对抗知识焦虑,从看懂这条开始
App 下载
AI写论文省时间,却造出4000条假引用
柳叶刀研究|生成式AI幻觉|学术论文|虚假引用|马克西姆·托帕兹|大语言模型|公共政策|社会人文|人工智能
对抗知识焦虑,从看懂这条开始
App 下载柳叶刀研究|生成式AI幻觉|学术论文|虚假引用|马克西姆·托帕兹|大语言模型|公共政策|社会人文|人工智能
哥伦比亚大学的护士AI研究者马克西姆·托帕兹曾有过一次社死经历:他用AI聊天机器人辅助修改一篇期刊社论,反复检查过引用准确性后提交,还是被编辑揪出了一条不存在的假引用。这件事让他意识到,自己的尴尬不是个例——如今越来越多学者收到引用提醒点开一看,发现对方引用的是一篇压根不存在的论文。2026年5月发表在《柳叶刀》上的研究给出了更惊人的数字:短短三年,学术论文中的虚假引用比例从每2828篇1篇,飙升到每277篇就有1篇。这背后,生成式AI的「幻觉」正在啃噬学术的根基。
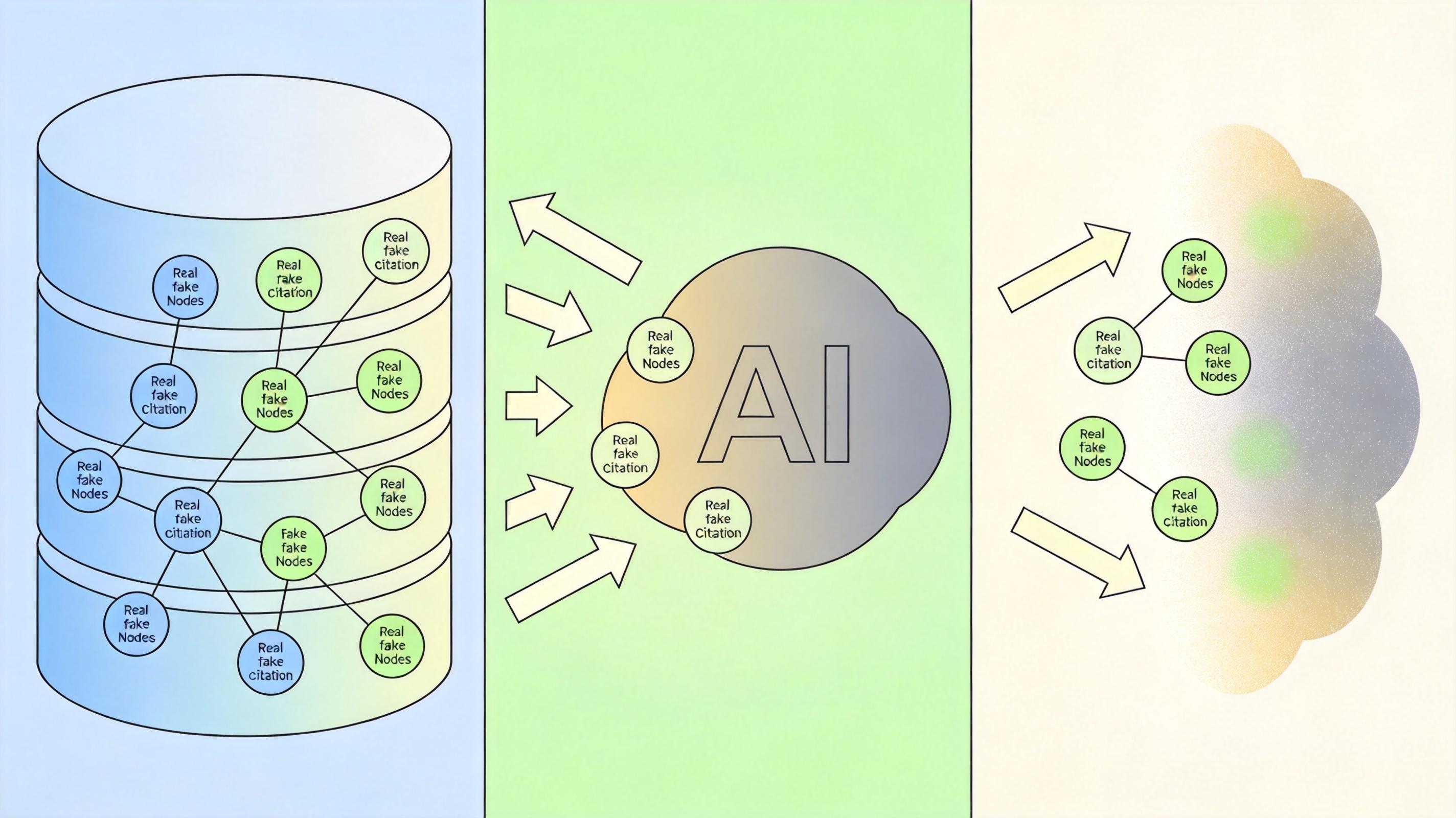
你可以把生成式AI想象成一个记性差但口才好的写手:它能精准模仿学术论文的措辞和引用格式,却没法像人类一样「查资料」——它的所有输出都是基于训练数据的概率预测,而非事实核查。比如ChatGPT-3.5生成的引用里,有55%是完全虚构的,哪怕升级到GPT-4,仍有18%的虚假率;而在医学领域,Google Bard生成的引用虚假率甚至高达91.4%。 这些假引用往往伪装得极具迷惑性:用真实的作者名字搭配虚构的论文标题,或是把不同论文的期刊、年份、卷号拼凑在一起,看起来格式标准、出处权威,连资深学者都可能被蒙混过关。更麻烦的是,AI生成的假引用会进入学术数据库,被后续论文引用,形成「假权威」的连锁反应——就像一颗扔进湖里的石子,涟漪会不断扩散,污染整个知识体系。
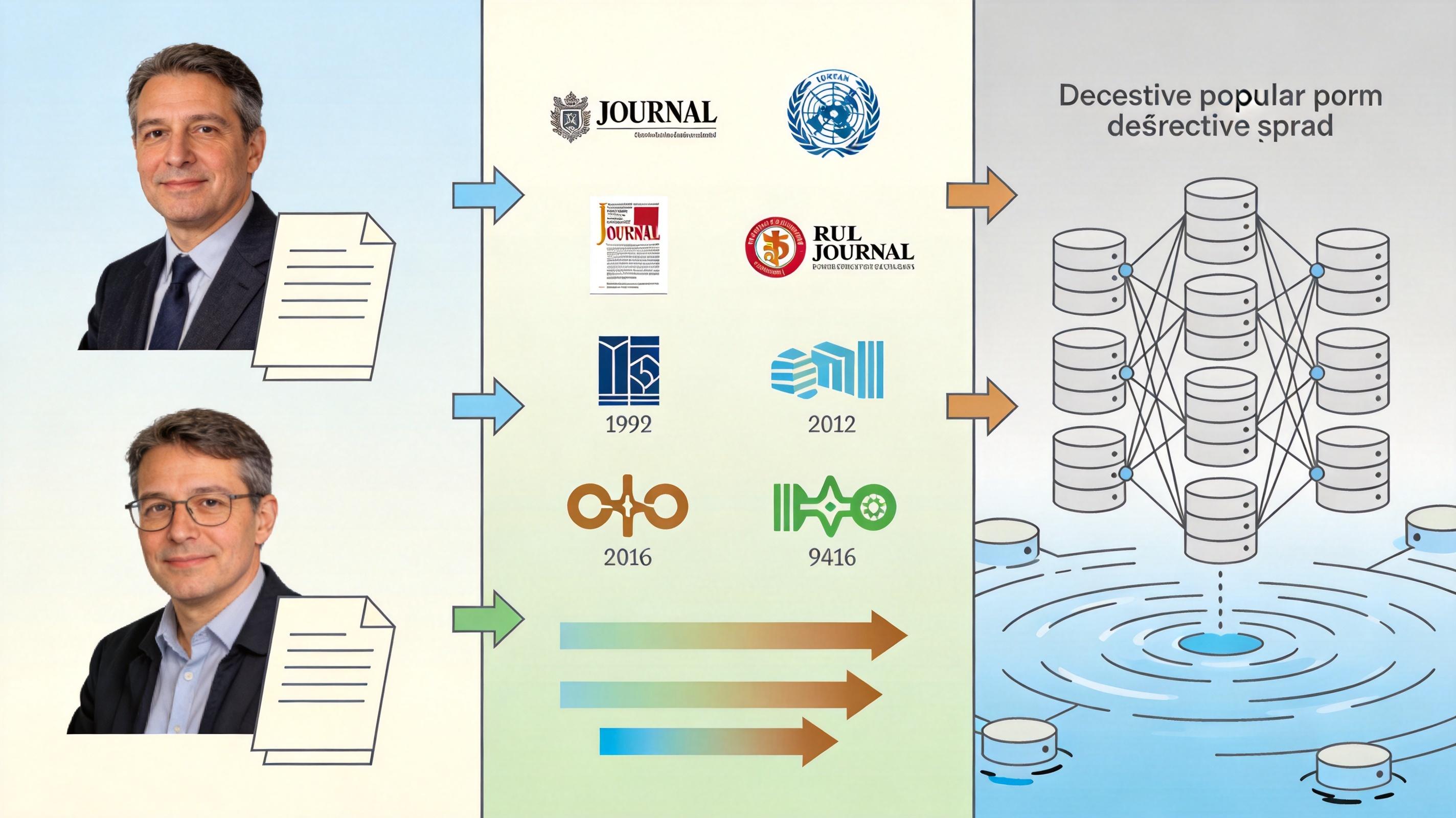
虚假引用的泛滥,不全是AI的锅。托帕兹团队分析了280万篇论文、9700万条引用后发现,超过三分之一的假引用来自两家大型开放获取出版商——这类期刊靠收取作者版面费盈利,审核资源有限,难以对每一条引用进行核实。 但更深层的原因藏在学术评价体系里。「发表或灭亡」的压力让不少研究者把引用当成了「凑数任务」:过去引用是对前人研究的深度对话,现在却成了用AI一键生成、填满参考文献栏的表面功夫。西北大学的研究诚信专家穆罕默德·侯赛尼说得直接:「这说明有人连半小时核对引用的时间都不想花,他们只想着快点发表——而这正是学术评价体系过度量化的恶果。」 更讽刺的是,假引用还可能形成恶性循环:AI从污染的学术数据库里学习,再生成更多假引用,最终导致「模型崩溃」——AI自己也分不清哪些是真研究,哪些是它编出来的。
面对假引用的冲击,不同期刊的应对方式拉开了差距。《Science》《新英格兰医学杂志》等顶级期刊已经用上了自动化引用核查工具:比如Scite.ai能自动交叉验证引用,显示文献是否被支持、质疑或撤回;Trinka Citation Checker则能直接识别「幻觉引用」。这些工具确实有效,《Science》的发言人表示,他们至今还没遇到过发表论文里出现假引用的情况。
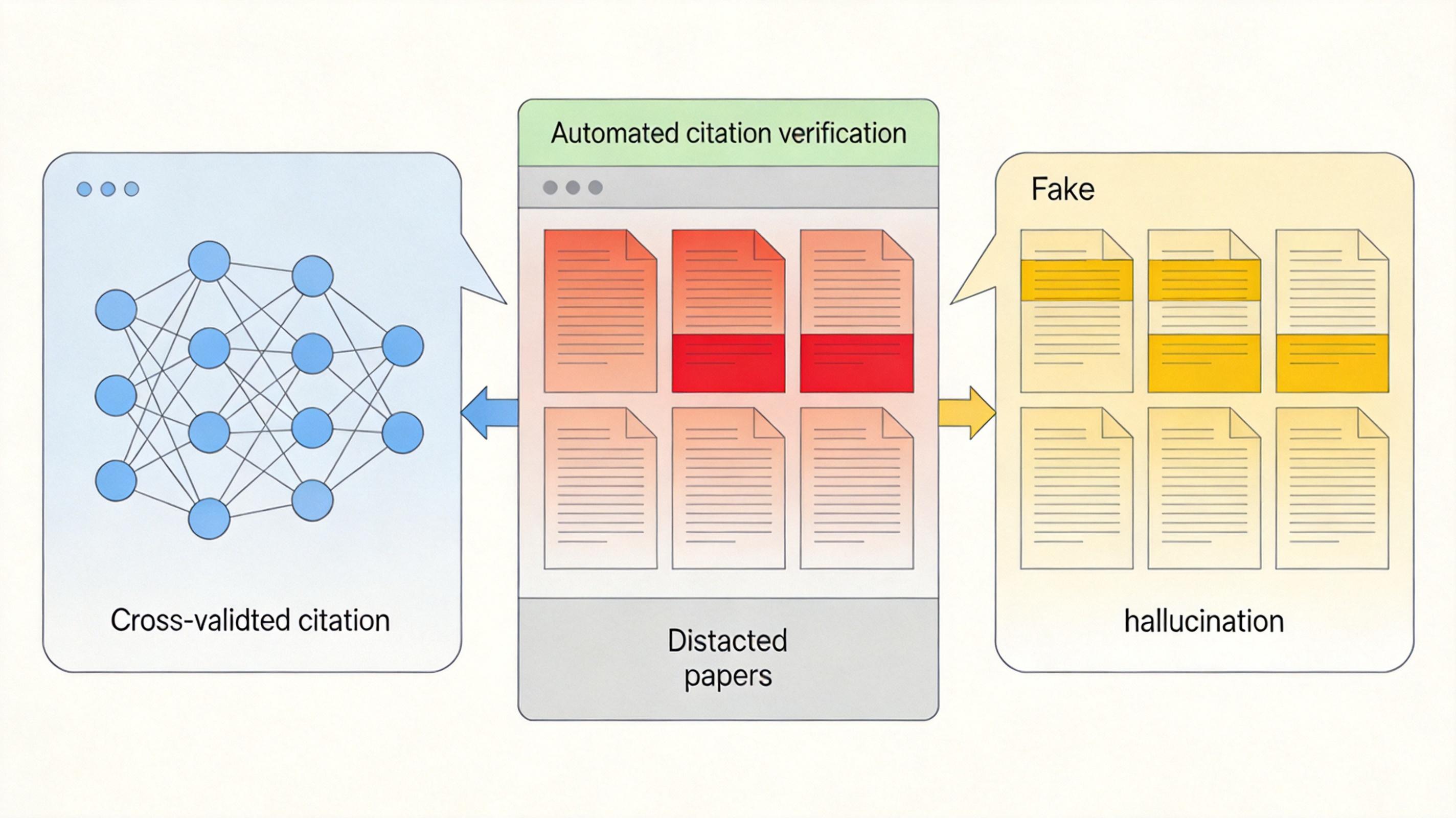
但开放获取期刊和很多普通期刊还在裸奔。PLOS出版社承认,他们在投稿中发现了大量无法核实的引用,虽然正在测试核查工具,但面临着高误报率的问题——合法引用常因为格式错误、数据库收录不全被误判为假引用。 除了技术手段,学界也在补制度的课:美国心理学会等机构要求作者必须披露AI使用情况,部分期刊把AI辅助写作的规范写进了投稿指南;不少高校开始开设AI伦理课程,教学生怎么辨别AI生成的假内容。但这些措施还只是「补丁」——要真正解决问题,可能得先改变「以发表数量论英雄」的评价逻辑。
当我们讨论AI带来的学术诚信危机时,其实在问一个更本质的问题:我们到底需要什么样的学术?是快速生产、填满数据库的论文,还是真正推动知识进步的研究? 托帕兹的那次社死经历,更像一个预警——AI只是放大了学术生态里早已存在的浮躁,假引用不过是浮在水面的冰山一角。「效率诚可贵,诚信价更高」,这句老套的话,在AI时代突然有了新的重量。毕竟,学术的根基从来不是论文的数量,而是每一条引用背后,对真相的较真。