对抗知识焦虑,从看懂这条开始
App 下载
AI写代码快10倍,开源社区却在拆弹
果冻代码|代码审核|开源治理|AI生成代码|Rust社区|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载果冻代码|代码审核|开源治理|AI生成代码|Rust社区|AI产业应用|人工智能
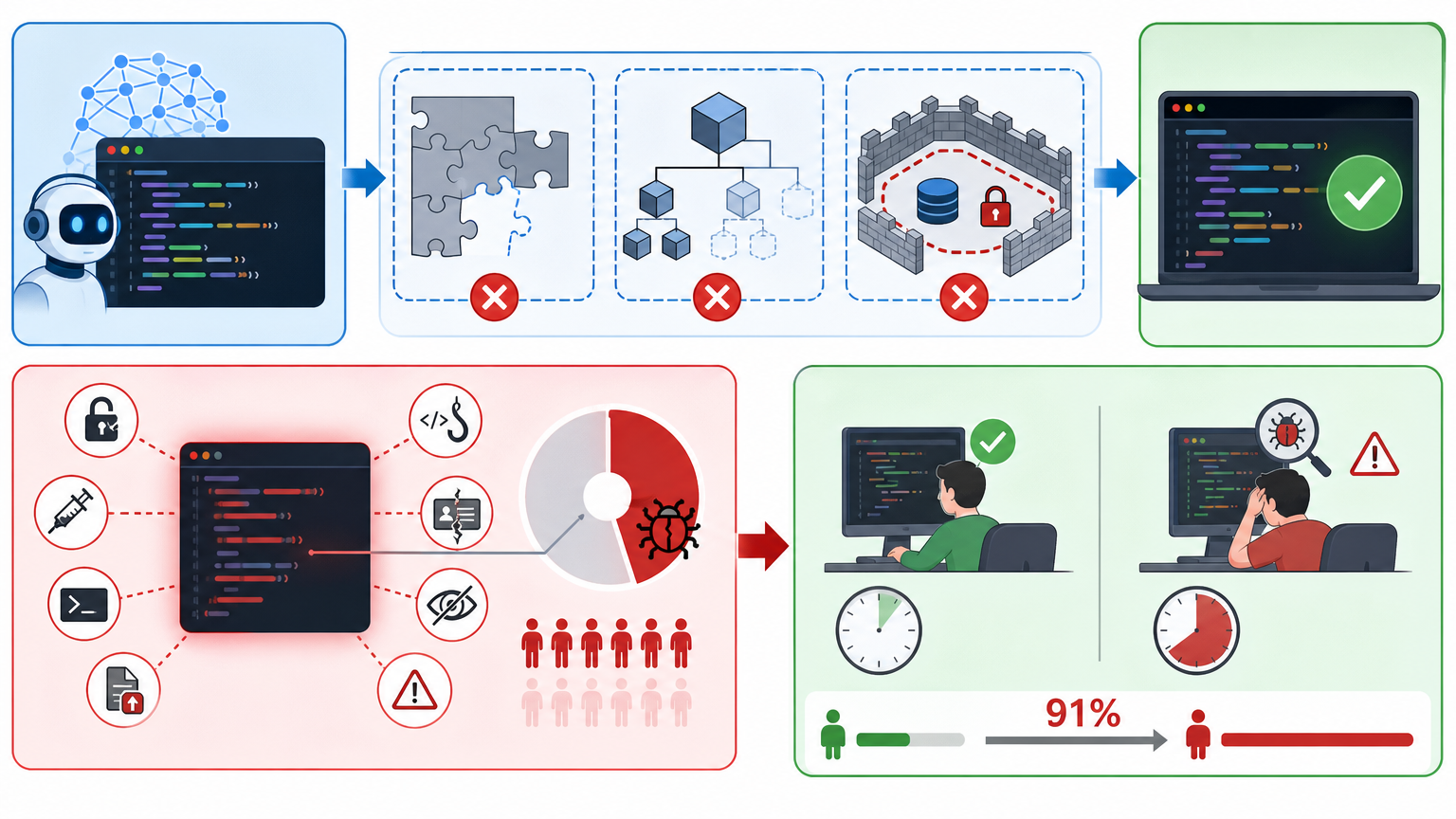
2026年春,Rust社区的维护者们关掉了372个PR——这些代码能编译、能跑通,甚至注释工整,却全被打了回票。原因很简单:它们是AI生成的“果冻代码”——表面Q弹合格,咬开全是架构混乱、逻辑隐患的空心。
就在半年前,开发者还在欢呼AI让写代码效率翻了10倍;现在,开源社区却陷入了一场“拆弹式”的治理战争:一边是AI催生的代码洪水,一边是维护者被拖垮的审核效率。为什么曾经的效率神器,突然成了开源生态的烫手山芋?
你可以把AI生成代码的过程想象成——让一个读过1000本菜谱的厨子,在没见过厨房的情况下给你做菜。它能精准复刻经典菜式的步骤,却不知道你家的锅是粘锅的,火是调不大的,最后端出来的菜,卖相一流却根本没法吃。

这就是“果冻代码”的真相:AI能快速生成符合语法规范的代码,却没有全局架构意识,更不懂项目的业务逻辑和安全边界。Rust社区的统计显示,AI生成的代码里,40%藏着OWASP十大安全漏洞,而维护者要花比审查人类代码多91%的时间,才能揪出这些隐形的坑。
Node.js曾收到一份1.9万行的AI生成PR,贡献者声称已经自我审查,但维护者花了三周才发现,代码里藏着17处架构冲突和8个未授权的依赖调用。最终这个PR被彻底驳回,而维护者为此付出的时间,足够完成3个核心功能的迭代。
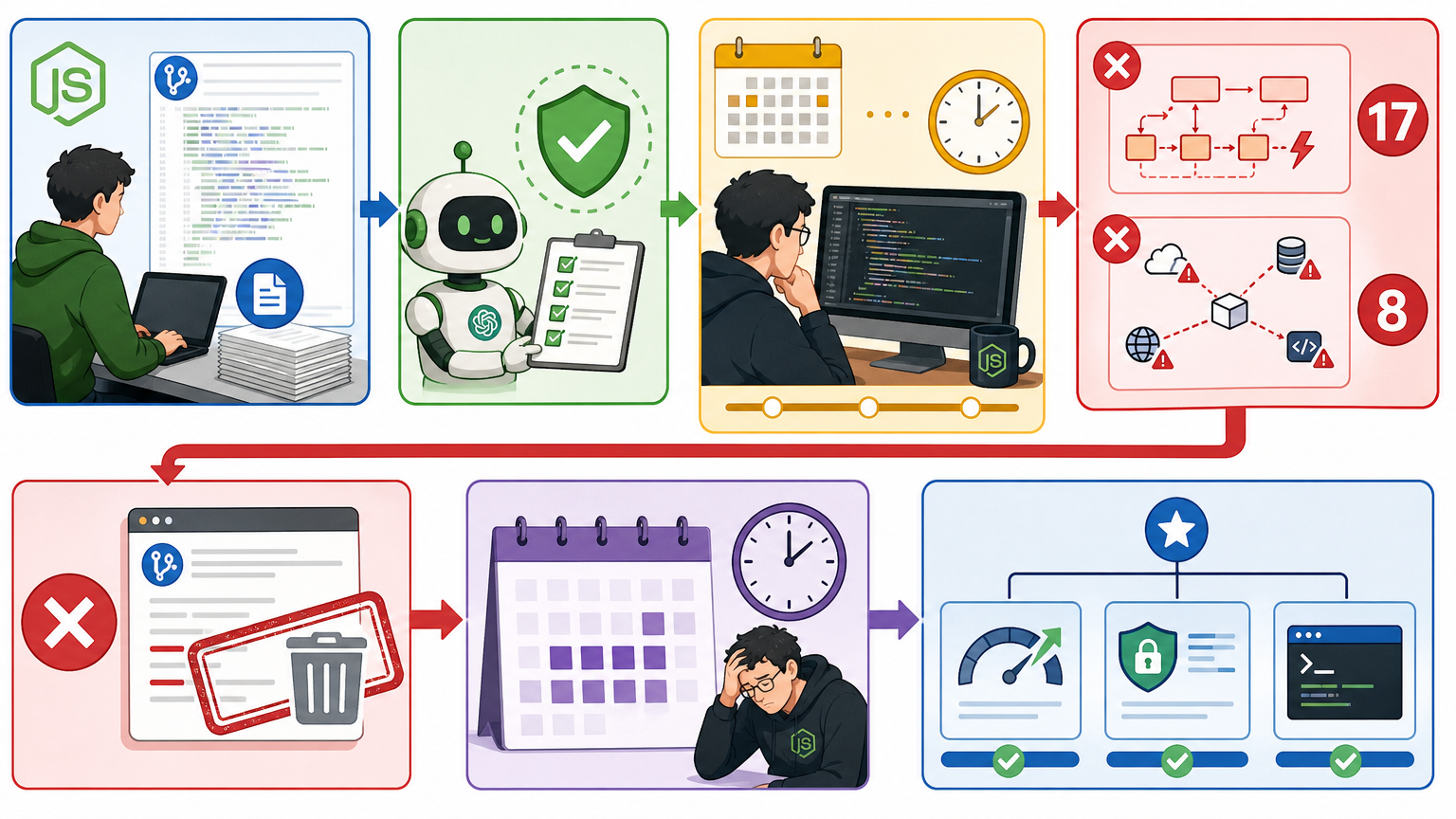
更致命的是,AI代码的“自我解释性”会麻痹开发者——注释写得头头是道,让你以为自己完全理解了代码,直到生产环境崩溃,才发现AI在某个逻辑分支里埋了个没人看得懂的“黑箱”。
面对AI代码的洪水,全球开源社区分化出了三种截然不同的治理路径,本质是在“效率”和“安全”之间找平衡:
以QEMU、NetBSD为代表的项目,直接把AI生成代码列为“污染代码”。QEMU明确规定,任何已知或疑似AI生成的代码都会被拒绝,哪怕贡献者签署了DCO(开发者来源证明)。
他们的逻辑很直接:AI训练数据里混着各种版权不明的代码,一旦引入,未来可能引发无穷无尽的版权纠纷;而维护者没有精力去追溯每一行AI代码的来源。NetBSD甚至要求,即便是经过人工审核的AI代码,也必须获得核心开发者的书面许可才能提交。
Linux内核、LLVM、Fedora等项目选择了“人类在环”的政策:允许用AI辅助开发,但必须满足三个条件:
Assisted-by:标签明确披露AI工具的使用;LLVM甚至专门禁止AI修复“good first issue”——这类问题是给新手留的学习机会,AI自动修复会直接剥夺新手成长的路径。维护者还会给未经充分审查的AI代码贴上“extractive”标签,意思是“提取了维护者的时间,却没带来对等价值”。
Oh My Zsh等项目采取了最宽松的策略:不区分代码是AI还是人类写的,唯一标准是代码质量。但这并不意味着放任自流——他们要求贡献者必须能解释代码的逻辑,一旦发现AI生成的低质量代码,同样会驳回PR。
这种模式看似简单,实则对维护者的能力要求最高:你得有火眼金睛,能从“完美的表面”下揪出AI的漏洞。
在所有治理路径里,“强制披露”是最核心的共识——就像食品包装上的配料表,不是为了批判你用了添加剂,而是让消费者知道自己吃的是什么。
Rust社区的政策里,隐瞒AI辅助贡献会被视为违反诚信原则:轻微的会被要求重新提交带披露的PR,严重的会直接封禁账号。而正确的披露,能让维护者合理分配审查资源——看到Assisted-by: Claude的标签,他们会重点检查代码的架构一致性和安全边界,而不是在语法上浪费时间。
但披露的边界在哪里?用AI查个拼写错误要不要披露?用AI解释一段复杂代码要不要披露?业界目前形成的共识是:只要AI生成了函数、类、测试代码等“实质性内容”,就必须披露;而简单的自动补全、语法检查等“辅助性操作”,则不需要。
有意思的是,开发者对披露的态度正在发生变化。一开始,很多人觉得披露AI使用是“承认自己能力不足”,但现在越来越多的人意识到,这是在保护自己——毕竟,没人想为AI埋的锅背黑锅。
Cloudflare的AI审查系统运行一个月后,完成了13万次审查,平均耗时3分39秒,成本不到1美元。但即便是这样的“智能系统”,也只能发现80%的表面问题,剩下的20%——那些关乎架构、逻辑和业务的核心问题,依然要靠人类维护者的经验和判断。
这就是AI与开源社区的终极平衡:AI是效率放大器,不是责任转移器。当我们欢呼AI让写代码更快的时候,别忘了,开源的本质不是“快”,而是“可信”——每一行代码的背后,都要有能为它负责的人。
AI是工具,可信才是开源的底色。