
16 天前
16 天前
当你让AI写一篇10万字的调研报告时,它的“临时记忆”——也就是Key-Value缓存——会像吹气球一样膨胀,占满GPU的内存空间,最后要么卡顿要么直接罢工。这是大语言模型长上下文推理的死穴:缓存越大,能处理的文本越长,但硬件成本也会跟着翻几倍。
现在有人把这个死穴给通了。Google Research的团队推出了一套叫TurboQuant的算法,能把AI的缓存体积直接压到原来的1/6,关键是——模型的回答精度没降,甚至推理速度还快了8倍。
这不是简单的“挤水分”,而是换了一种思路来给数据“打包”。问题是,他们怎么做到的?
要理解TurboQuant的厉害,得先搞懂之前的方法卡在哪。AI处理信息靠的是高维向量——你可以把它想象成一串很长的数字密码,每个数字代表文本的一个特征,比如“情感是正面的”“提到了苹果公司”。这些向量越长,能装的信息就越多,但占的内存也越大。
为了压缩向量,行业里一直用**向量量化**技术:把连续的数字密码转换成有限的离散符号,就像把渐变的彩虹色转换成有限的调色板颜色。但传统方法有个致命的bug:为了让压缩后的向量能还原出足够准确的信息,必须额外存一套“解码钥匙”——也就是每个数据块的量化常数。这些钥匙本身又会占内存,有时候甚至能吃掉1-2成的压缩收益,等于白忙活一场。
比如你把100G的向量压到了20G,结果解码钥匙又占了5G,实际只省了75G,远不如预期。更麻烦的是,这些钥匙还得用高精度存储,进一步拉高了成本。
这就形成了一个死循环:想压缩得更狠,就得存更多钥匙;存更多钥匙,压缩的意义就变小了。
TurboQuant的破解思路,是从“怎么打包”变成了“怎么拆分”。它把压缩分成了两步,每一步都解决了传统方法的一个痛点。
第一步是用PolarQuant算法,把向量从直角坐标转换成了极坐标。你可以把原来的向量想象成“向东走3米,向北走4米”,转换成极坐标就变成了“向东北方向走5米”——一个代表长度的“半径”,一个代表方向的“角度”。

高维向量有个特性:经过随机旋转后,角度的分布会变得极其集中,就像一群人都朝着同一个方向站着。这时候就不用再给每个数据块存解码钥匙了,因为角度的规律是固定的,直接用通用规则就能解码。这一下就把传统方法的内存开销给彻底抹掉了。

第二步是用QJL算法补误差。第一步压缩后总会剩点小误差,就像打包快递时总会有个小角落没塞满。TurboQuant只花1比特的内存——也就是一个“0”或“1”——就把这些误差给修正了。它用的是Johnson-Lindenstrauss变换,一种能在压缩数据时保持数据间距离关系的数学方法,相当于给快递打了个精准的补丁,既不占地方,又能保证里面的东西完好无损。
有意思的是,整个过程不需要额外训练模型,也不用调参数,拿到任何向量都能直接用——这在工业界太香了,意味着可以直接部署到现有系统里,不用重新训练一遍模型。
Google的团队在多个标准测试集上验证了TurboQuant的效果:在处理长文本的“大海捞针”任务里,TurboQuant把缓存压到原来的1/6,模型找信息的准确率还是100%;在向量搜索任务里,它的召回率比传统的产品量化方法更高,而且建索引的时间几乎为零。
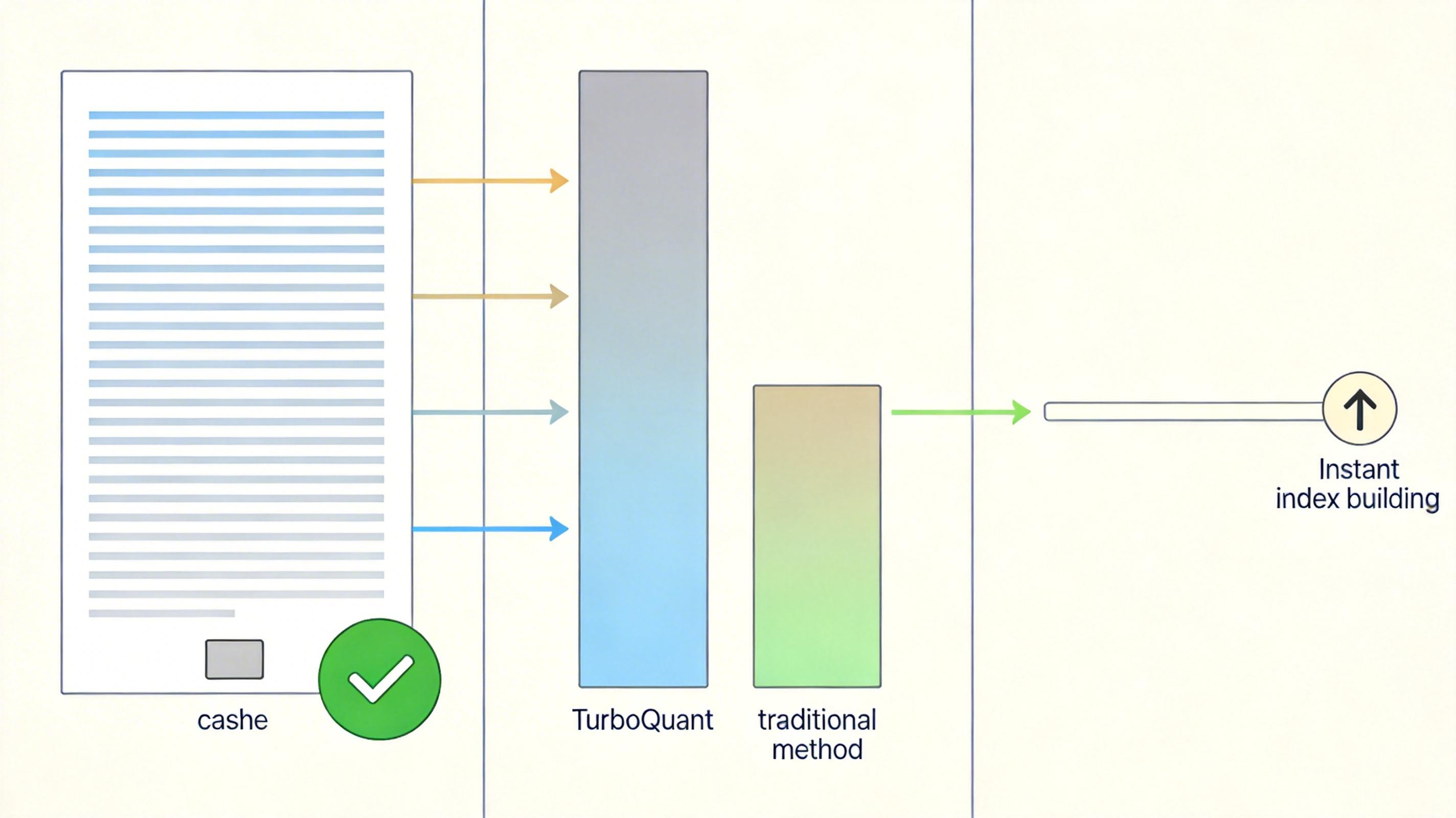
在硬件上,4比特量化的TurboQuant在H100 GPU上计算注意力的速度,是32比特未压缩向量的8倍——相当于原来一辆车跑的路,现在8辆车同时跑,还不堵车。
当然,它也不是万能的。目前TurboQuant主要针对的是AI的缓存和向量搜索,还没用到模型的权重压缩上;另外,虽然它能做到“几乎无损”,但在极端压缩到2.5比特时,还是会有轻微的精度下降,只是这个下降幅度小到可以忽略不计。
更重要的是,这套算法的理论基础很扎实——它的压缩效果接近信息论的理论极限,不是靠“小聪明”凑出来的,而是从数学上证明了可行。这意味着它能适配更多场景,而不是只在特定数据集上好用。
当我们都在盯着AI的“智商”——比如能不能通过司法考试、能不能写代码——的时候,TurboQuant的突破提醒了我们:AI的“体力”同样重要。硬件的瓶颈就像AI的“体力上限”,如果体力跟不上,再聪明的大脑也发挥不出来。
TurboQuant的本质,是用更聪明的数学方法,把硬件的潜力给挖了出来。它没有制造新的硬件,也没有给AI加新的功能,只是让AI能在同样的硬件上做更多的事。
压缩的本质,不是挤水分,而是重新排列信息。 这句话放在AI身上成立,放在我们处理信息的方式上,同样成立。
点击充电,成为大圆镜下一个视频选题!