对抗知识焦虑,从看懂这条开始
App 下载
11MB模型击败发音难题:AI如何破解普通话声调密码?
语言学习工具|AI语音私教|发音纠正|普通话声调|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载语言学习工具|AI语音私教|发音纠正|普通话声调|AI产业应用|人工智能
对于任何一个非母语者来说,学习普通话的旅程中总会遇到一堵无形的墙——声调。你可能已经掌握了数千个词汇,能流畅地组织句子,但只要声调稍有偏差,“你好(nǐ hǎo)”就可能变成“你跑(nǐ pǎo)”,瞬间让沟通陷入僵局。这种挫败感,是无数学习者共同的痛点:明明知道自己错了,却听不出错在哪里,身边又没有一位能24小时随时纠正的老师。
然而,一位开发者在经历了数百小时的学习后,决定不再忍受这种“知错难改”的困境。他没有选择更昂贵的课程,而是用代码为自己打造了一位严格、精准、不知疲倦的AI发音私教。这个故事,不仅是他个人学习的突破,更揭示了人工智能如何正在颠覆我们学习语言的方式。
这位开发者的初次尝试是构建一个音高可视化工具,试图通过视觉反馈来“看见”自己的声调错误。然而,现实远比理论复杂。背景噪音、语速变化、不同说话人的音域差异……无数的特殊情况让这个手调系统变得脆弱不堪。这次失败让他深刻领会了科技界的“苦涩教训”:当拥有足够的数据和算力时,深度学习模型的效果远超精心设计的手调规则。
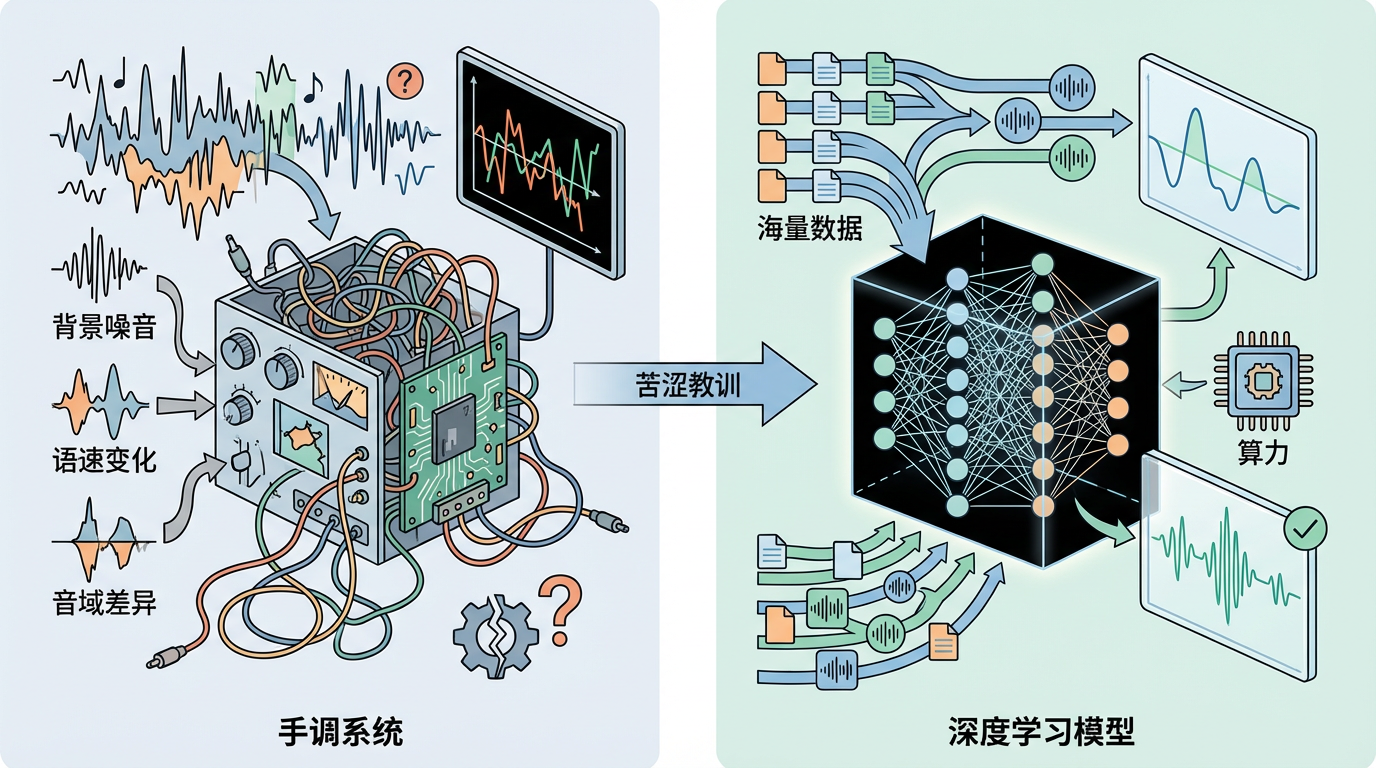
于是,他彻底转变思路,决定构建一个完全基于深度学习的计算机辅助发音训练(CAPT)系统。他收集了大约300小时的中文语音数据,包括AISHELL-1和Primewords等公开数据集,开始训练一个专门用于“挑错”的AI模型。
这个AI的核心使命并非简单地将语音转为文字,而是要对发音的每一个细节进行“像素级”的审判。它要回答的不是“你说了什么?”,而是“你是怎么说的?”
传统的语音识别(ASR)系统,如我们熟知的Whisper,其设计目标是尽可能准确地转录内容,它们会“善解人意”地自动纠正你的发音错误。这对于会议记录是优点,但对于语言学习却是致命的缺陷。学习者需要的不是一个宽容的“朋友”,而是一个严苛的“教练”。
为此,该系统采用了两项关键技术,使其化身为一位“吹毛求疵”的老师:
<blank>(空白)标记,强制模型必须精准对齐声音和音节,无法“脑补”或“跳过”任何发音瑕疵。你说错了,它就忠实地记录下你的错误,绝不含糊。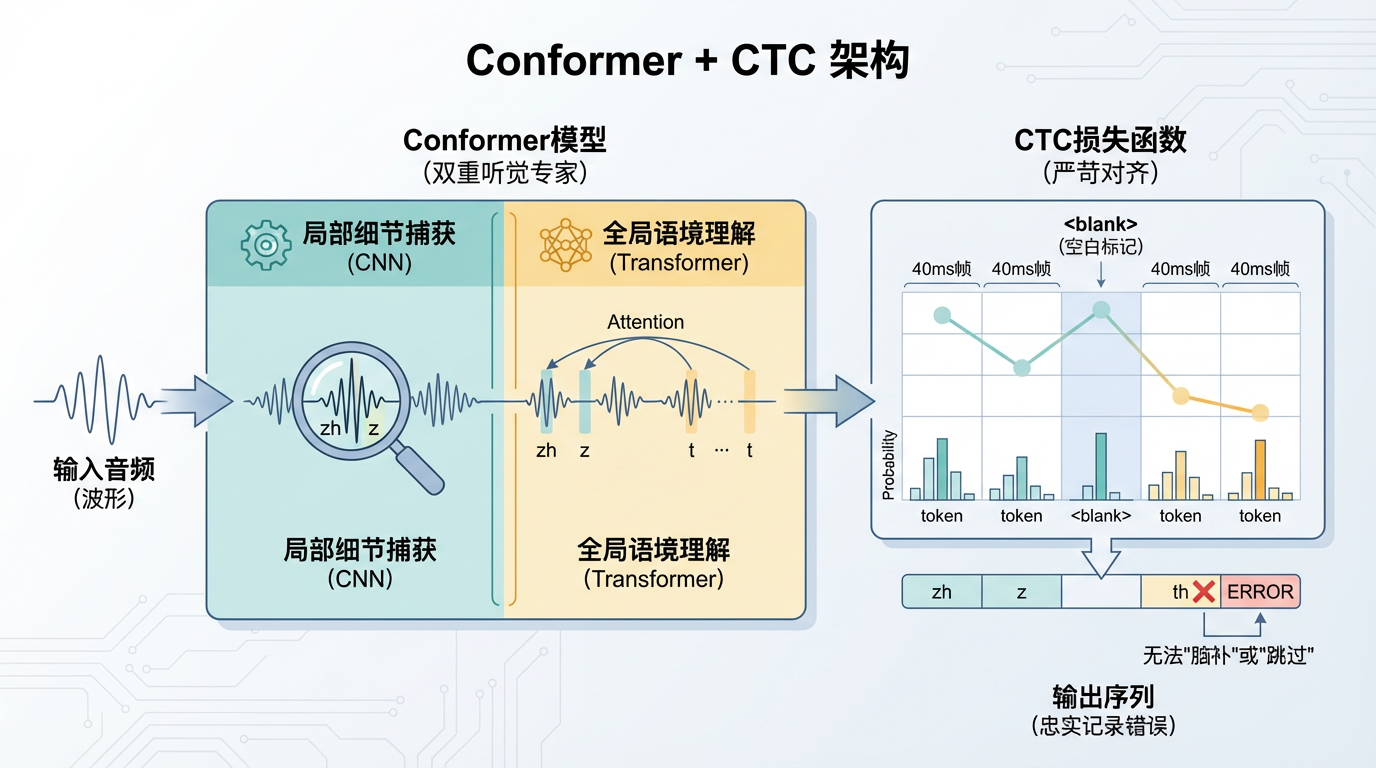
zhong1和zhong4是两个完全不同的“单词”。当用户读错声调时,模型会明确预测出一个错误的令牌ID,从而将声调错误暴露无遗。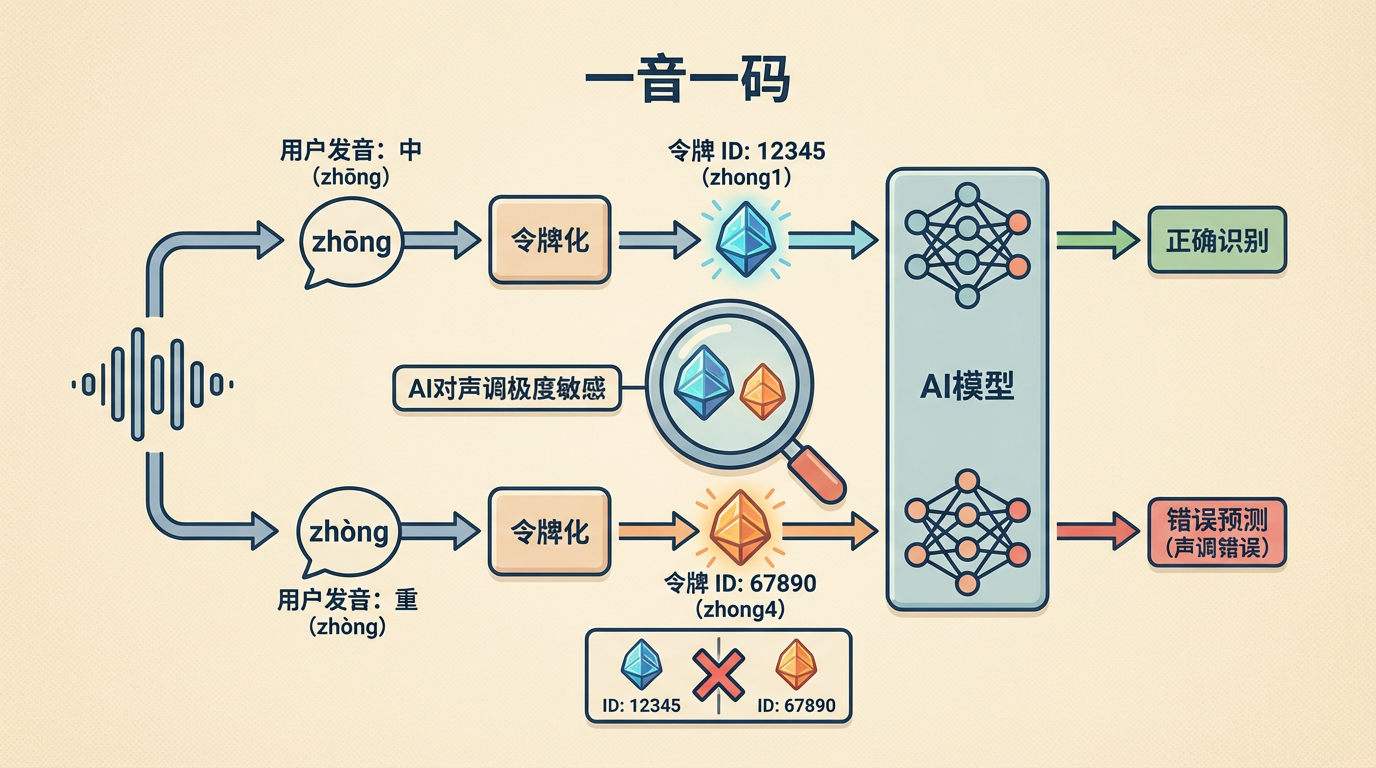
通过这种方式,AI不再是一个被动的转录工具,而是一个主动的发音诊断专家。它逐帧分析你的声音,精准指出每一个音节的成败。
最初,一个7500万参数的“中等”模型表现出色,但对于一个希望能在浏览器或手机上流畅运行的工具来说,它还是太庞大了。开发者开始了一场极限“瘦身”实验,将模型参数从75M压缩到35M,最终降至9M。
结果令人惊讶:9M参数的小模型,其发音错误率和声调准确率与75M的大模型相比,几乎没有明显下降。这一发现有力地证明,对于发音打分这项任务,瓶颈不在于模型的计算能力,而在于训练数据的规模和质量。这是一个典型的**数据约束(data-bound)而非计算约束(compute-bound)**问题。
经过最终的INT8量化,模型大小被压缩到了惊人的11MB,比今天许多网页的体积还要小。这意味着任何用户都可以通过浏览器即时加载并使用这位AI私教,无需下载笨重的应用程序,极大地降低了使用门槛。
尽管这个AI私教表现出色,但它并非完美。一个有趣的现象是,一些普通话母语者在使用时,反而会被系统判定为发音不标准,必须“过度清晰”地发音才能获得高分。这暴露了模型的局限性:由于其训练数据主要来自标准的“朗读式”语音,导致它对日常对话中更快速、更随意的口语“水土不服”。同样,儿童由于音高和发音习惯与成人不同,也难以获得准确评分。
这恰恰指明了未来的方向:引入更多元、更真实的会话语音数据,是提升模型泛化能力的关键。
与此同时,这种以AI驱动的发音评测技术,早已从个人项目走向了广阔的社会应用。在中国,以科大讯飞的“AI朗读平台”为代表的系统,已经深度融入教育体系。在“典耀中华”等全国性主题朗读活动中,AI成为了推广普通话、传承文化的有力工具。有数据显示,一名小学生通过该平台练习,朗读分数能从62分跃升至97分。教师也能通过班级整体报告,精准定位学生的共性弱点,实现高效教学。
从一个开发者为解决自身痛点而创造的11MB模型,到服务于数万学生的国家级语言学习平台,我们看到的是一个清晰的趋势:人工智能正在将过去昂贵且稀缺的“一对一”个性化辅导,变为人人皆可享有的普惠工具。
这位AI私教,它不知疲倦、绝对耐心,同时又严格得不近人情。它不会因为你的多次失败而气馁,只会一次又一次地用冰冷的数据告诉你错在哪里。这正是语言学习最需要的反馈闭环。未来,随着儿童、老年人、方言人群的语音数据不断丰富,这些AI模型将变得更加包容和智能,真正成为跨越语言和文化鸿沟的桥梁,让标准、流利的发音不再是少数人的专利。