
1 个月前
1 个月前
祖母家的衣柜里翻出1351张无标签老照片——从祖父母20岁的青涩面孔,到我中学时的糗样,横跨半个世纪的影像全是散乱的碎片。没有EXIF元数据标注时间,婚礼照片的顺序全凭猜测,那些闪现在脑海里的故事像抓不住的烟。直到坐在祖母身边听她逐张讲述,沉睡了50年的细节才重新醒来,我记满了三页纸的笔记,却没想到这会变成一场用技术重建记忆的实验。
我克隆了MediaWiki搭建本地维基,像编辑百科条目一样整理这些记忆。先给每张扫描照片配上祖母口述的时间、人物和背景,再用超链接把人物、地点甚至当时的社会事件——比如和婚礼相关的法律修正案——连到公开维基的对应页面。原来维基的架构天生适合做这件事:讨论页用来补全记忆缺口,分类系统按主题归档家族事件,修订记录能追踪每段故事的完善过程,我不用从零搭建任何功能,现成的工具就把碎片化的记忆织成了网。
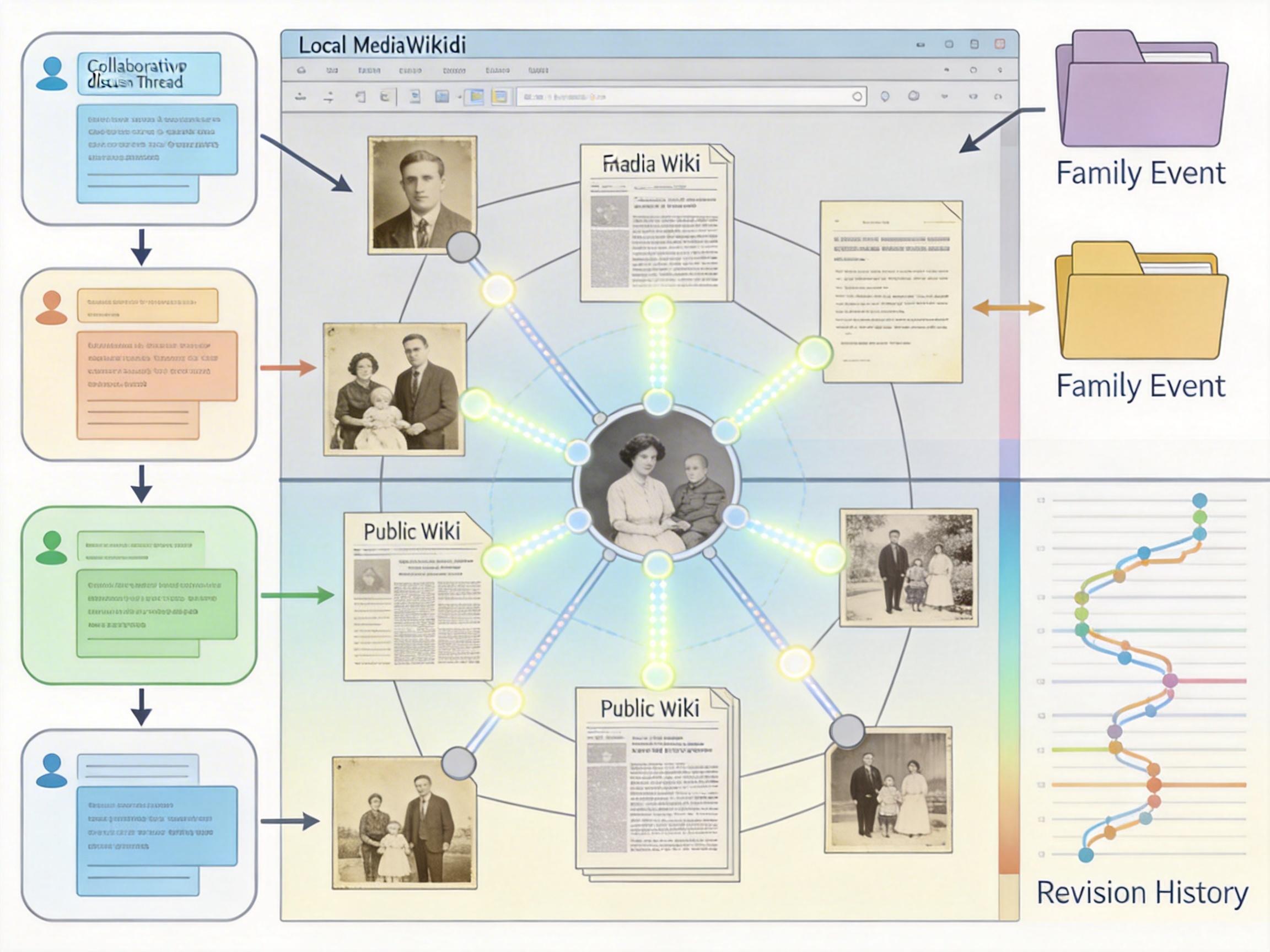
真正的突破来自和语言模型的结合。当我把2012年科格旅行的625张无地理信息照片丢给模型,它靠识别画面里的茶园、建筑甚至车牌,还原出了完整的每日行程;再导入墨西哥旅行的银行流水、Uber记录和Shazam歌单,它能交叉比对出我在哪家餐厅吃了塔可,甚至把餐厅里播放的古巴歌曲和当时的场景对应起来。最意外的是,它从Facebook和WhatsApp的十年聊天记录里,梳理出我和朋友从青涩到成熟的友谊弧线,那些我早已遗忘的深夜倾诉,被编成了像熟人写的传记。
这背后藏着两个关键技术的协同:MediaWiki的结构化框架负责把记忆钉在固定的「坐标」上,避免像散沙一样流失;语言模型则扮演「记忆侦探」的角色——它能跨越照片、文字、交易记录等不同数据源,推理出我手动永远发现不了的关联:比如祖父母婚礼上的歌手,竟是当年帮我接生的护士。而EXIF元数据这个数字时代的「隐形标签」,成了新旧记忆的分水岭:老照片要靠口述补全,数字照片却能自动锚定时间和空间。
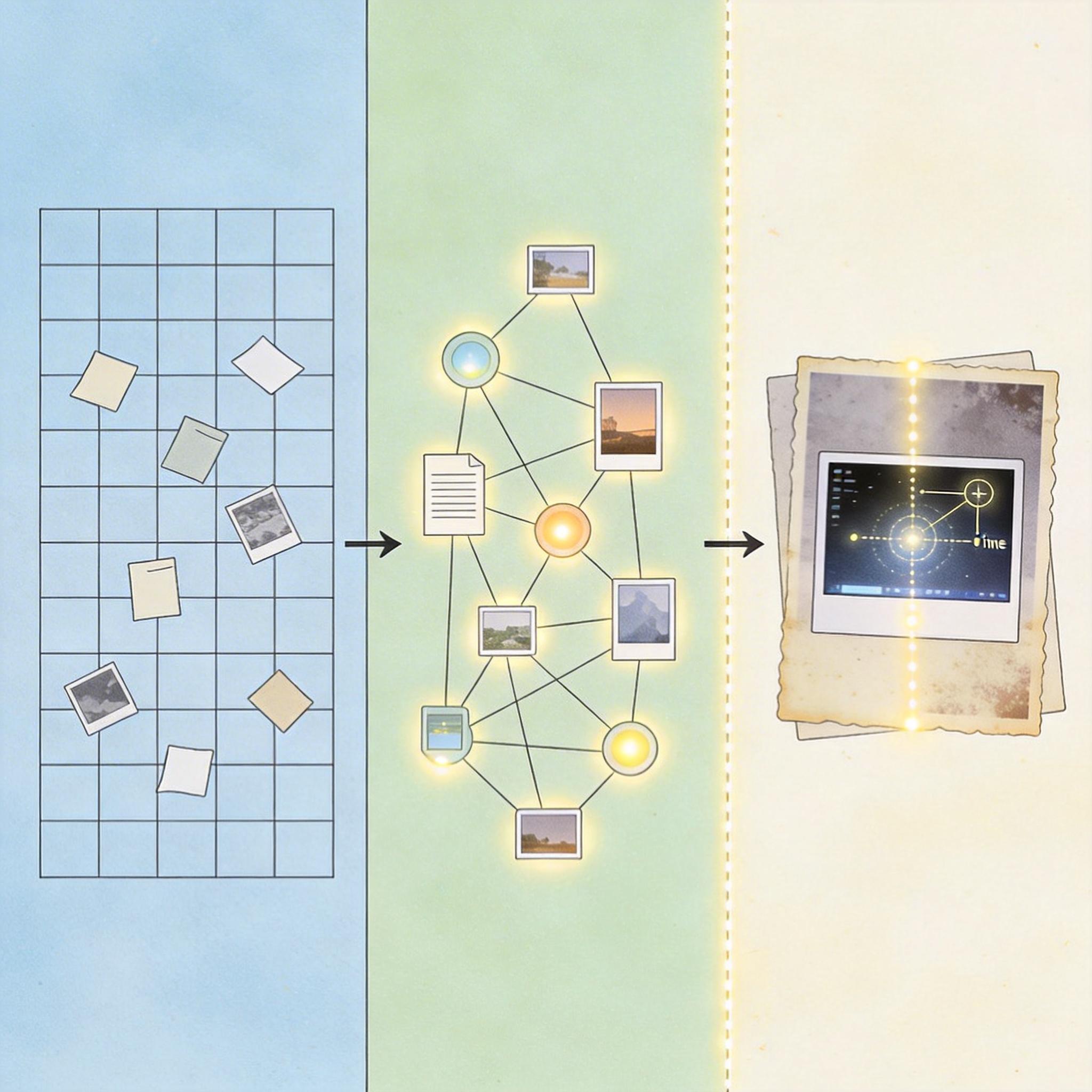
但这种技术也有不能逾越的边界。语言模型偶尔会编造不存在的细节,那些「幻觉」需要人工核对才能剔除;更重要的是,人类记忆里的情感温度,是技术永远无法替代的——祖母讲述婚礼时发亮的眼睛,提到故去亲友时的停顿,这些是任何算法都生成不了的「元数据」。而且当所有记忆都被外化到数字系统里,我们会不会像依赖手机通讯录一样,慢慢丧失记住细节的能力?
当我把打印好的家族维基页面递给祖母时,她摸着照片上年轻的自己,反复读了三遍。这时候我才明白,我们不是在做一个技术实验,而是在把易逝的记忆,变成可以触摸、可以传承的实体。未来的某一天,当我的孩子翻出这些数字档案,他们能顺着链接找到曾祖母的婚礼,找到我年轻时的旅行,也找到那些藏在数据背后,属于我们家的温度。
记忆从来不是冰冷的数字,而是被反复讲述的故事。技术只是帮我们把故事钉牢,不让它被时间吹散。
点击充电,成为大圆镜下一个视频选题!