对抗知识焦虑,从看懂这条开始
App 下载
AI能精准预测,但给不出科学的答案
科学可解释性|神经元放电|蛋白质结构预测|AlphaFold|脑科学|大语言模型|心理认知|人工智能
对抗知识焦虑,从看懂这条开始
App 下载科学可解释性|神经元放电|蛋白质结构预测|AlphaFold|脑科学|大语言模型|心理认知|人工智能
2021年,AlphaFold把人类蛋白质组的结构预测精度推到了接近实验的水平,300万科研人员靠它加速药物研发、解析疾病机制,甚至拯救濒危蜜蜂。但没人能说清它是怎么做到的——输入一串氨基酸序列,它吐出精准的3D结构,却没留下任何能被人类内化的原理。就像你拿到了一份完美的考卷答案,却不知道每道题的解题思路。更让人不安的是,神经科学、天文学等领域的AI正沿着同一条路狂奔:它们能预测神经元放电、行星轨道,却跳过了科学最核心的那一步——把复杂现象熬成简单原理。
1952年,霍奇金和赫胥黎用四个微分方程,不仅精准预测了鱿鱼神经细胞的动作电位波形,还讲清了背后的机制:钠离子快速内流、钾离子缓慢外流,两种离子的推拉形成了神经信号。这个模型像一把钥匙,打开了整个计算神经科学的大门——后来的科学家能顺着它,理解不同神经元的放电模式、神经网络的节律生成,甚至设计人工神经假体。
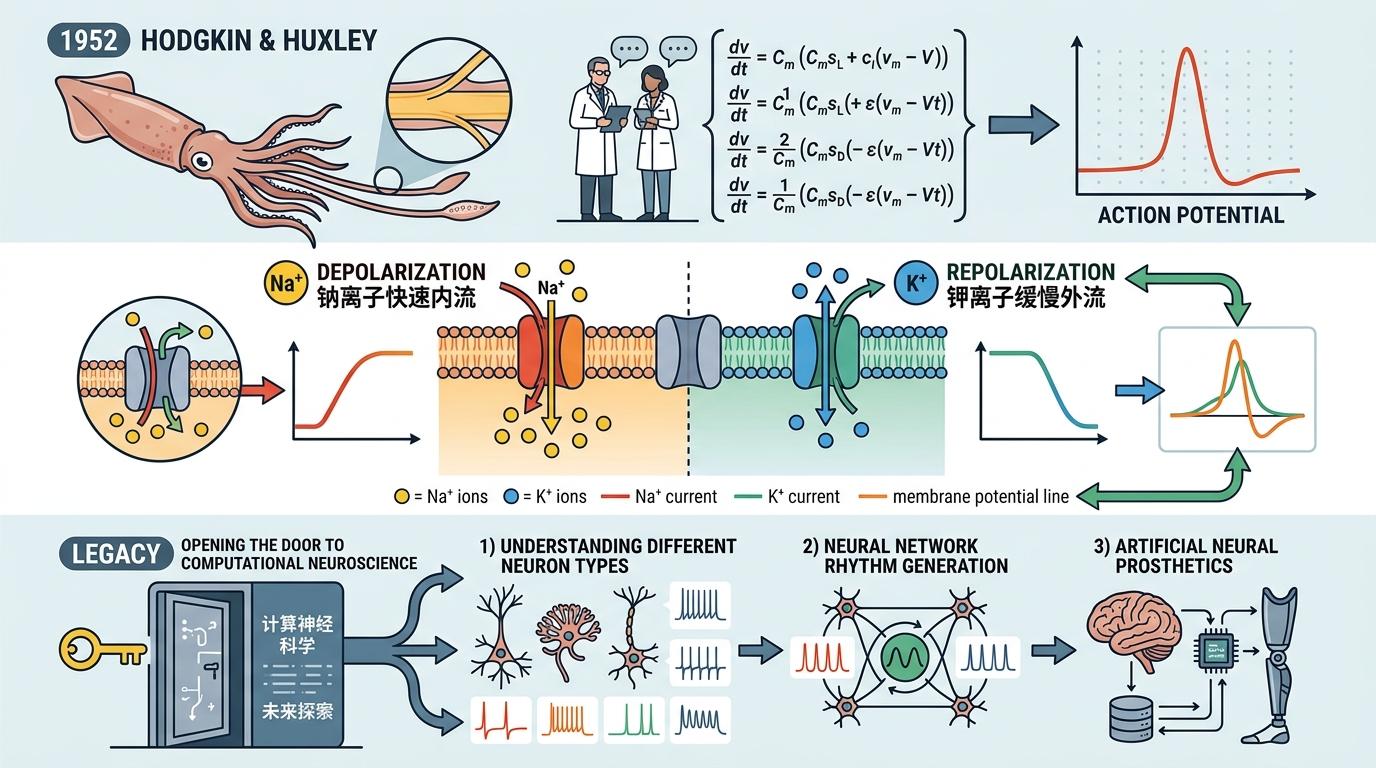
这就是科学的传统:预测和理解是一枚硬币的两面,而理解的核心是「理论压缩」——把海量观测数据蒸馏成简洁、可迁移的原理。就像牛顿用万有引力定律,把天体运动、苹果落地、潮汐涨落这些风马牛不相及的现象,统一成了一个公式。这种压缩不是为了省事,而是让知识能装在人类的脑子里,能跨领域迁移,能催生新的创新。
但AI打破了这个传统。AlphaFold用的是深度学习模型,它在数亿个蛋白质结构数据里找规律,最终的预测模型包含数十亿参数,没有人类能看懂它的内部逻辑。它跳过了「蒸馏」的步骤,直接给你答案——你不用理解蛋白质怎么折叠,只要相信它的预测就行。
MIT的Keyon Vafa团队做过一个扎心的实验:他们用Transformer模型预测行星轨道,给它喂了数千万条模拟的行星运动数据。模型的预测精度极高,甚至能精准算出某颗行星在100年后的位置。但当研究者让它推导背后的物理规律时,模型给出的结果却乱七八糟——在不同的训练样本里,它「发明」了不同的引力公式,没有一个符合牛顿的万有引力定律。
这像极了1400年前的托勒密。他用层层叠叠的「本轮」和「均轮」,精准预测了行星的位置,但这套模型只是对观测数据的拟合,完全没触及天体运动的本质。直到牛顿用万有引力定律把所有行星的运动统一成一个公式,人类才真正理解了太阳系。
现在的AI就是更聪明的托勒密。它能拟合数据、精准预测,但学不会提炼普适原理。在神经科学领域,Transformer模型能预测神经元群体的放电模式,却没法解释神经回路到底在计算什么;在药物研发领域,AI能筛选出潜在的药物分子,却没法说清这个分子为什么能作用于靶点。我们原本看不懂大脑,现在连AI做的大脑模型也看不懂了——相当于在未知的黑箱外面,又套了一层黑箱。
为了撬开AI这个黑箱,「机械可解释性」这个新领域诞生了。它的目标不是简单解释AI的输入输出关系,而是像逆向工程一样,拆解AI的内部计算,找到它用来做决策的「特征」和「电路」——就像神经科学家通过电极记录,找到大脑里负责识别边缘、颜色的神经元。
稀疏自编码器是目前最热门的工具之一。它能把AI模型里复杂的激活向量,分解成一个个稀疏的、可解释的特征。比如在分析处理钙成像数据的Transformer模型时,研究者用稀疏自编码器找到了对应特定神经元放电模式的特征——这些特征就像AI模型里的「神经元」,能让人类看懂它是怎么处理神经数据的。
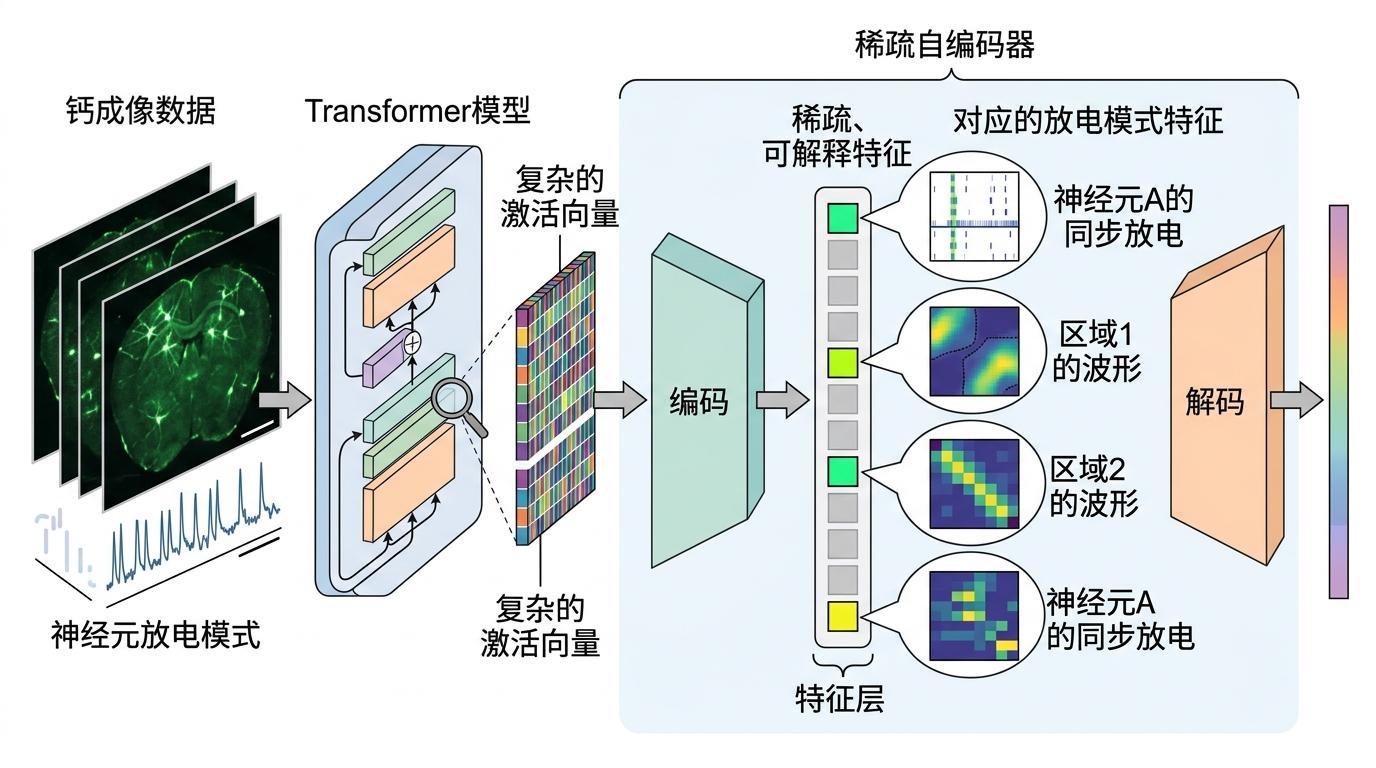
但这又是一个新的讽刺:我们现在需要用科学方法,去研究我们自己造出来的科学工具。而且这条路才刚刚起步——目前的研究只能拆解小规模的AI模型,面对GPT-4、Claude这种千亿参数的大模型,机械可解释性还力有不逮。更关键的是,就算我们能拆解出AI的内部特征,这些特征也未必符合人类的认知习惯——就像你能拆解一台电脑的电路,但这和理解电脑怎么运行操作系统,还差得远。
AI正在变成科学研究里的「超级实习生」:它能帮你处理海量数据、生成初步假设、甚至设计实验,但它没法帮你完成最核心的那一步——把零散的事实,编织成一张能解释世界的知识网。
预测是答案,压缩才是知识。 这句话或许能概括我们现在的处境:AlphaFold们能给我们答案,但只有人类能把答案变成知识。未来的科学研究,应该是AI和人类的协同——AI负责在数据的海洋里捞鱼,人类负责把捞上来的鱼做成能吃的菜,甚至提炼出养鱼的方法。
毕竟,科学的终极目标从来不是精准预测,而是理解世界。如果我们只满足于答案,而放弃了追问「为什么」,那我们和只会按按钮的机器,又有什么区别?