对抗知识焦虑,从看懂这条开始
App 下载
亚马逊卖芯片了,要动英伟达的蛋糕
AI训练硬件|OpenAI|英伟达|Trainium芯片|亚马逊|半导体技术|AI产业应用|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI训练硬件|OpenAI|英伟达|Trainium芯片|亚马逊|半导体技术|AI产业应用|前沿科技|人工智能
2026年4月的一个财报电话会上,亚马逊CEO安迪·贾西抛出了一颗行业炸弹:未来两年内,他们将把自研的Trainium AI芯片打包成物理机架,直接卖给外部客户。这意味着,这家靠云服务租算力的公司,要正式当起芯片商——而它的第一个对手,就是占据AI芯片市场78%份额的英伟达。更惊人的是,贾西同时透露,Trainium已经攥住了2250亿美元的客户收入承诺,OpenAI、Anthropic这些AI巨头都是它的买家。为什么亚马逊敢突然换赛道?这颗芯片到底藏着什么底气?
你可以把Trainium理解成一台专为AI训练量身定做的「超级计算器」——它不像通用GPU那样什么活都干,而是把所有性能都堆在AI模型训练这一件事上。2015年亚马逊收购以色列芯片公司Annapurna Labs后,花了8年磨出这把刀:最新的Trainium3用了台积电3nm工艺,单芯片FP8算力能达到2517 TFLOPS,搭配144GB的HBM3E内存,带宽是前代的1.7倍。
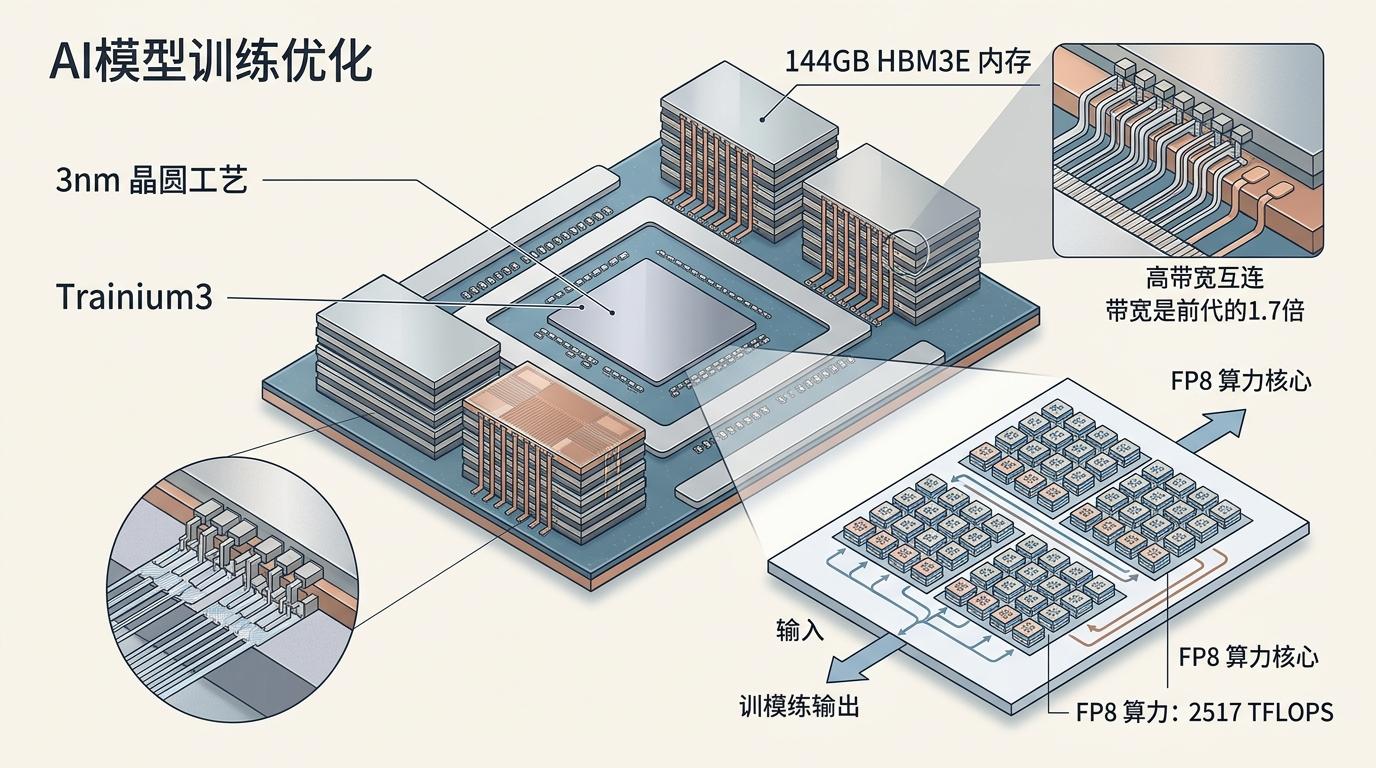
但真实的厉害之处不在单芯片,而在「攒局」的能力。Trainium3放弃了传统的环形网络,改用全互联交换架构,最多能把144颗芯片塞进一个液冷机架,整体算力相当于362 PFLOPS——足够支撑万亿参数级的大模型训练。更关键的是,它的成本比英伟达H100低30%-50%,这对被算力成本压得喘不过气的AI公司来说,几乎是无法拒绝的诱惑。
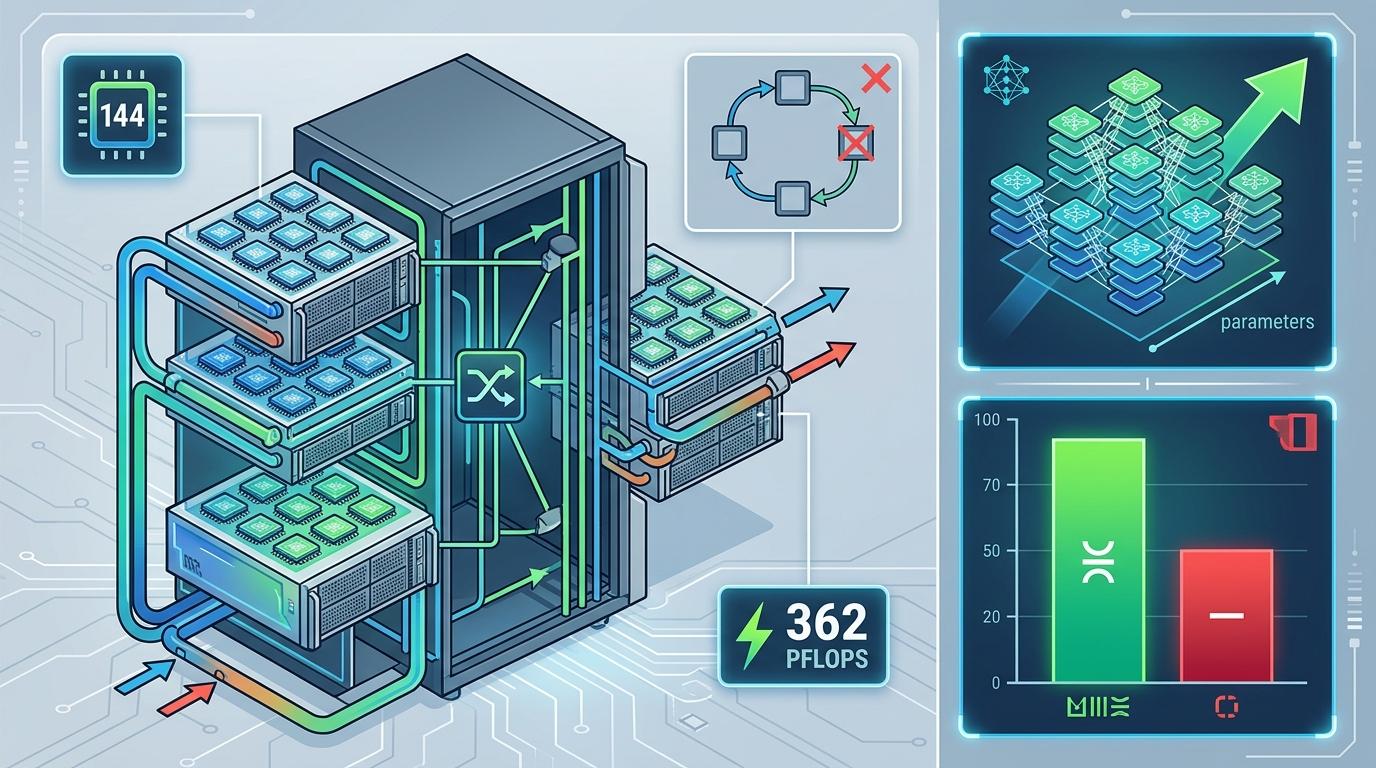
不过现在的Trainium还带着云服务的「胎记」:它只能通过AWS的云实例租用,客户碰不到物理硬件。而卖机架,相当于把这台超级计算器的钥匙直接递出去——企业可以把它放进自己的数据中心,不用再按月给云服务商交钱。
亚马逊敢挑战英伟达,手里握着两张硬牌:一是客户,二是成本。贾西提到的2250亿美元收入承诺里,光是Anthropic就锁定了1000亿美元的Trainium容量,OpenAI也签了1380亿美元的多年合同。这些客户不是小作坊,是每天都要烧几亿算力的AI巨头,他们的选择本身就是最好的广告。
但硬币的另一面,是绕不开的尴尬:亚马逊至今还在依赖英伟达的GPU支撑部分云服务。如果真的把芯片卖到市场上,等于和自己的「供应商」直接开战——万一英伟达收紧GPU供应,亚马逊的云业务可能先受影响。而且Trainium的软肋也很明显:它的软件生态和英伟达的CUDA比起来,还像个刚学会走路的孩子。
有开发者测试过,用Trainium训练CNN模型,速度是CUDA的2.3-4.9倍慢,成本甚至是3-5倍高;更麻烦的是,一些现代CNN架构因为硬件缓存限制,根本没法在Trainium上运行。亚马逊也在补这个短板:他们计划开源PyTorch后端、编译器和通信库,试图拉开发者入伙,但要追上英伟达400万开发者的生态,显然不是一朝一夕的事。
亚马逊卖芯片这件事,真正改变的不是芯片市场的格局,而是AI算力的「购买逻辑」。过去企业要做AI训练,要么租云服务商的算力,要么花大价钱买英伟达的GPU——现在多了第三个选择:买亚马逊的机架,自己搭算力集群。
这背后是AI公司的普遍焦虑:云服务的按次付费模式,长期算下来成本高得离谱;而英伟达的GPU常年缺货,有钱也未必能买到。Trainium的出现,相当于给市场打开了一个缺口:企业可以用更低的成本锁定长期算力,还能避开供应链的卡脖子问题。
但这条路也不好走。买机架不是买服务器,企业得自己解决散热、运维、模型迁移这些麻烦事——光是把一个训练好的模型从CUDA转到Trainium,可能就要花50个小时改代码。而且亚马逊自己也面临挑战:3nm工艺的良率不稳定,Trainium3的产能能不能跟上订单还是未知数;液冷机架的部署成本极高,不是所有企业都能负担得起。
当亚马逊把Trainium的机架推向市场时,它其实在做一件比卖芯片更重要的事:打破AI算力市场的「单一供应商依赖」。过去几年,英伟达的GPU几乎成了AI训练的代名词,所有公司都在跟着CUDA的规则走。而现在,终于有了一个能拿出真金白银客户的挑战者。
当然,亚马逊未必能立刻撼动英伟达的地位——CUDA的生态壁垒不是靠一款芯片就能打破的。但它至少证明了一件事:AI算力的未来,不该只有一种选择。「算力的竞争,最终是生态的竞争」,这句话放在今天,比任何时候都更有分量。也许用不了多久,我们会看到越来越多的企业,把不同厂商的芯片混在一起用——毕竟,能解决问题的算力,才是好算力。