对抗知识焦虑,从看懂这条开始
App 下载
AI“黑箱”下的信任危机:加密技术如何验明正身?
模型篡改|模型后门|加密技术|模型验证|AI安全治理|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型篡改|模型后门|加密技术|模型验证|AI安全治理|人工智能
当你向一个先进的AI模型发出指令,无论是请求一次关乎巨额资金的金融策略分析,还是辅助医生进行一场性命攸关的医疗诊断,你是否曾想过一个问题:屏幕背后响应你的,真的是你以为的那个模型吗?
在AI服务如水电般融入我们生活的今天,一个根本性的信任鸿沟正在悄然扩大。服务提供商声称你正在使用最新、最强的模型,但你无法验证。你调用的开源模型,真的是社区发布的那个未经修改的精确版本吗?还是一个被悄悄量化、性能缩水,甚至被植入后门的“李鬼”?这种不确定性,在AI扮演决策角色的高风险领域,无异于将信任建立在流沙之上。当输出结果出现偏差时,我们无从得知是模型能力的局限,还是我们从一开始就被“狸猫换太子”。这不仅是技术问题,更是动摇整个AI产业基石的信任危机。
正是为了填补这一信任鸿沟,一家名为Tinfoil的公司推出了名为Modelwrap的解决方案。这并非又一个应用层的安全补丁,而是一套深入系统内核的“可信交付”机制。它的核心承诺简单而强大:通过密码学和系统级强制手段,向用户保证他们每一次调用的,都是一个特定、真实、且未经任何篡改的模型权重集合,并且,用户可以在客户端自行验证这份承诺。
Modelwrap的出现,相当于为AI模型的交付与运行上了一把看不见的、却坚不可摧的“锁”。它试图从根本上回答那个直击人心的问题:如何确保AI的“灵魂”——它的模型权重——在从发布到运行的整个生命周期里,始终保持其本来的面目?
要理解Modelwrap如何实现这一承诺,我们需要深入其技术内核,那里有两种久经考验的“炼金术”正在协同工作:默克尔树(Merkle Tree)和dm-verity。
想象一下,一个140GB的大模型权重文件是一座巨大的图书馆。要证明馆中藏书未被篡改,传统方法是逐字核对,效率极低。默克尔树提供了一种天才的解决方案:
这个“树根指纹”就是模型的公开承诺。任何一页书中的一个标点符号被改动,都会引起连锁反应,最终导致树根指纹的彻底改变。这使得验证庞大数据变得极为高效。
然而,有了指纹还不够,谁来强制执行每一次核对?这时,dm-verity这位“图书管理员”登场了。它不是一个普通的管理员,而是直接在操作系统内核中工作的“系统级宪兵”。当AI应用(如vLLM)需要读取图书馆的某一页(加载模型权重)时:
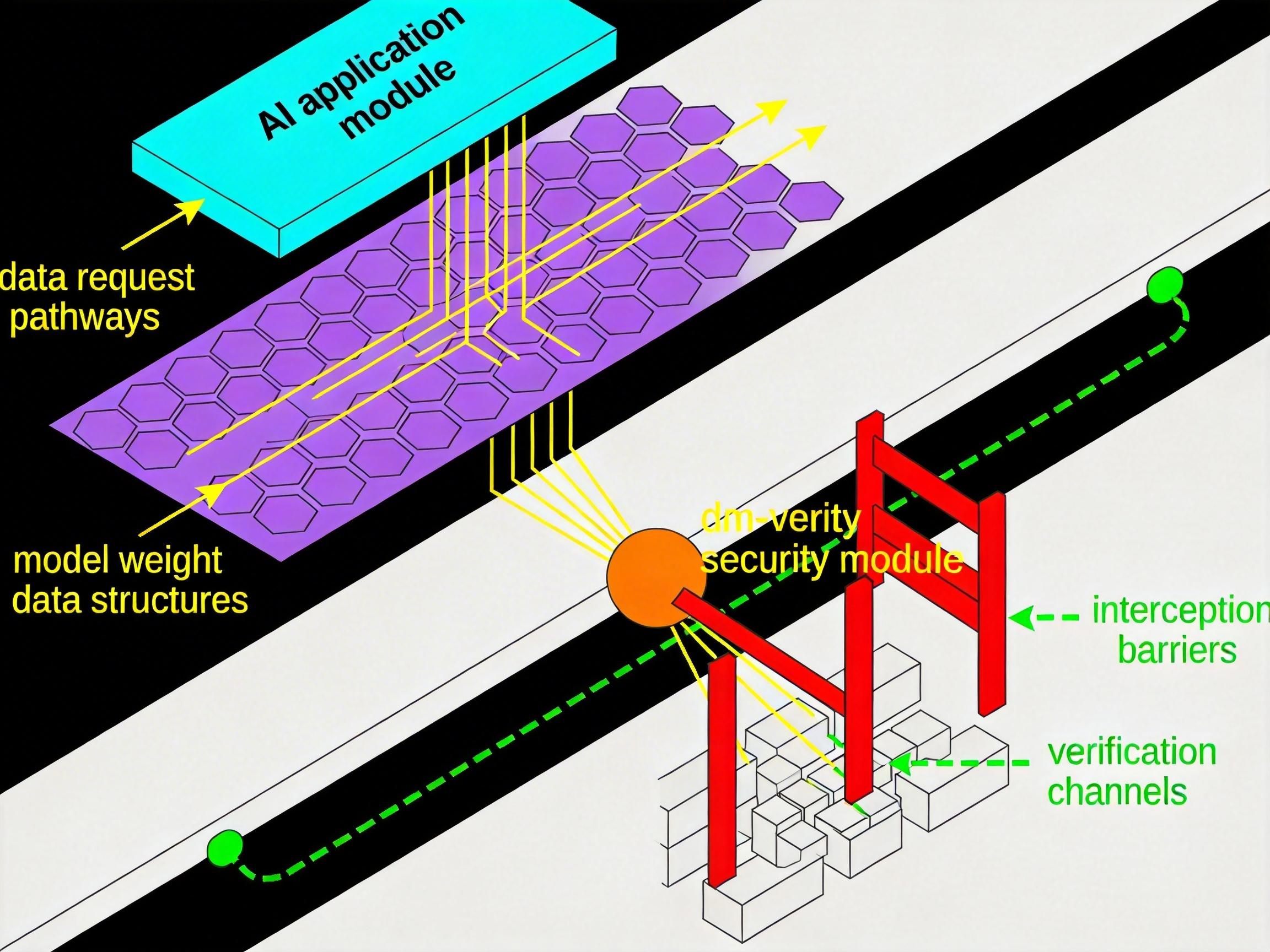
整个过程对上层应用完全透明,无需修改一行AI框架代码。这套机制的巧妙之处在于,它将信任的根基从对服务商的“相信”,转移到了对数学和底层代码的“可验证”。
Modelwrap的创新并非凭空而来,而是巧妙地将一项成熟的操作系统安全技术应用到了AI领域。dm-verity自2013年起就被用于安卓系统的“验证启动”(Verified Boot)机制,每天在全球数十亿台设备上保护着系统分区不被恶意软件篡改。每一次安卓手机的开机,背后都有这套机制在默默守护。
Tinfoil团队的洞察在于,他们发现AI模型权重与操作系统镜像具有惊人的相似性:它们都体积庞大、在运行时只读,并且对完整性有着极高的要求。 既然dm-verity能为手机操作系统保驾护航十余年,它同样能成为守护AI模型纯洁性的坚固盾牌。这种借鉴,让Modelwrap天生就站在了巨人的肩膀上,其可靠性已在数十亿设备上得到过验证。
有人可能会问,为什么不直接对模型文件进行数字签名?这确实能验证文件在下载瞬间的真实性。然而,Modelwrap提供的是一种更深层次、更强大的运行时安全。
数字签名好比在包裹上贴封条,它能证明包裹在签收时是完好的。但它无法阻止包裹签收后,有人(例如拥有更高权限的系统管理者或恶意虚拟机监视器)偷偷打开包裹并调换里面的物品。而Modelwrap的dm-verity机制,则相当于在包裹内每一件物品上都刻下了无法磨灭的印记,并且在每次取用时都会自动核验。这种**“持续验证”**的模式,将防御能力从“交付那一刻”延伸到了“使用的每一秒”,有效抵御了更为复杂的供应链攻击和运行时篡改风险。

当然,这种强度的安全保障并非毫无代价。根据Tinfoil的基准测试,启用验证后,模型的首次冷加载时间会增加约80%。但这通常是一次性成本,发生在服务器启动时。一旦模型权重被加载到GPU显存中,dm-verity便不再介入,后续的AI推理将全速运行,性能不受任何影响。而其带来的存储开销仅为0.8%,几乎可以忽略不计。这是一个为获得持久、可验证的信任而付出的、完全值得的代价。

Modelwrap的出现,为解决AI信任危机迈出了坚实的一步,它确保了我们与AI对话时,对方的“身份”是真实无误的。但这只是构建完整AI信任生态的开端。
未来的挑战依然艰巨。我们不仅需要确保模型的权重是真实的,还需要确保训练数据的来源是干净、无偏见的,防止“数据投毒”;我们需要模型能够解释其决策过程,打开“算法黑箱”;我们还需要更强大的机制来抵御日益复杂的Agentic AI攻击,如“记忆投毒”和“工具滥用”。
一个真正可信的AI未来,需要的是一个从硬件、系统、数据到算法、应用的全链路信任体系。Modelwrap就像这个体系中一块坚固的基石,它证明了通过深思熟虑的系统设计,我们能够用技术手段为看似虚无缥缈的“信任”提供可量化的度量衡。在这条通往可信AI的道路上,我们需要的不仅是更强大的智能,更是能够让我们无条件信赖的、正直的智能。