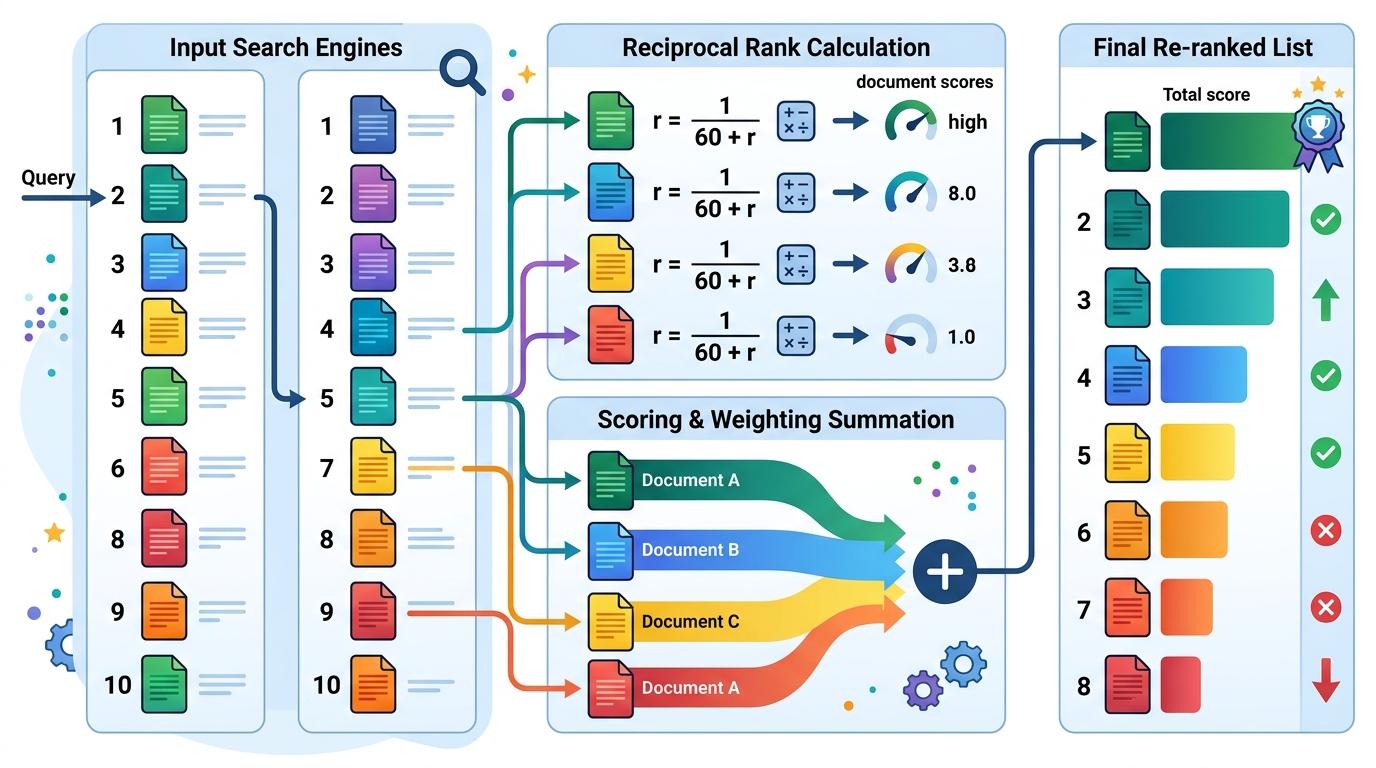
这个算法的妙处在于,它不需要统一不同引擎的评分体系——毕竟有的引擎用关键词匹配得分,有的用语义相似度,分数根本没法直接比。RRF只看排名,天然规避了这个问题,而且计算简单,抗干扰能力强,哪怕某个引擎出了故障,也不会毁掉整个结果列表。
多源聚合的终极目标是让搜索更“懂你”——比如你想搜“苹果”,系统能知道你要的是水果还是手机;你排斥某类网站,结果里就再也不会出现。但实现这个目标的过程,就像指挥一群各有脾气的乐手:每个搜索引擎的“乐器”不一样,有的支持精细的权重调整,有的只能简单过滤,有的甚至完全不接受个性化指令。
举个例子,你想提升教育类网站的排名,系统需要把你的偏好转换成每个引擎能理解的语言:有的引擎用“boost”参数,有的用标签权重,有的只能通过关键词过滤。如果遇到完全不支持个性化的引擎,系统只能先拿到它的结果,再手动在聚合阶段调整排名。这就像让一个只会弹C调的乐手,强行配合整首交响乐的降B调,只能靠后期剪辑来补救。
更麻烦的是延迟问题。为了保证结果全面,系统需要等所有引擎都返回结果才能聚合,最慢的那个引擎会拖慢整个过程。有的系统会设置阈值:如果首选引擎返回的结果少于5条,就自动调用备选引擎补充。但这个阈值设得太高,可能错过优质补充结果;设得太低,又会增加不必要的延迟。
早期的多源聚合只是简单的“结果拼接”,就把不同引擎的结果按顺序堆在一起。后来发展到“加权融合”,给更靠谱的引擎更高的权重。现在,聚合系统开始向“动态智能”进化——它会根据你的实时场景调整策略。
比如你在办公室用电脑搜“午餐推荐”,系统会优先调用本地生活服务引擎;你在地铁上用手机搜,就会侧重距离近、可外带的商家。有的系统甚至会结合你的日程、地理位置和历史行为,实时调整每个引擎的权重。这种“上下文感知”的聚合,已经不是简单的结果拼接,而是真正理解你的需求。
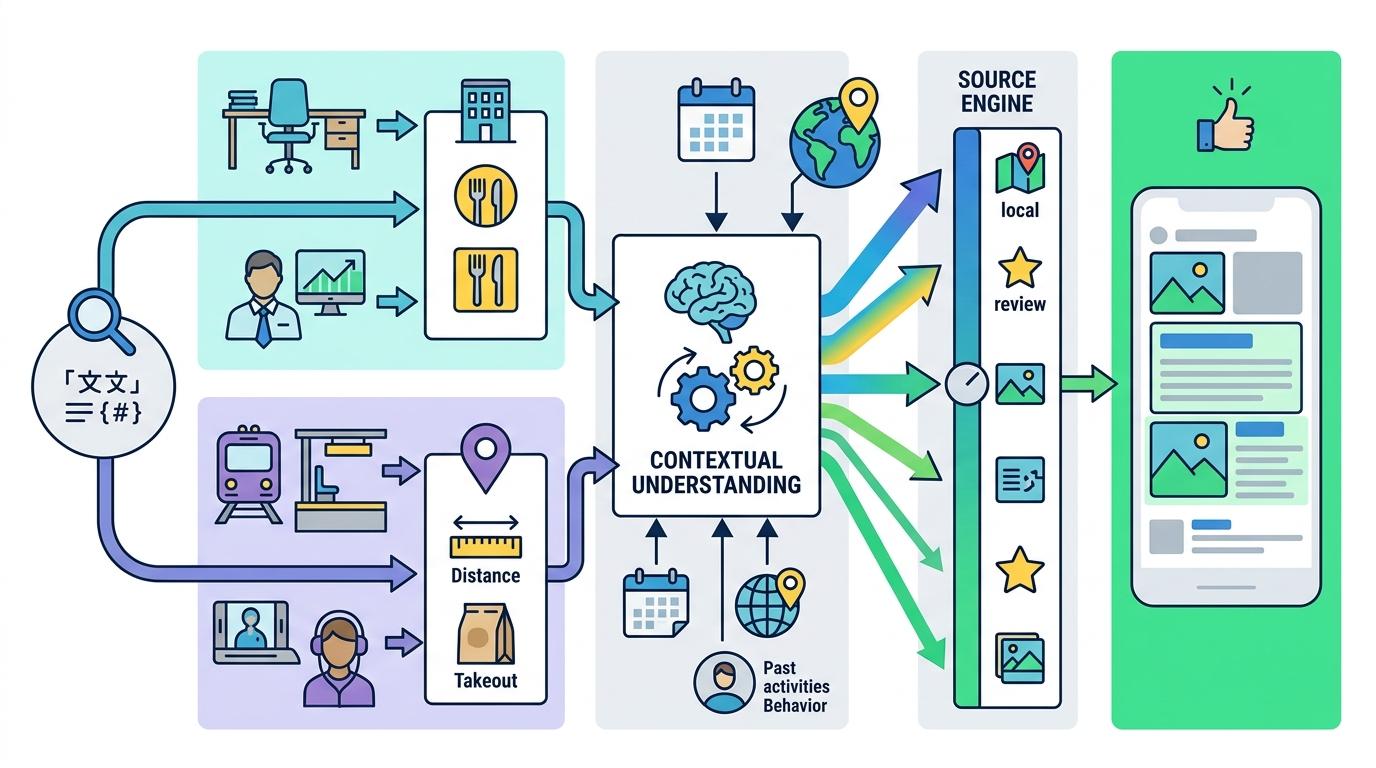
但这也带来了新的挑战:如何保证结果的公正性?当系统越来越懂你,会不会把你困在“信息茧房”里?比如你只看某类新闻,系统就只给你推这类内容,让你看不到相反的观点。这也是为什么现在的聚合系统开始强调“多样性”——哪怕某个结果相关性稍低,只要能带来新视角,也会给它留个位置。
你每天看到的搜索结果,从来不是“客观事实”的集合,而是多源聚合算法的产物——它平衡了相关性、多样性、个性化和效率,也在偏见与全面、速度与质量之间走钢丝。
多源聚合的本质,不是要取代单一搜索引擎,而是要弥补它们的不足。它让你能同时摸到不同引擎的“家底”,也让搜索结果不至于被某一种算法垄断。
搜索的未来,是多源的合唱,而非独奏。 当你下次盯着搜索结果列表时,不妨想想:这背后有多少个引擎在工作,又有多少个算法在为你协调出一场“信息交响乐”。
点击充电,成为大圆镜下一个视频选题!