对抗知识焦虑,从看懂这条开始
App 下载
AI正在拆碎论文,重构科学知识的模样
同行评审|科学出版体系|AI生成论文|萨里大学|Matt Spick|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载同行评审|科学出版体系|AI生成论文|萨里大学|Matt Spick|大语言模型|人工智能
2024年的一天,英国萨里大学的统计学家Matt Spick坐在办公桌前,对着屏幕皱起了眉——他作为副编辑的期刊,当天已经收到了第二篇几乎一模一样的论文。两篇文章都用同一个公开健康数据集,做着大同小异的单因素分析,连措辞都像从同一个模子里刻出来的。而这样的论文,他已经连续收了三个月。没人会想到,400年前由英国皇家学会开创的科学论文体系,在AI的冲击下正濒临过载:有人用AI批量制造低质论文,有人用AI一周写完原本要耗三个月的初稿,连同行评审都有21%是AI生成的。但更值得注意的是,这场混乱的背后,一场比论文诞生更深刻的变革正在发生。
你或许不知道,现在我们习以为常的“科学论文”,本身就是一场17世纪的创新。在那之前,科学家要发表成果,得写厚厚的专著——开普勒用10年写成《新天文学》,牛顿的《自然哲学的数学原理》攒了20年才动笔。直到1665年《哲学汇刊》创刊,才把知识拆成了短篇论文,让研究者能像搭积木一样,踩着彼此的成果快速前进。达尔文曾抱怨,他的进化论没法塞进一篇期刊论文里,得写《物种起源》那样的厚书才够严谨,但最终,短篇论文还是成了主流。
AI的出现,正在把这场拆解推向极致。加州理工学院的Lior Pachter团队开发了一套叫OpenEval的系统,它能像拆乐高一样,把一篇科学论文拆成一个个独立的“知识单元”:比如“X基因与Y疾病相关”是一个核心声明,后面跟着支撑它的实验数据、统计方法,还有对这个结论可靠性的评估。
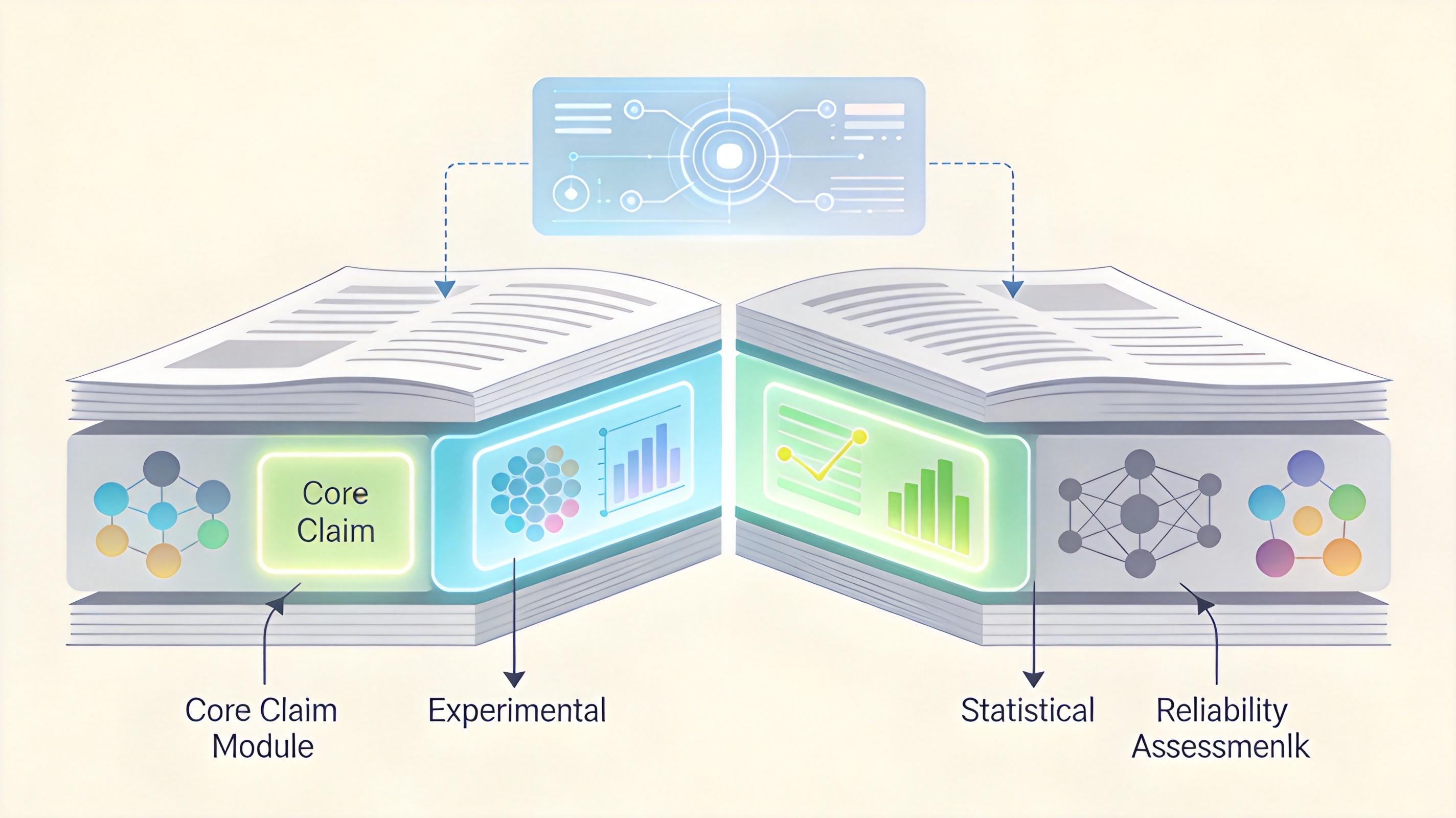
在对eLife期刊1.6万篇论文的测试中,OpenEval提取出了近200万个这样的单元。更惊人的是,AI能覆盖93%的声明,而人类审稿人平均只能检查到68%——毕竟,没人能在几天内读完一篇论文的同时,还能记住每一个细节并验证逻辑。
传统论文就像一本装订好的书,所有信息都按固定顺序排列,你得从头到尾读,才能找到需要的内容。但机器可读的知识单元不一样,它们像散落在货架上的零件,AI能快速把相关的零件拼起来——哪怕它们来自完全不相关的论文。
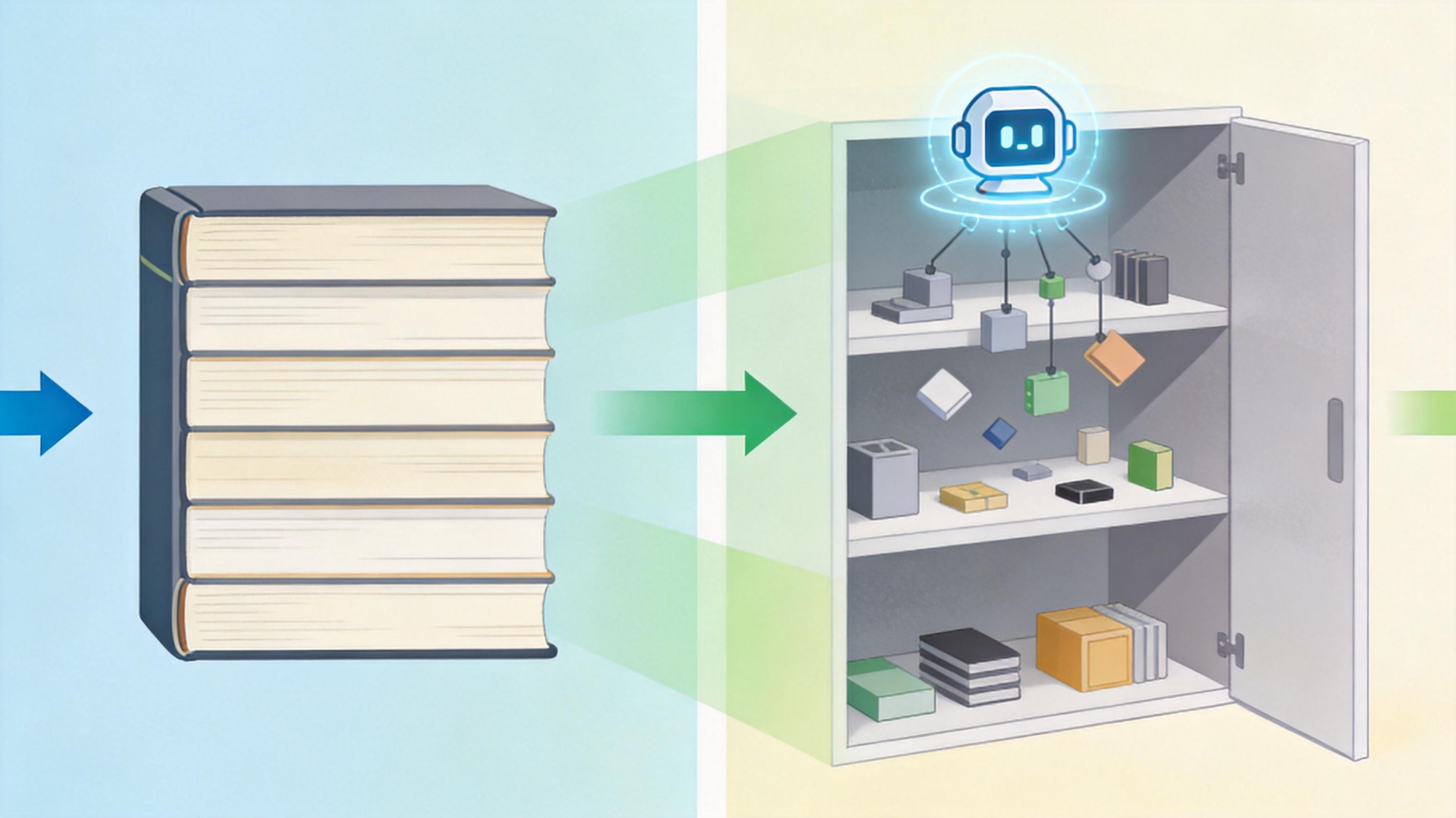
神经科学领域就发生过这样的事:有两篇研究同一突触机制的论文,分别在不同脑区做实验,得出了看似矛盾的结论,但因为研究的脑区不同,两篇论文根本没互相引用。OpenEval系统把它们的声明和数据放在一起比对后,发现其实结论是互补的:这个机制在不同脑区的作用本来就不一样。要是没有AI的帮助,这个能重塑整个领域认知的发现,可能还要被埋没好几年。
不过,这种拆解也不是没有代价。有科学家担心,写论文的过程本身就是思考的过程——你在把实验结果串成逻辑链的时候,会发现数据里的漏洞,会意识到之前的假设不对,甚至会突然冒出新的想法。而Google的PaperOrchestra系统,能在40分钟内把实验笔记变成一篇格式完美的论文,直接跳过了这个“痛苦但必要”的思考环节。要是科学家都不用自己写论文了,会不会错过那些在写作中诞生的灵感?这是目前支持AI拆解论文的人还没说清的问题。
其实,没人想彻底抛弃论文。就像数学家证明猜想时,会同时写一篇传统论文和一份机器验证的证明:前者用人类能懂的语言解释思路和意义,后者用机器能读的代码保证每一步都严谨。未来的科学出版,可能也是这样的模式:论文依然存在,但它不再是知识的唯一容器,而是一个“解释层”——你可以从机器可读的知识库里,随时生成一篇适合自己需求的论文:比如给同行看的专业版,给学生看的科普版,甚至是只包含实验数据的验证版。
意大利物理学家Francesca Colaiori提出的“自适应知识网络”走得更远:未来的科学贡献不再是论文,而是一个个独立的“知识对象”——可能是一个实验数据,一个研究方法,甚至是一个未解决的问题。这些对象像维基百科的词条一样,可以被不断编辑、链接、更新,形成一个动态生长的知识网络。
当然,这一切都需要整个学术生态的配合:现在的评价体系只认论文数量和引用率,要是“知识对象”不算成果,没人会愿意花精力去整理。但已经有期刊开始尝试了:NEJM AI用AI辅助评审,能在7天内完成从投稿到初步接受的流程,还会公开AI的评审意见,让整个过程更透明。
从专著到论文,科学交流的每一次变革,都伴随着得与失:论文让科学进步更快,但也牺牲了专著的系统性;AI拆解论文能挖出更多隐藏的知识,但也可能带走写作中的思考。不过,就像当年达尔文的抱怨没能阻止论文成为主流一样,现在的担忧也挡不住AI带来的变革。
毕竟,科学的本质不是写论文,而是发现真相。当论文这个容器已经装不下爆炸的知识时,换个容器是迟早的事。知识的形态变了,但探索的初心没变。或许未来的某一天,我们回头看现在的科学论文,会像现在看牛顿的厚书一样,觉得那是一种古老但可敬的交流方式。