对抗知识焦虑,从看懂这条开始
App 下载
AI服务器要缩成1台,内存先变聪明了
计算架构|SK海力士|三星|数据搬移能耗|内存芯片|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载计算架构|SK海力士|三星|数据搬移能耗|内存芯片|AI算力|人工智能
当你给ChatGPT发一句提问,数据正经历一场看不见的长途奔袭:从内存跑到CPU预处理,再扎进GPU做运算,算完再原路返回——每生成一个字,这套往返流程就得重复一次。更夸张的是,AI推理时90%的能耗都耗在了数据搬家上,真正用来计算的能量只占10%。这道卡在AI算力脖子上的“内存墙”,逼得三家内存巨头市值集体破万亿,也让一群三星、SK海力士的老兵,攒出了能把10台服务器活儿干成1台的新芯片。
你可以把传统计算架构想象成一家分工僵化的工厂:计算是车间,内存是仓库,数据得靠卡车在两者间来回拉——车间里工人等着材料,仓库里堆着闲置货物,大半时间都耗在了路上。XCENA的MX1芯片,就是在仓库门口建了一排小加工站。
这排“加工站”是数千个基于RISC-V的小型计算核心,直接嵌在DRAM内存模块里。AI推理里最耗数据传输的活儿,比如给提问做预处理、管理对话上下文的KV缓存,现在不用再拉去CPU/GPU,在内存门口就能干完。它靠CXL协议——一种专门给内存和CPU开的“高速直达车道”——和主处理器连接,数据不用再绕远路,延迟和能耗直接砍半。
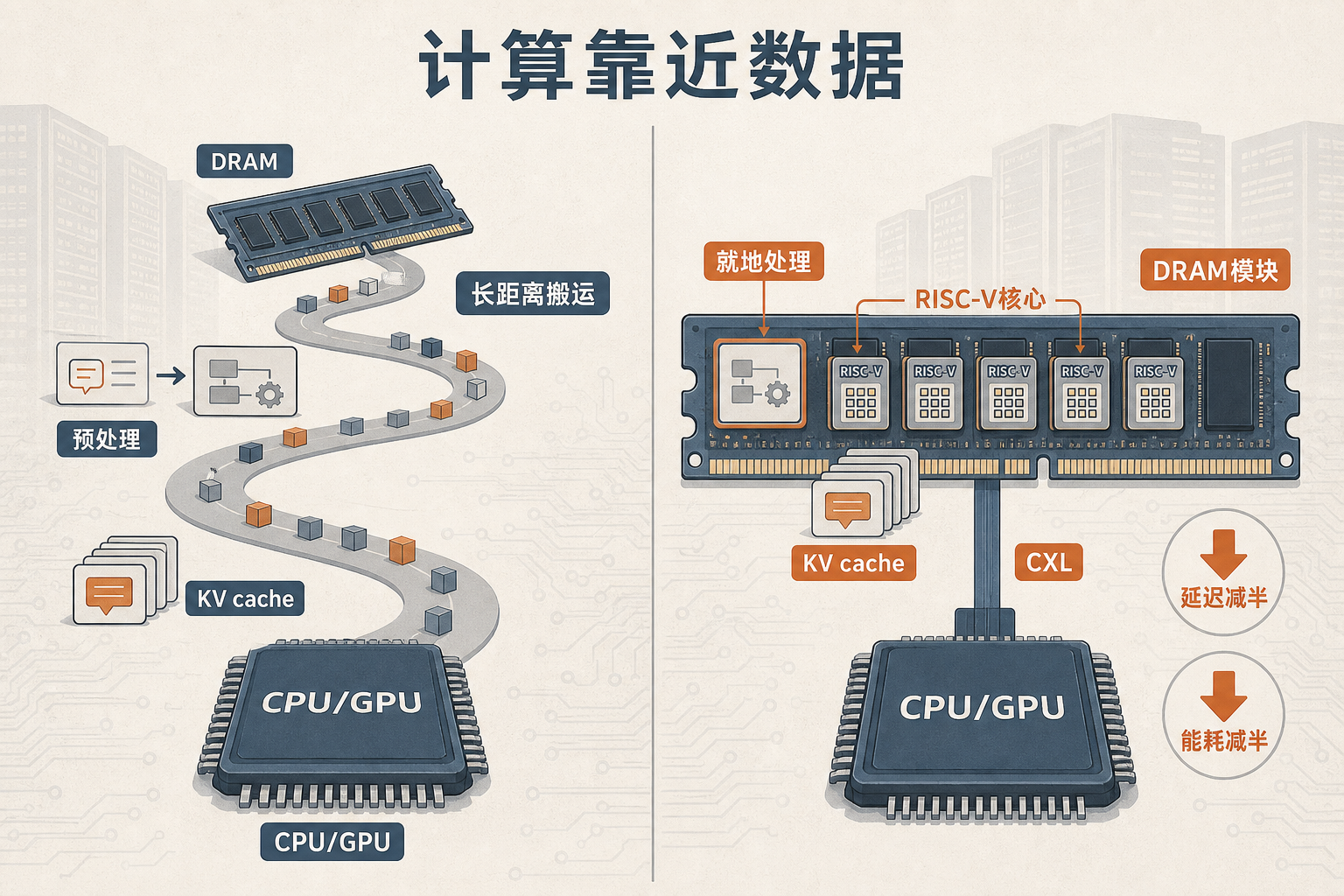
更关键的是,这套设计没碰传统架构的核心:不用改现有服务器的主板,不用换GPU,插上去就能用。团队宣称,原本需要10台服务器跑的AI推理任务,现在1台就能搞定,光是服务器采购成本就能降80%。
过去十年,AI算力竞赛的焦点一直在GPU上:谁的核心多、谁的浮点运算快,谁就占上风。但当大模型的参数从十亿级奔着万亿级涨,人们突然发现,GPU再强也没用——它大部分时间都在等内存喂数据。就像给消防车装了火箭发动机,却用一根吸管供水。

这就是“内存墙”的本质:传统冯·诺依曼架构里,计算和存储是分开的,数据传输速度永远赶不上计算速度。AI模型越大,要搬的数据就越多,浪费的算力和能耗就越惊人。三星、SK海力士们疯狂扩产HBM高带宽内存,本质是在给吸管加粗,但只要计算和存储还分家,就总有供不上的那天。
存算一体的思路,就是把“让数据跑向计算”改成“让计算靠近数据”。XCENA不是第一个吃螃蟹的,但它的特殊之处在于:团队全是三星、SK海力士出来的老兵,懂内存的底层逻辑,知道怎么在不破坏现有内存生态的前提下加计算单元。他们没像有些公司那样直接在内存里做模拟计算——那种方案虽然能效高,但兼容性差、难量产——而是用数字逻辑的小核心,平衡了性能、兼容性和成本。
现在的MX1还只是原型,要真的改变AI基础设施,还有三道坎要跨。
第一关是量产。把数千个计算核心嵌在内存模块里,工艺复杂度比普通内存高得多,良率控制是大问题。团队计划2026年底在三星的代工厂量产,但能不能稳定出货、把成本降下来,还是未知数。
第二关是软件生态。现在的AI框架都是为CPU/GPU设计的,要让模型能调用内存里的计算核心,得重新做适配。XCENA已经在开发自己的SDK,但要让OpenAI、谷歌这些大玩家愿意改代码,光靠技术还不够,得拿出实打实的成本优势。
第三关是可靠性。内存里加了计算单元,散热和功耗都会上升,数据中心里的服务器要24小时连轴转,稳定性出一点问题就是大事故。团队说他们做了专门的热管理设计,但真到大规模部署,还得经过市场的考验。
当三家内存巨头的市值集体破万亿,当云服务商为了抢GPU不惜溢价三倍,市场已经用脚投票:AI算力的瓶颈,早就不在计算本身了。存算一体不是什么颠覆式的黑科技,它更像是一种“迟到的修正”——给跑了七十年的冯·诺依曼架构,补上了存储和计算脱节的bug。
未来十年,AI基础设施的竞赛,可能不再是比谁的GPU更强,而是比谁能让数据跑得更少。“停止移动数据,让计算靠近它”,这句话听起来简单,却可能是AI算力从“狂飙突进”转向“细水长流”的开始。毕竟,能持续跑下去的算力,才是真的有用的算力。