对抗知识焦虑,从看懂这条开始
App 下载
从贝尔曼到AI:一条方程串起三代智能技术
扩散模型|强化学习|控制理论|Hamilton-Jacobi-Bellman方程|理查德·贝尔曼|应用数学|大语言模型|数理基础|人工智能
对抗知识焦虑,从看懂这条开始
App 下载扩散模型|强化学习|控制理论|Hamilton-Jacobi-Bellman方程|理查德·贝尔曼|应用数学|大语言模型|数理基础|人工智能
1952年,数学家理查德·贝尔曼在论文里写下了一段看似和AI无关的数学推导——他想解决的,是导弹轨迹优化这种冷战时期的硬核工程问题。没人能料到,半个多世纪后,这段推导会成为AlphaGo下棋、Stable Diffusion画图、机器人自主导航的共同数学骨架。
如今的AI看起来像是一堆黑箱算法的拼接,但只要往底层挖一挖,你会发现所有关于「最优决策」和「智能生成」的问题,最终都指向同一个方程:Hamilton-Jacobi-Bellman方程,简称HJB方程。它就像一条看不见的线,把70年前的控制理论、20年前的强化学习,和今天最火的扩散模型串在了一起。
你可以把HJB方程理解成「智能决策的数学说明书」。它的核心逻辑很简单:在每一个当下,你要做的最优选择,等于「当前能拿到的好处」加上「未来所有好处的最大值」。
贝尔曼最初提出动态规划时,是为了解决离散的分步决策问题——比如从A到B的最短路径,每一步选左还是选右。但当问题变成连续的(比如导弹的实时轨迹调整,状态和动作都是连续变化的),离散的贝尔曼方程就变成了连续的HJB偏微分方程。
这个方程的神奇之处在于,它既不关心你是在控制导弹,还是在训练AI下棋,只关心一件事:如何在动态变化的环境里,通过每一步的最优选择,最终拿到全局最大的「价值」。这里的「价值」可以是导弹的命中精度,可以是AlphaGo赢棋的概率,也可以是扩散模型生成图像的逼真度。
过去几十年里,工程师们一直被HJB方程的「维数灾难」困扰——状态变量一多,方程就变得根本解不出来。直到深度学习出现,用神经网络去近似方程的解,才终于打开了这扇门。
强化学习是HJB方程第一次在AI领域的大规模应用。当我们训练机器人走路时,其实就是在让神经网络逼近HJB方程的解:每一个关节角度是「状态」,每一次肌肉发力是「动作」,机器人走得稳不稳是「价值」。强化学习里的价值网络,本质上就是HJB方程里的价值函数近似;而策略网络,就是从价值函数里推导出来的最优控制策略。
比如DeepMind训练机器人抓握物体,用的DDPG算法,其实就是在解带约束的HJB方程——既要抓住物体,又不能把它捏碎。而SAC算法里的熵正则化,不过是给HJB方程加了一项「鼓励探索」的惩罚项,让机器人不会过早陷入局部最优。
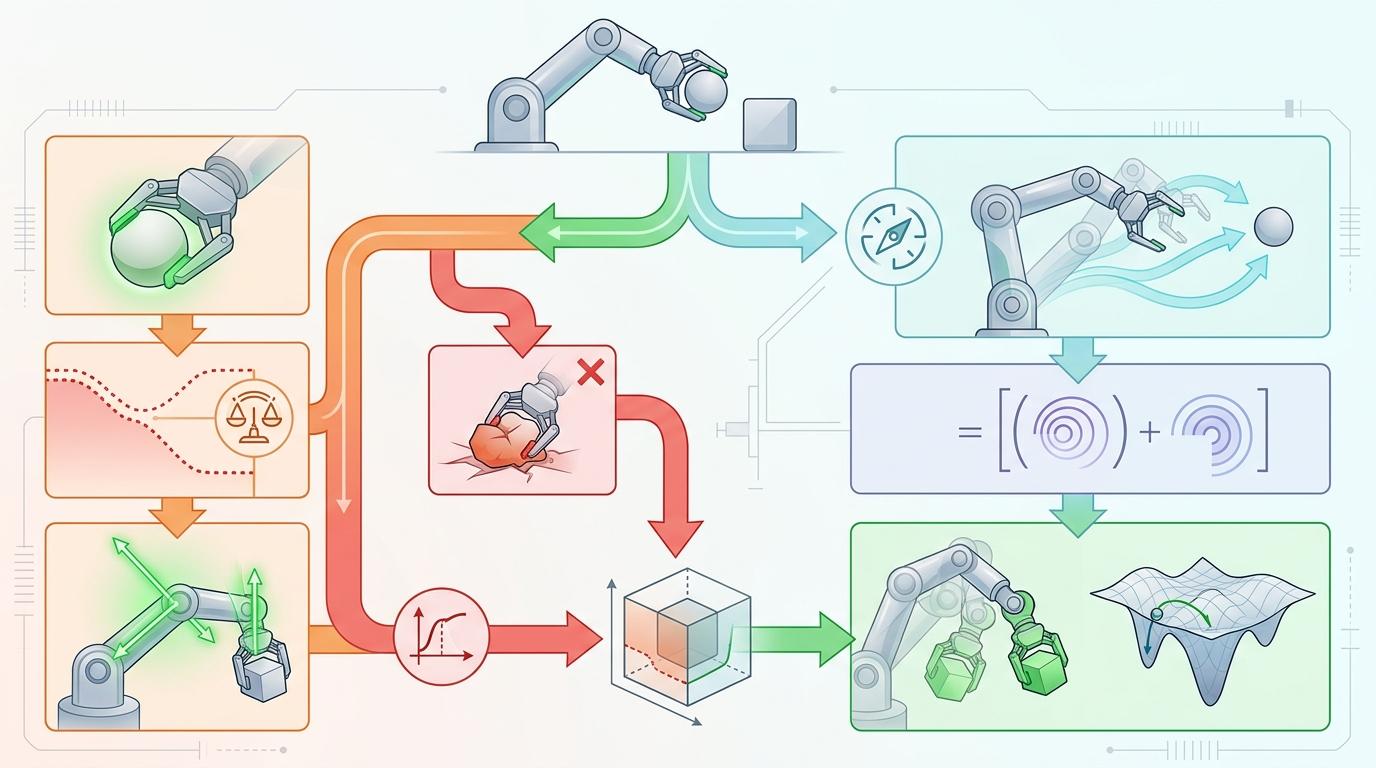
更让人意外的是,今天最火的扩散模型,居然也能用HJB方程来解释。你可以把扩散模型的生成过程看成一个「反向的最优控制问题」:正向过程是给图像加噪声,把它变成随机分布;反向过程则是通过每一步的最优「去噪动作」,把噪声还原成逼真的图像。这里的「价值函数」就是图像的负对数概率,而每一步的去噪策略,就是HJB方程的最优解。
换句话说,Stable Diffusion画图的过程,和机器人走路的过程,在数学上是一模一样的——都是在解HJB方程。
HJB方程的真正威力,在于它能把「理论最优」变成「现实可用」。在金融领域,用神经网络解HJB方程,能在100维的资产组合空间里找到最优配置策略——这在过去是根本不可能的事。比如Merton投资组合问题,传统方法只能解3维以内的情况,现在用深度学习能轻松处理几十维的资产。
在机器人领域,HJB方程让机器人学会了「安全最优」——不仅要完成任务,还要避开障碍物、保证自身稳定。比如NASA用HJB方程优化火星探测器的着陆轨迹,能在燃料有限的情况下,同时避开岩石和保证着陆精度。

当然,HJB方程的落地也不是没有挑战。用神经网络近似方程的解,虽然解决了维数灾难,但也带来了新问题:如何保证解的稳定性和收敛性?如何在样本有限的情况下,快速逼近最优解?这些都是当前研究的热点。
不过,最让人兴奋的是,HJB方程正在成为连接不同AI领域的桥梁。现在已经有研究把扩散模型和强化学习结合起来,用扩散模型生成机器人的运动轨迹,再用强化学习优化轨迹的可行性——这就是HJB方程的跨界魔法。
当我们惊叹AI的神奇时,常常忘记它背后的数学基础其实已经存在了几十年。HJB方程就像一位沉默的老工匠,从冷战时期的导弹实验室,走到今天的AI实验室,一直在用同一个逻辑,解决着不同时代的「最优决策」问题。
真正的智能,从来不是什么玄而又玄的黑魔法,而是在动态变化的环境里,每一步都做出最优选择的能力——这正是HJB方程告诉我们的道理。
所有智能的本质,都是在解同一个方程。