对抗知识焦虑,从看懂这条开始
App 下载
Kula用环形缓冲,把Linux监控变极简
实时仪表盘|本地数据存储|环形缓冲|Linux监控工具|Kula|软件工程|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载实时仪表盘|本地数据存储|环形缓冲|Linux监控工具|Kula|软件工程|前沿科技
想象一下:你刚租了台Linux云服务器,想看看CPU跑了多少、内存剩了多少——不用装数据库,不用配插件,不用等十分钟启动,下载一个8MB的文件,双击就能在浏览器里看到实时仪表盘。甚至断网了也没关系,数据会老老实实存在本地,不会丢。
这不是科幻,是Kula——一款2026年刚诞生的Linux监控工具。它打破了「监控工具必须复杂才能好用」的惯性,只用一个二进制文件,就搞定了从数据采集到可视化的全流程。但最核心的秘密,藏在它那套多层环形缓冲存储里——为什么这个看似古老的数据结构,能让Kula做到零依赖还能高效存数据?
要理解Kula的核心,得先搞懂环形缓冲(Ring Buffer)——你可以把它想象成一个环形的跑道,数据像运动员一样沿着跑道跑,跑到终点就立刻回到起点,覆盖最老的记录。它的大小是固定的,一旦建好就不会变,既不会突然占满磁盘,也不用频繁申请内存。
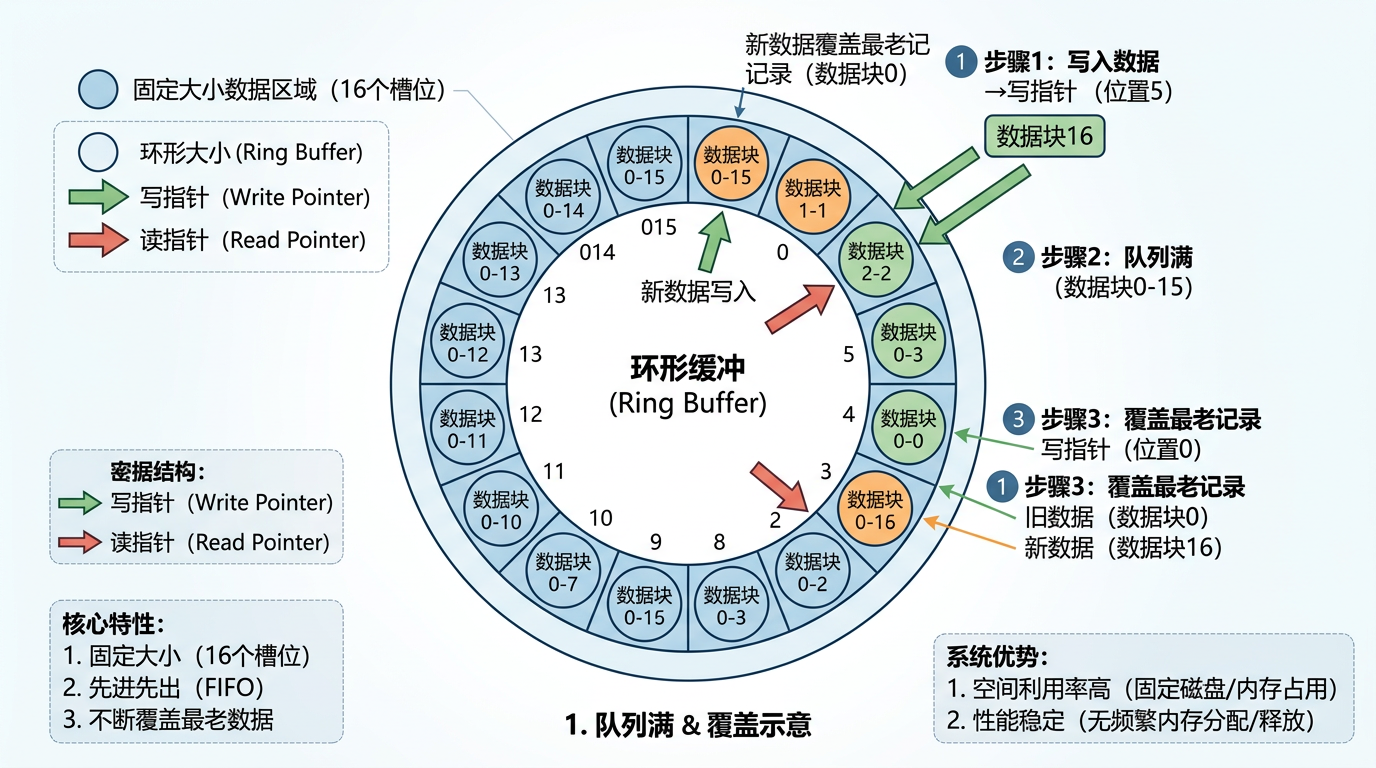
但Kula玩出了新花样:它给这个跑道分了三层。
第一层是1秒粒度的原始数据,默认占250MB——相当于把服务器的每一次呼吸都精准记下来;第二层是1分钟的聚合数据,占150MB,把每秒的波动揉成一个平均值,省空间还方便看趋势;第三层是5分钟的聚合数据,只占50MB,用来存几个小时甚至几天的历史趋势。
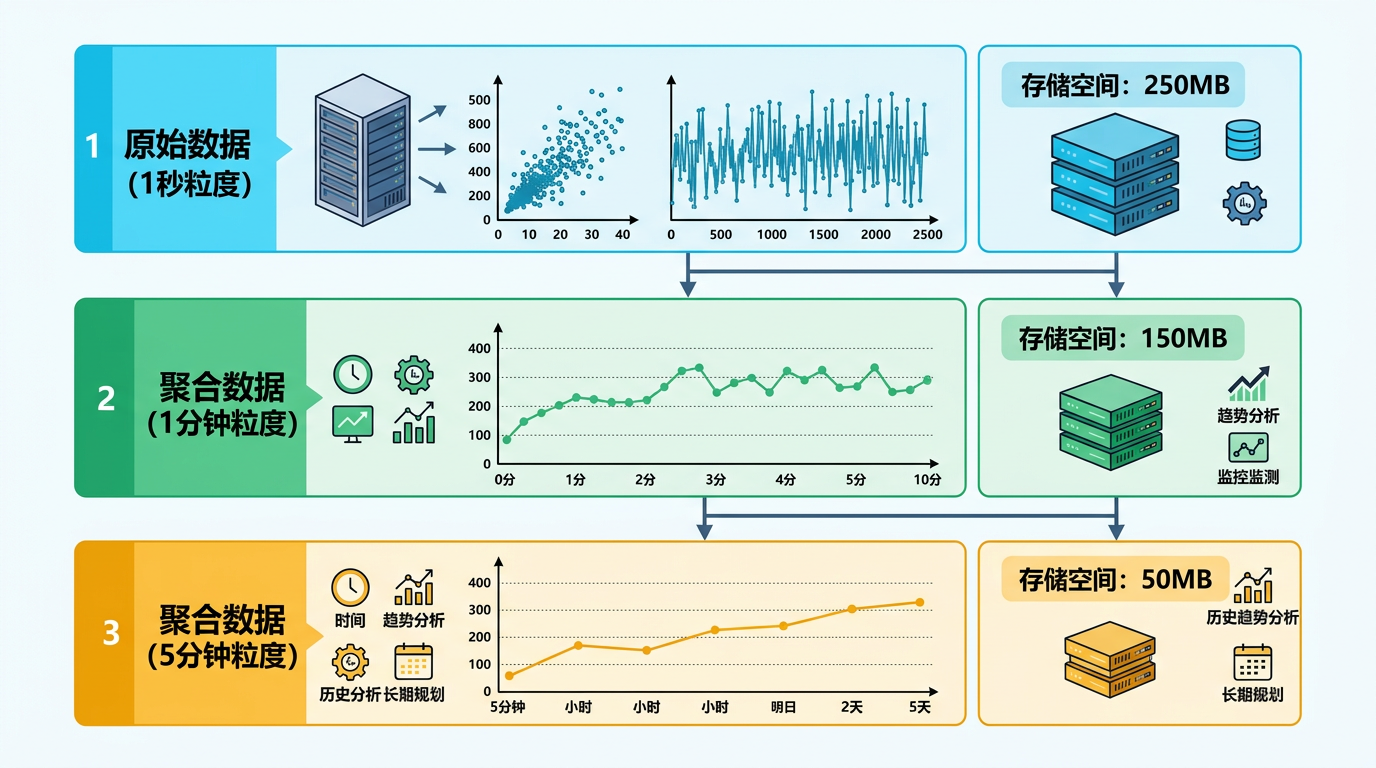
每一层都是独立的环形文件,写满了就自动覆盖最老的内容。这种设计的好处是,你永远不用担心监控数据把磁盘撑爆——总占用量固定在450MB,就像给数据建了个带围墙的院子,再怎么闹也跑不出去。
Kula能做到零依赖,不止靠环形缓冲,还得从它的「吃饭方式」说起。
Linux服务器本身就藏着一个监控宝库——/proc和/sys虚拟文件系统。这些不是真正的文件,是内核实时生成的系统快照,打开就能看到CPU的每一个核心、内存的每一块使用情况、磁盘的每一次读写。Kula做的,就是每秒直接读这些文件,不用装任何代理或插件——相当于直接从厨房的菜篮子里拿菜,不用经过中间商。
读来的数据会先打包成一个个标准的「样本结构体」,然后直接丢进环形缓冲的第一层。后台会自动把第一层的原始数据聚合成第二层、第三层的平均值,整个过程都在Kula内部完成,不用依赖外部数据库。
最绝的是,它连Web界面都打包进了二进制文件里。你启动Kula后,直接在浏览器输localhost:8080,就能看到实时仪表盘——用WebSocket推数据,延迟不到1秒;想看历史数据,直接从环形缓冲里读,比查数据库快得多。甚至还能直接在终端用TUI界面看,连浏览器都不用开。
监控工具本身的安全,一直是个容易被忽略的问题——毕竟它掌握着服务器的所有数据。Kula用了Argon2id密码哈希算法,这是目前最安全的密码存储方式之一,专门针对GPU暴力破解设计。你可以给仪表盘加密码,而且密码不会明文存储,只会存经过哈希和加盐后的字符串。
更贴心的是,Kula允许你根据服务器的硬件调整哈希参数——比如CPU核多就加线程数,内存大就加内存成本,让安全和性能达到平衡。它甚至会提醒你把配置文件的权限改成0600,防止别人偷看密码哈希。
至于性能,Kula自己的资源消耗低到可以忽略不计——平时只占不到1%的CPU,几MB的内存。它的环形缓冲用了内存映射文件技术,读写就像操作内存一样快,而且是无锁设计,多线程写数据也不会卡。官方的测试显示,它每秒能处理上万条数据,比传统的监控工具快好几倍。
在监控工具越做越复杂的今天,Kula像一股清流——它没有追求大而全的功能,而是把「极简」做到了极致:一个文件、零依赖、固定磁盘占用,却能满足绝大多数Linux服务器的监控需求。
这背后其实是一种回归:监控工具的本质,是帮你了解服务器的状态,而不是给你添乱。Kula用环形缓冲这个古老的数据结构,解决了现代监控的核心痛点——数据存储的效率和可控性。
**好的工具,应该像空气一样存在。**当你需要它时,它就在那里;当你不需要它时,你甚至感觉不到它的存在。Kula做到了这一点,而这,可能就是未来监控工具的方向。