对抗知识焦虑,从看懂这条开始
App 下载
给AI做认知体检,我们离AGI更近了
DeepMind|OpenAI|AI体检流程|认知能力分类论文|GPT-5|认知决策|大语言模型|心理认知|人工智能
对抗知识焦虑,从看懂这条开始
App 下载DeepMind|OpenAI|AI体检流程|认知能力分类论文|GPT-5|认知决策|大语言模型|心理认知|人工智能
2026年的今天,你能让GPT-5写一篇博士级的论文摘要,能让多模态AI精准识别X光片里的病灶,但你说不清这些AI到底算不算“聪明”——就像你没法用“会做数学题”来定义一个人的智商。过去十年,AI在单一任务上的突破像烟花一样密集,但我们始终缺一把能丈量“通用智能”的尺子。直到2024年,OpenAI联合DeepMind、MIT等机构发布了那篇认知能力分类论文,把AGI拆解成10项核心认知能力,还给AI设计了一套对标人类的“体检流程”。为什么这套框架突然让AGI的进度条变得清晰了?
你可以把通用人工智能想象成一个要参加十项全能的运动员——不能只会跑步,也得会跳远、投掷、跨栏。这套认知能力分类法,就是从心理学、神经科学的百年研究里,提炼出了AI要成为“全能选手”必须具备的10项核心能力:从最基础的感知(提取环境信息)、生成(输出内容或动作),到更高级的元认知(监控自己的思考)、社会认知(理解社交规则),每一项都对应着人类智能的一个维度。
这不是拍脑袋的罗列。比如“执行功能”,对应人类的计划、抑制冲动能力——就像你能忍住刷手机的冲动先写完报告,AI也需要能为了长期目标规划步骤,而不是被眼前的任务带偏。“元认知”则是AI的“自我觉察”:知道自己不知道什么,不会在不懂的问题上瞎编答案——这正是当前大模型最缺的“诚实感”。
为了把这些能力落地成可测量的指标,研究者设计了三阶段评估协议:先给AI做一套覆盖所有能力的“认知试卷”,用从未见过的测试题避免作弊;再找一群不同年龄、背景的人类做同样的题,建立“人类平均水平”基线;最后把AI的得分映射到人类的表现分布里——比如AI在“推理”上达到了人类前20%的水平,在“持续学习”上还不如小学生。
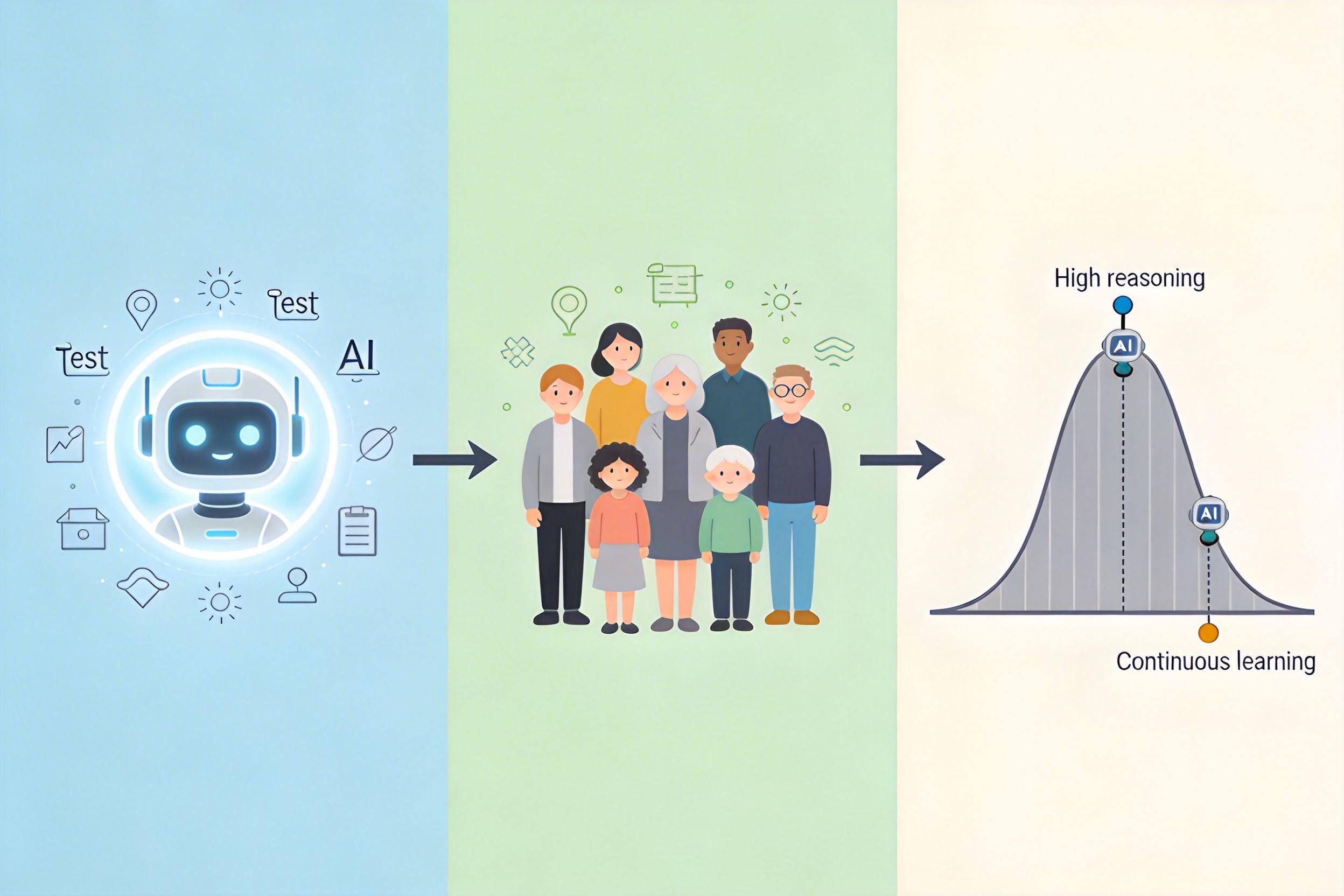
这套框架刚一发布,就被用来给当前最先进的AI做了一次全面体检。结果毫不意外:GPT-5在“推理”“生成”“记忆”上拿到了高分,AGI整体评分达到57%,相当于人类中等偏上的认知水平;但在“持续学习”“社会认知”上,它的得分几乎是零。
持续学习就是AI的“终身学习”能力——现在的大模型一旦训练完成,参数就固定了,没法像人类一样在生活中不断学习新东西,比如你告诉它今天的新热点,明天它还是会忘。这不是因为模型不够大,而是因为当前的AI没有真正的“长期记忆”,只能靠扩大上下文窗口来模拟,本质上还是“查笔记”,不是“记在脑子里”。
更值得关注的是,这套框架第一次把“社会认知”拉到了AGI评估的核心位置。比如让AI判断一段对话里的讽刺语气,或者根据对方的情绪调整回答方式,当前的大模型要么完全没get到,要么给出的回应像个生硬的客服。这也解释了为什么我们和AI聊天总觉得“差点意思”——它能听懂字面意思,却读不懂背后的社交潜规则。
为了让这套框架从理论变成可操作的工具,OpenAI联合Kaggle发起了一场认知能力评测黑客松,全球数千名开发者围绕“学习”“元认知”等5项最薄弱的能力,设计了上百种测试任务。
有团队设计了一套“持续学习测试”:让AI在不断接触新单词的同时,还要记住之前学过的内容,最后看它能记住多少——结果最好的模型也只能记住30%的旧知识,而人类的遗忘曲线是缓慢下降的。还有团队用多模态数据测试“社会认知”:给AI看一段包含肢体语言的视频,让它判断对话双方的关系,准确率最高的模型也只有62%,远低于人类的平均水平。
这些测试不是为了“考倒”AI,而是为了找到精准的改进方向。比如针对持续学习的短板,研究者开始尝试给AI加一个“记忆银行”,像人类的海马体一样存储和检索长期记忆;针对社会认知的不足,有的团队开始用真实的人类对话数据训练AI,让它学习更自然的社交反应。
当我们开始用“认知体检”的方式丈量AGI,其实是在重新定义“智能”——它不是单一任务上的极致表现,而是像人类一样,能在不同场景下灵活调用不同的认知能力。
“智能的本质,是适应与整合。”这是认知科学里的一句老话,现在成了AGI最清晰的方向标。我们不用再纠结“AI什么时候能超过人类”,而是要盯着每一块“认知肌肉”的成长:当AI能记住昨天的对话,能读懂你的讽刺,能为了一个目标规划一周的步骤时,AGI就真的离我们不远了。
毕竟,真正的智能从来不是“满分试卷”,而是能在复杂的真实世界里,好好活下去。