对抗知识焦虑,从看懂这条开始
App 下载
树莓派外接4张GPU,性能直逼服务器:低功耗计算革命来了?
PCIe Gen 3通道|Llama 3|NVIDIA RTX A5000|树莓派5|消费电子|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载PCIe Gen 3通道|Llama 3|NVIDIA RTX A5000|树莓派5|消费电子|AI算力|前沿科技|人工智能
在一场算力竞赛中,人们习惯于将目光投向那些体积庞大、功耗惊人的高性能计算集群。然而,一个信用卡大小、功耗仅几瓦的设备,正悄然发起一场挑战。这并非科幻小说的情节,而是一场正在真实上演的计算范式变革:当小巧的树莓派接上强悍的GPU,它能否撼动传统高性能PC的统治地位?
最近,一场由社区极客发起的实验震惊了科技圈。GitHub用户mpsparrow将四张NVIDIA RTX A5000专业显卡连接到一台树莓派5上,用于运行参数量高达700亿的Llama 3大语言模型。从理论上看,这是一场极不对等的较量:树莓派5仅有一条PCIe Gen 3通道,带宽上限约8 GT/s;而现代PC动辄拥有16条PCIe Gen 5通道,带宽高达512 GT/s,两者相差数十倍。
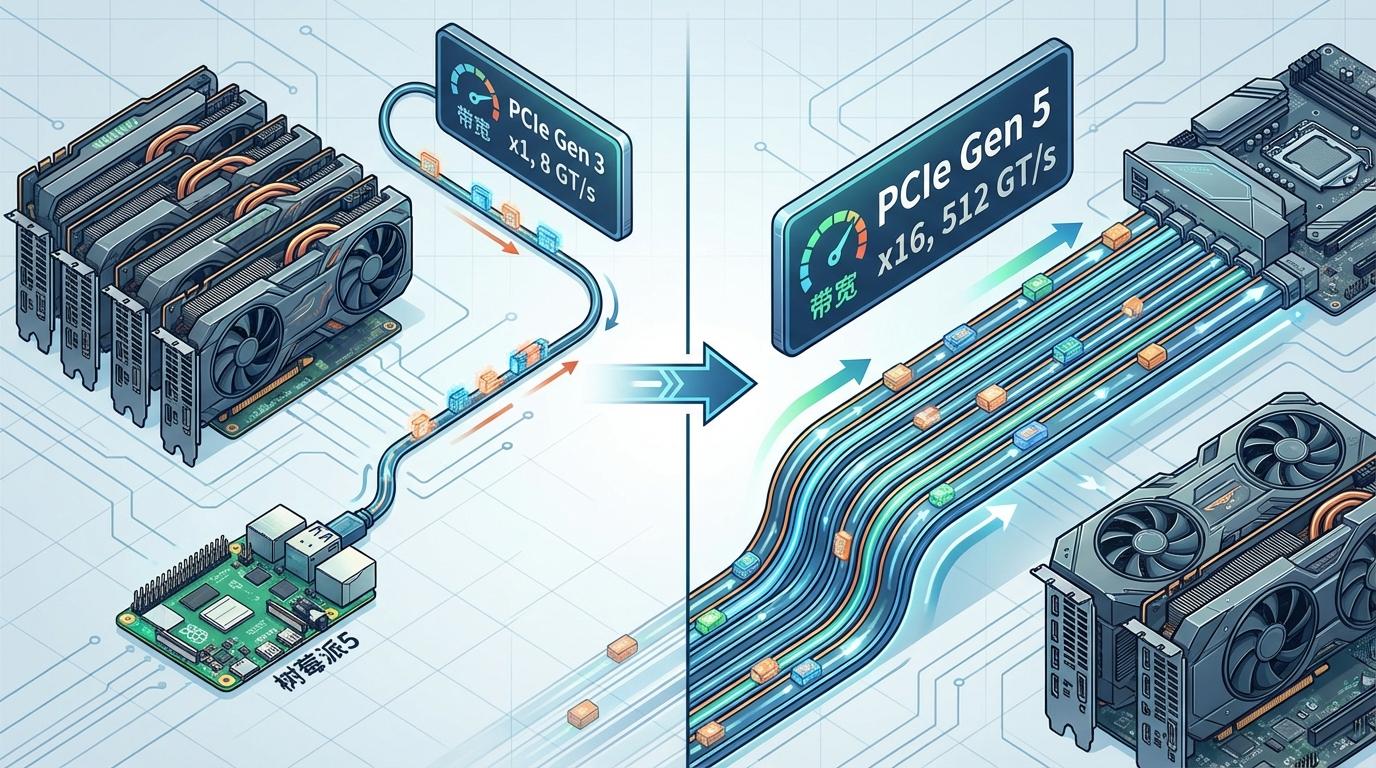
然而,实验结果却出人意料。这套“树莓派+四GPU”的组合,在生成大模型响应时达到了每秒11.83个token的速度。作为对比,一台搭载同样GPU配置的现代英特尔服务器,其速度为每秒12个token。性能差距不足2%。
这几乎是一个不可能完成的任务。人们不禁要问:带宽的鸿沟是如何被填平的?
答案在于计算范式的转变。在传统的“南北向”数据流中,所有数据都需要通过CPU和主板的总线进行中转,树莓派那条孱弱的PCIe通道无疑是最大的瓶颈。然而,在这次实验中,一个外部PCIe交换机(PCIe Switch)扮演了关键角色。
这个交换机就像一个智能交通枢纽,它允许GPU之间直接建立高速通信链路,形成“东西向”的数据流。在这种模式下,GPU们可以像一个紧密协作的团队,直接在彼此的显存间共享数据,而无需频繁地通过树莓派这条“乡间小路”。树莓派的角色从一个数据搬运工,转变为一个轻量级的“任务协调员”,只负责发出指令和接收最终结果。

这一巧妙的架构设计,成功绕开了主机的性能瓶颈,将计算的核心压力完全交给了GPU集群。实验证明,对于高度并行的GPU密集型任务,主机性能不再是决定性的天花板。
这场实验的意义远不止于性能上的追平,更在于其背后惊人的成本与能效优势。
在AI推理、3D渲染等多个测试场景中,研究者发现了一个共同趋势:即便在单卡配置下,树莓派组合的峰值性能可能略逊于PC平台(通常差距在2%-5%),但其**“每瓦性能”(Performance per Watt)却常常遥遥领先**。这意味着,用同样的电力,树莓派能完成更多的计算任务。这对于追求绿色计算和降低运营成本的个人开发者与小型企业而言,具有无与伦比的吸引力。
尽管前景光明,但这套低功耗方案并非没有局限。它的优势高度依赖于特定的工作负载。
树莓派外接GPU的成功,不仅仅是一次极客的狂欢,它更揭示了未来计算的几大趋势:
边缘AI的普及:随着AI模型向边缘设备下沉,低功耗、高效率的本地推理方案成为刚需。树莓派与Hailo等公司合作推出的AI加速模块(NPU),正是这一趋势的体现。未来的智能设备,将不再仅仅依赖云端大脑,而是拥有强大的本地计算能力。
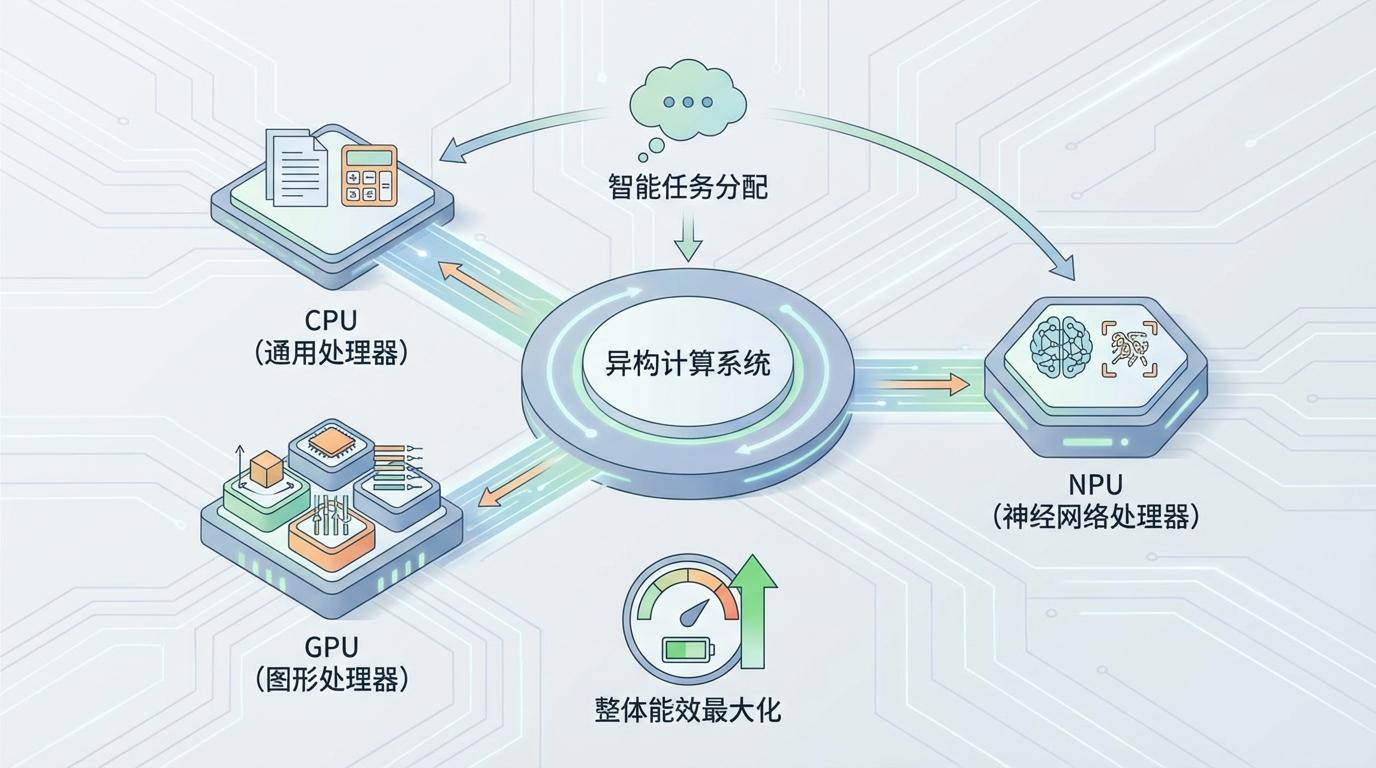
计算的“专用化”:通用CPU“一核包打天下”的时代正在过去。未来的计算系统将是异构的,由CPU、GPU、NPU等多种专用处理器协同工作。任务将被智能地分配给最适合它的计算单元,从而实现整体能效的最大化。
结论
回到最初的问题:树莓派能否取代高性能PC?答案是否定的。但在一个日益关注能耗与成本的时代,它成功地为我们开辟了一条新的道路。它证明了,通过聪明的架构设计和对应用场景的精准把握,低功耗设备同样可以爆发出惊人的计算潜力。
这场“以小博大”的挑战,与其说是对传统PC的颠覆,不如说是一次计算理念的深刻重塑。它提醒我们,真正的“性能”不仅仅是峰值速度的比拼,更是算力、能耗与成本三者间的完美平衡。未来,计算将无处不在,而这些小巧、高效的设备,将是构成这个智能世界最坚实的基石。