对抗知识焦虑,从看懂这条开始
App 下载
AI写代码的真相:模型只是引擎,架构才是灵魂
自动化测试脚本|项目依赖结构|ChatGPT|Claude Code|编码代理架构|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自动化测试脚本|项目依赖结构|ChatGPT|Claude Code|编码代理架构|大语言模型|人工智能
凌晨三点,你盯着屏幕上的报错信息抓耳挠腮——这是今天第五次卡在同一个测试bug上了。你打开ChatGPT,输入“帮我修复这个测试”,它给出的代码却连项目的依赖结构都没搞清楚。但如果你换用Claude Code,它会先自动读取项目README,检查Git分支状态,甚至调用测试脚本复现错误,最后给出的修复方案一次就通过。
同样是大语言模型,为什么差距这么大?答案不在模型本身,而在它外面那层看不见的“脚手架”——编码代理架构。
你可以把编码代理想象成一个资深程序员的完整工作台:桌上摆着项目文档、Git工具、调试脚本,脑子里记着项目历史和待办事项,手上能随时调用各种开发工具。而支撑这个工作台的,是六个核心组件的协同运转。
第一个组件是**实时仓库上下文**——就像程序员刚接手项目时先摸清代码结构,编码代理会先收集项目的Git分支、文件目录、README等信息,生成一份“项目快照”,确保AI不是在空白状态下瞎猜。
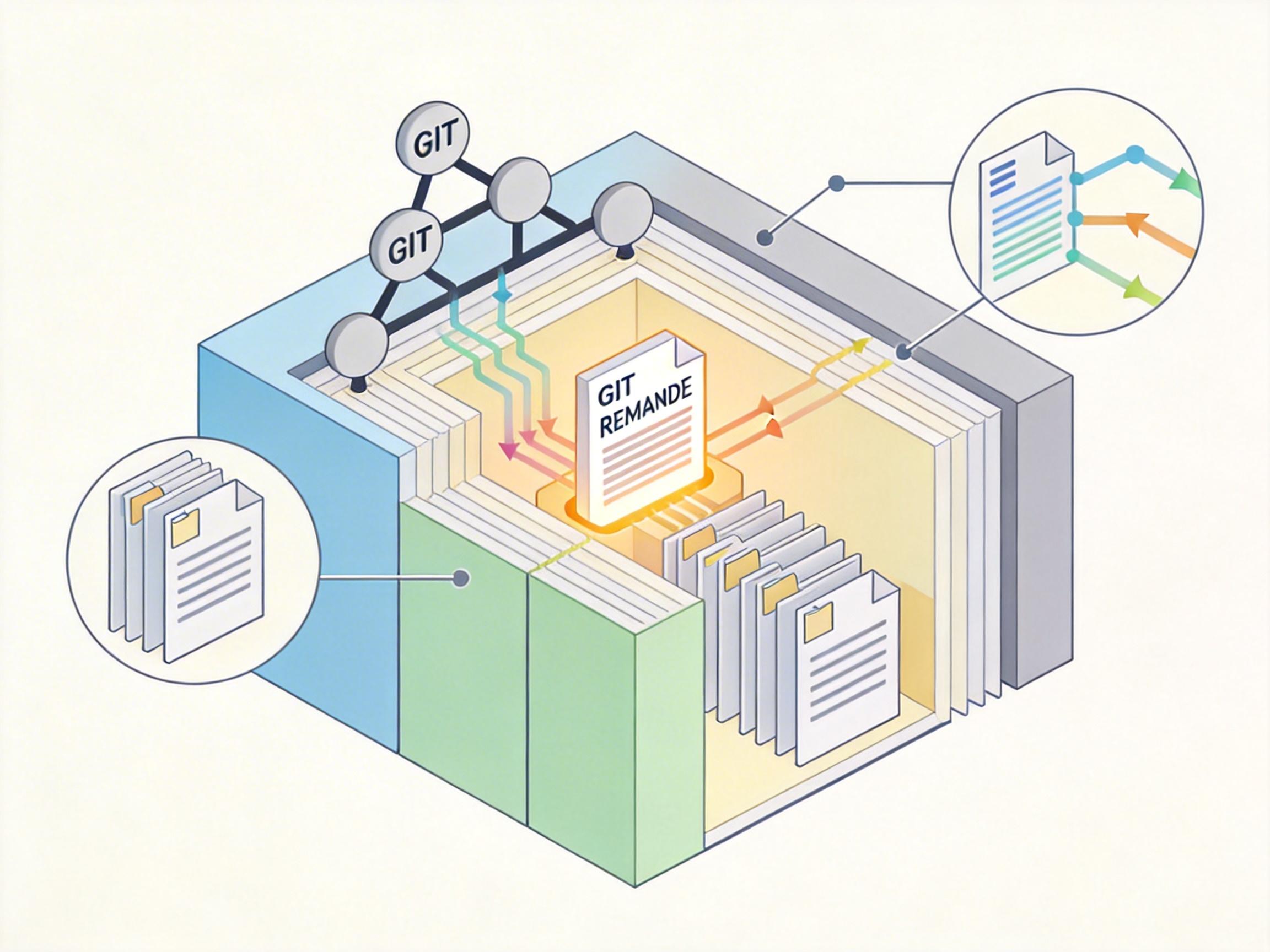
第二个组件是提示缓存复用——你不会每次写代码都重新读一遍项目规范,编码代理也不会。它把不变的项目规则、工具说明缓存成“稳定前缀”,每次只更新最新的用户请求和对话历史,能把推理延迟降低5到10倍。
剩下的四个组件则分别解决了AI写代码的核心痛点:结构化工具调用让AI能安全地执行命令、读写文件;上下文压缩防止AI被海量历史信息淹没;会话记忆让AI能断点续接,不用每次都重复解释需求;子代理委托则让AI能把复杂任务拆给“专家子代理”并行处理,比如让一个子代理专门查代码,另一个专门写测试。
这些组件加起来,才让AI从“会写代码的机器人”变成了“懂项目的协作伙伴”。
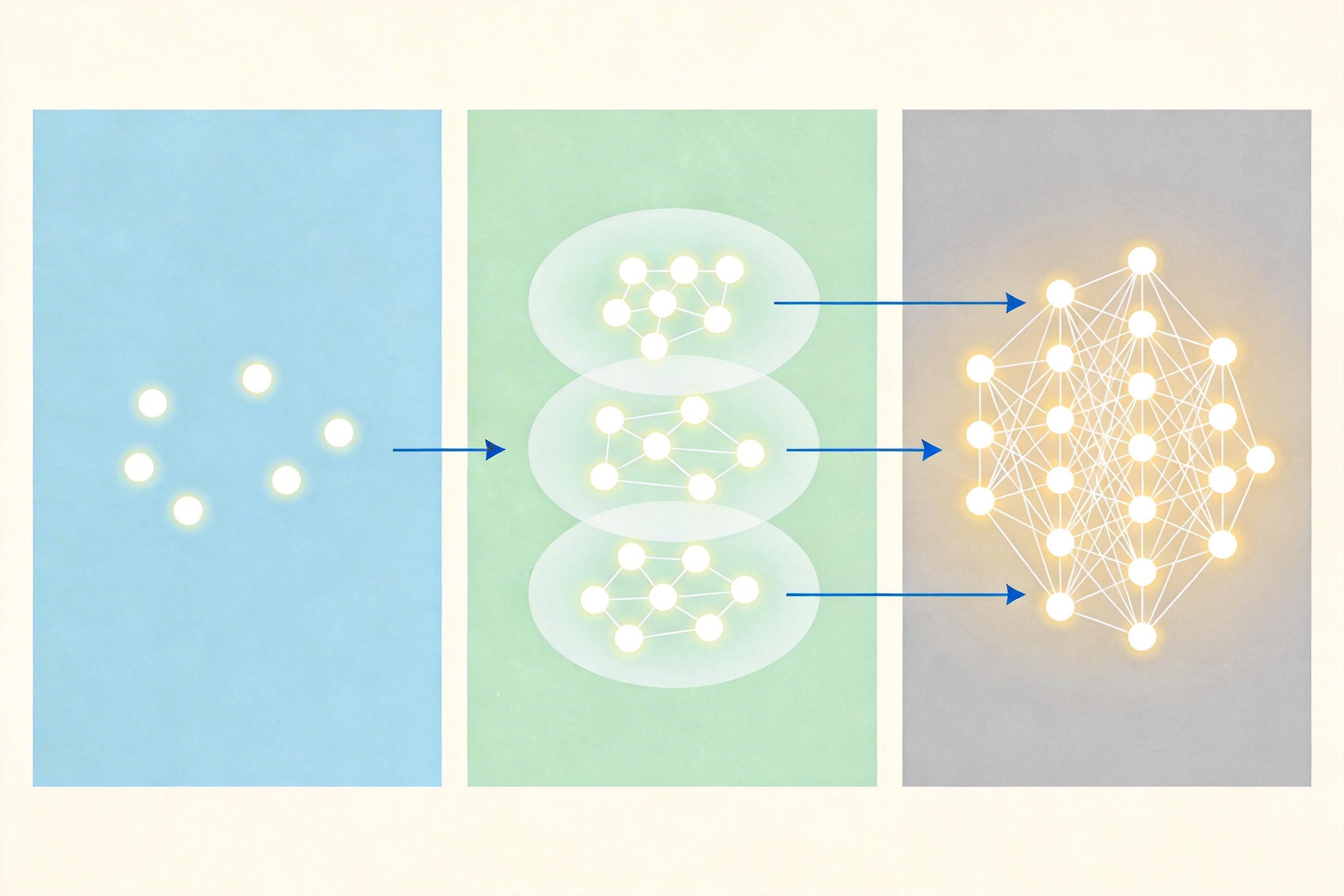
你有没有过这种经历:和ChatGPT聊了半小时项目细节,突然它就忘了你之前说的需求?这是因为传统大模型只有短期“工作记忆”,对话结束就清零。而编码代理的多层记忆系统,能让AI像人类一样“记住”关键信息,同时又不会被无关信息干扰。
编码代理的记忆分为三层:短期工作记忆负责当前对话的上下文,比如你刚说的“修复支付模块”;情节记忆存储历史交互,比如上周你让它优化过的某个接口;语义记忆则是项目的知识库,比如代码规范、API文档。
但光有记忆还不够——如果把所有历史信息都塞进AI的上下文窗口,不仅会浪费算力,还会让AI抓不住重点。这就需要**上下文压缩机制**:它会把冗长的工具输出剪短,把重复的文件读取去重,把旧的对话历史压缩成摘要,只保留最相关的信息。
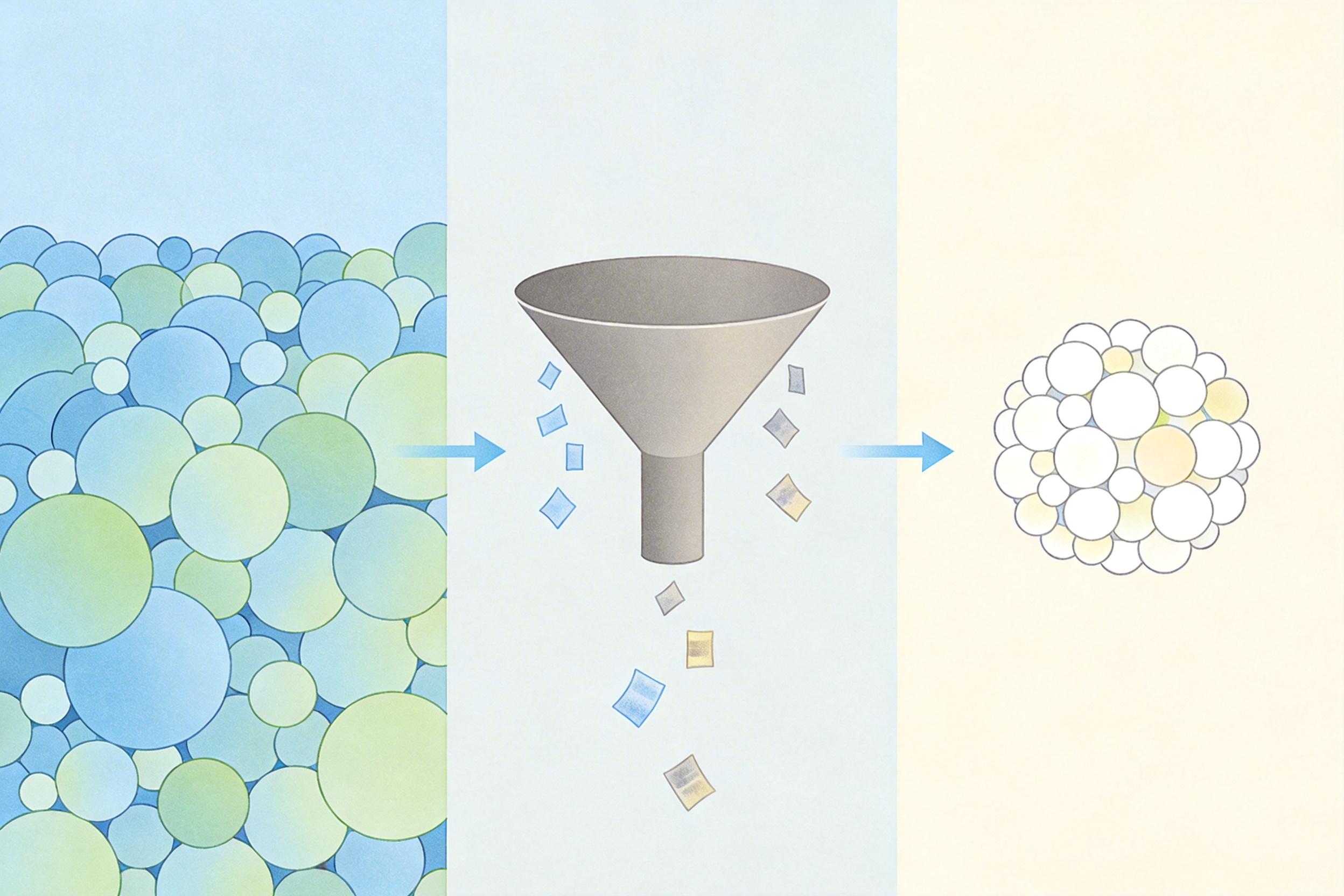
更重要的是,编码代理的记忆是“可检索”的。当你让它“修复支付模块的超时问题”,它会自动从记忆里调出上周优化的接口信息,从项目上下文里找到支付模块的依赖,而不是从零开始推理。这就像你写代码时会翻之前的笔记,而不是每次都重新查文档。
编码代理的能力已经超出了很多人的想象——它能自动修复bug、生成测试、甚至重构整个模块,但它依然有无法突破的边界。
最大的挑战来自记忆安全:如果有人通过恶意指令污染了AI的记忆,这个错误会在后续的所有任务中持续存在,甚至传播给其他子代理。就像一个程序员记错了需求,整个团队都会跟着走偏。
另一个挑战是可解释性:当AI给出一个修复方案时,你很难知道它是怎么推理出来的——是看了哪段代码?参考了哪个文档?这种“黑箱”特性,让开发者不敢把核心业务完全交给AI。
更值得警惕的是“认知惰化”风险:过度依赖AI的开发者,可能会逐渐丧失独立解决复杂问题的能力,就像飞行员过度依赖自动驾驶仪,遇到紧急情况会手足无措。
但这些挑战不是阻止我们使用AI的理由,而是提醒我们:AI的正确定位是“协作者”,而不是“替代者”。开发者需要做的,是学会和AI分工——让AI处理重复的编码、测试工作,人类则专注于需求分析、架构设计这些需要创造力和判断力的环节。
当你下次用编码代理修复bug时,不妨停下来看看它的工作流程:它先读项目文档,再查代码历史,然后调用测试脚本,最后给出修复方案——这和一个资深程序员的工作流程几乎一模一样。
大语言模型的突破让AI能写代码,但真正让AI能“做开发”的,是编码代理架构带来的上下文理解、记忆管理和工具调用能力。这不仅是技术的进步,更是对软件开发流程的重新定义:未来的开发,不再是人类独自写代码,而是人类和AI协同完成从需求到部署的全流程。
模型是引擎,架构才是灵魂。 这句话不仅适用于编码代理,也适用于所有AI应用——真正的智能,从来不是单一技术的突破,而是系统协同的结果。