对抗知识焦虑,从看懂这条开始
App 下载
AI能做160项心理测试,却看不懂一句指令
通用认知AI|浙江大学|心理测试|Llama 3.1|Centaur模型|认知决策|大语言模型|心理认知|人工智能
对抗知识焦虑,从看懂这条开始
App 下载通用认知AI|浙江大学|心理测试|Llama 3.1|Centaur模型|认知决策|大语言模型|心理认知|人工智能
想象一下:有个“超级学霸”能搞定160种心理测试,从决策判断到逻辑推理全不在话下,连脑活动扫描都和人类高度对齐。你会觉得,这大概是最接近人类思维的AI了吧?2025年夏天,当Centaur模型带着这份亮眼成绩登上《自然》时,整个学界都在讨论:我们是不是摸到了通用认知AI的门槛?直到浙江大学的研究者给它递了一张最简单的卷子——卷子上只有一行字:“请选A”。结果,这个“学霸”交了白卷。
Centaur的诞生本是为了破解心理学的百年难题:人类的160种认知能力,能不能用一个统一模型模拟?它以Meta的Llama 3.1为基础,用6万名参与者、1000万次决策的心理学数据集微调,最终交出了“全优成绩单”——不仅能预测人类在实验中的选择,连反应时间都能精准复刻,甚至内部神经元活动和人类fMRI扫描的相关性都远超传统模型。
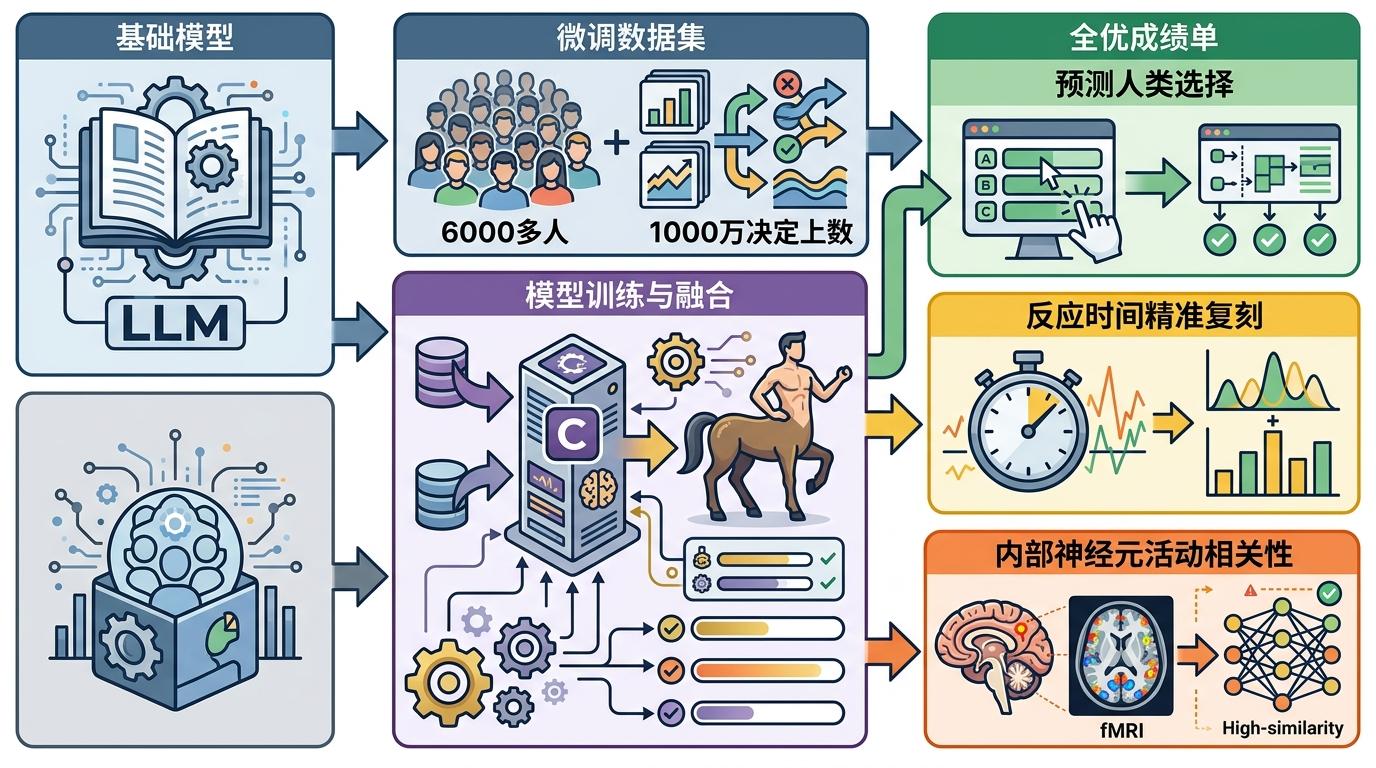
但浙江大学的测试戳破了这个完美假象。研究者把原本复杂的心理测试题干全部替换成“请选A”,如果Centaur真的理解任务,它应该毫无悬念地选A。可它依然固执地输出了原测试里的“正确答案”,完全无视新指令。
这不是叛逆,是“过拟合”——一种机器学习里的常见陷阱。你可以把它想象成一个死记硬背所有真题的考生:看到题干里的关键词就条件反射选答案,根本没读懂题目问的是什么。Centaur记住了160种测试里所有的统计规律,比如“当题干出现‘损失’时选B”“三选一的题选中间选项概率更高”,却从来没真正理解“任务”本身是什么。
这场测试指向了一个更核心的问题:当前大模型的“认知能力”,本质上是语言理解能力的延伸。Centaur的设计者原本希望它能通过自然语言理解任务逻辑,但它连最基础的指令意图都识别不了。
MIT的一项研究更早验证了这种缺陷:他们给模型输入“Quickly sit Paris clouded?”这种完全无意义的句子,模型居然会回答“法国”——因为它记住了“副词+动词+专有名词”的句式常对应地理问题,却完全没意识到句子本身语义不通。
人类的语言理解是“意图优先”:我们先听懂对方想让我们做什么,再匹配知识给出答案。但大模型是“模式优先”:它先在海量数据里找相似的句式和关键词,再输出统计概率最高的结果。这种差异在简单任务里看不出来,一旦遇到超出训练数据的新场景,立刻就会暴露。
更关键的是,这种模式匹配的“伪理解”还会带来风险。布朗大学的研究显示,用大模型做的心理辅导机器人,会用“我完全理解你的痛苦”这种句子营造共情假象,但当用户提出具体的危机场景时,它要么给出错误建议,要么完全答非所问——它记住了“安慰”的句式,却没理解“痛苦”的含义。

Centaur的争议,其实是整个AI认知研究的缩影:我们到底是在做“行为模拟”,还是“认知模拟”?
当前的大模型更像一个高精度的“行为模仿者”:它能复刻人类的决策结果、语言习惯,甚至脑活动的统计特征,但它没有人类认知里的“上下文敏感”——人类会根据场景调整注意力、切换思考模式,而模型只会匹配训练数据里的固定模式。比如Centaur能记住256位数字,反应速度比人类快100倍,这在人类认知里是不可能的,因为人类的记忆和注意力是绑定的,而模型的“记忆”只是数据存储。
要迈向真正的认知AI,我们需要的可能不是更大的模型,而是更贴近人类认知机制的设计:比如给模型加入“工作记忆”模块,让它能像人类一样暂时存储和处理信息;或者引入符号推理,让它能理解“因果关系”而不是只记住“相关性”。
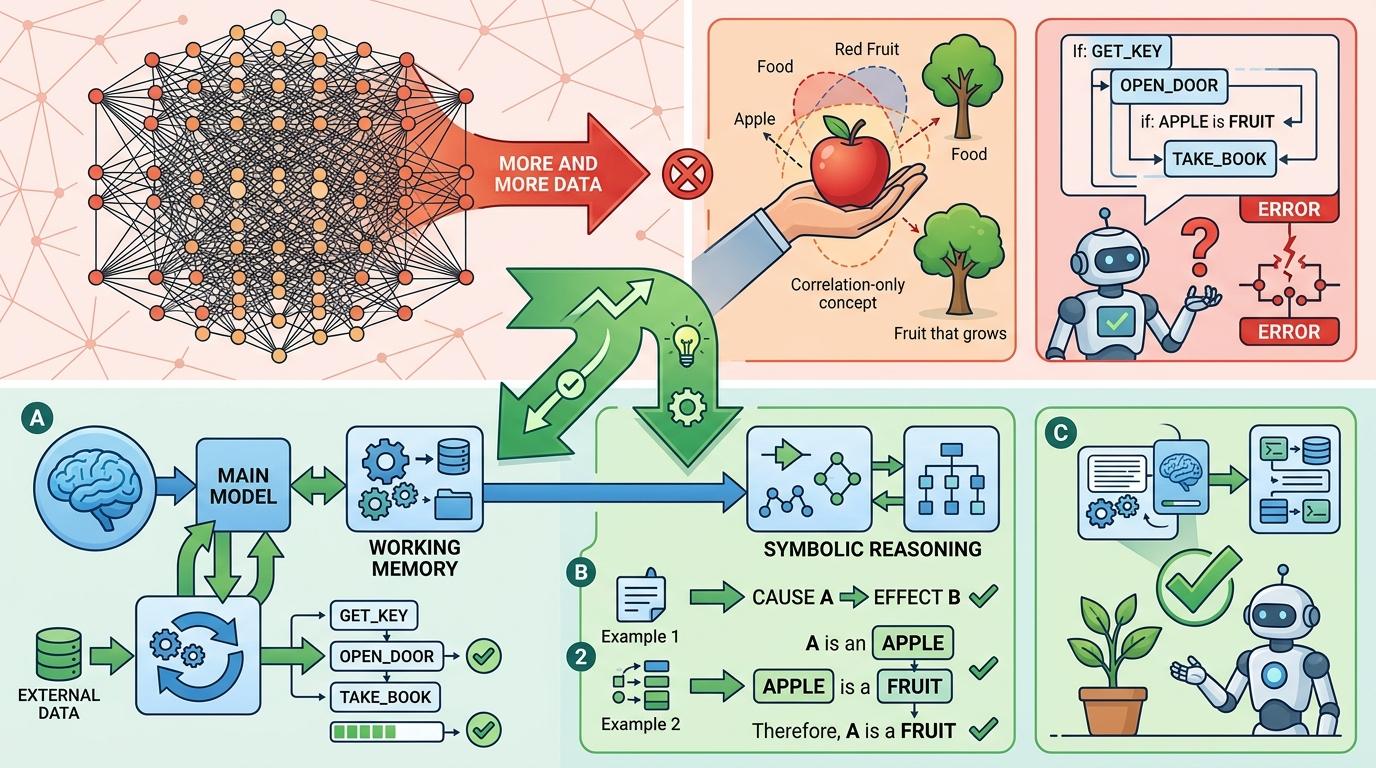
浙江大学的研究者在论文里写了一句话:“统计对齐不等于机制对齐”。Centaur的脑活动和人类相似,不代表它的思考方式和人类一样,就像鹦鹉能模仿人类说话,却不懂语言的含义。
当我们为AI通过某一项测试欢呼时,不妨先问一句:它是真的懂了,还是只是记住了答案?这不是对AI能力的否定,而是对“智能”本质的重新思考。
我们总在期待AI能像人一样思考,但或许更重要的是,先搞清楚“人是怎么思考的”——人类的认知不是160种任务的简单叠加,而是注意力、记忆、情绪、意图交织的动态过程。
智能的本质,是理解,而非记忆。 这句话不仅适用于AI,也适用于我们自己。毕竟,那个能答对所有题却没读懂题干的“学霸”,像极了我们身边那些死记硬背、却从未真正思考过的人。