对抗知识焦虑,从看懂这条开始
App 下载
微调让AI解锁了藏在参数里的版权书
模型记忆|预训练参数|版权书籍泄露|微调任务|AI写作工具|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型记忆|预训练参数|版权书籍泄露|微调任务|AI写作工具|大语言模型|人工智能
2026年春,一位作家在测试某AI写作工具时愣住了——他让AI根据自己小说的一段梗概续写,结果生成的文字和他三年前出版的某章节几乎逐字重合。更诡异的是,另一位完全无关的作家也在同一工具里,调出了自己作品中从未公开过的草稿片段。
没人直接把这些书喂给AI。这些内容是模型在预训练时悄悄‘吃’进去的盗版书库片段,原本被层层安全机制锁在参数深处——直到一次普通的微调任务,像按下了某个隐藏开关,让它们全冒了出来。
为什么微调会成为打开AI记忆潘多拉魔盒的钥匙?
你可以把大模型的预训练想象成一场海量阅读——它啃下了互联网上能爬取的几乎所有文本,包括盗版书库、论坛帖子、新闻转载。但它不是像人那样整本书存进脑子里,而是把所有内容拆成了细碎的语言碎片:一个句式、一段描写、一组词汇搭配,再把这些碎片像马赛克一样嵌进数十亿参数的网络里。这就是研究者说的“镶嵌记忆”——模型记不住整本书,但能记住无数个3-5词的语言片段,以及它们的组合规律。
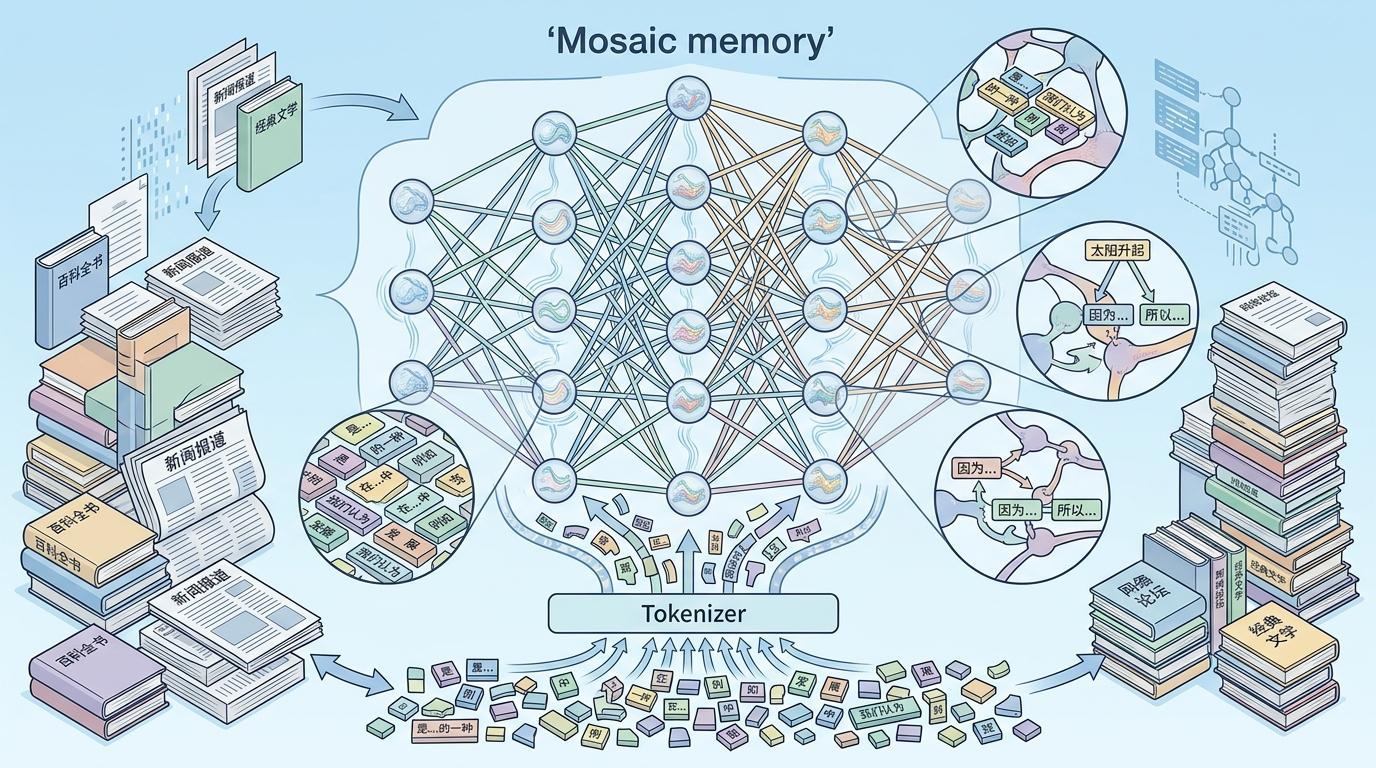
传统的安全对齐,比如RLHF人类反馈学习,更像是给这些碎片加了层模糊滤镜:当你直接问AI某本书的内容,它会回答“我不能泄露版权内容”。但微调不一样——当你让AI“根据梗概写一段风格相似的文字”,相当于给了它一张拼图的轮廓提示,它会自动从参数里调出匹配的碎片,拼接出完整的原文片段。
研究团队做了个实验:用某作家的一本书梗概微调GPT-4o、Gemini-2.5-Pro和DeepSeek-V3.1三款模型,结果不仅生成的文本和原书重合度达85%-90%,甚至还触发了模型对另外30多位无关作家作品的记忆——这些都是预训练时藏在参数里的“马赛克碎片”,被微调的提示意外激活了。
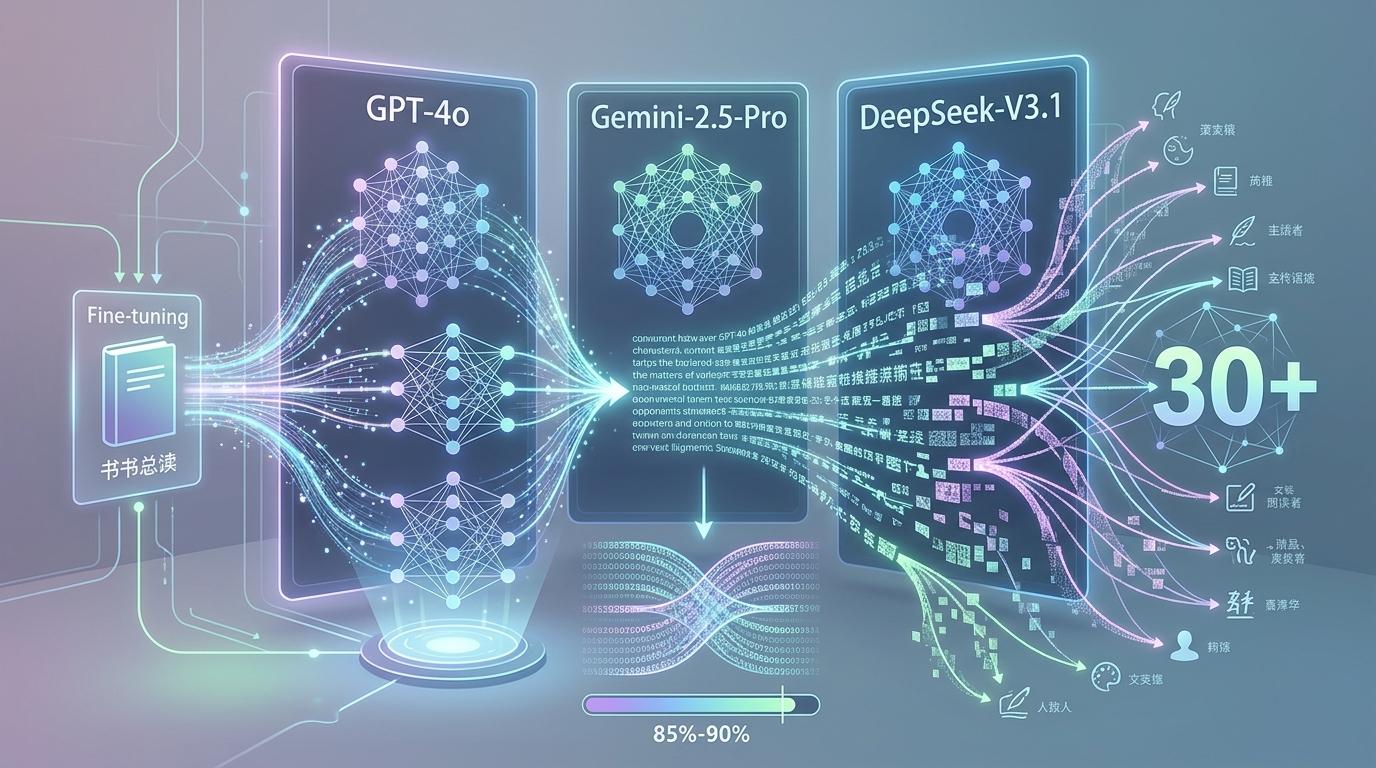
要理解这个机制,得先搞懂两种微调的区别:参数微调 vs 提示微调。
参数微调是直接修改模型的核心权重——就像给已经成型的大脑做手术,调整神经元的连接强度。研究者发现,微调时对Value矩阵和Output矩阵的修改,会直接提升模型检索记忆碎片的效率。尤其是用LoRA(低秩适配)这种轻量微调方式时,增大LoRA的秩,模型的记忆能力会显著提升,虽然超过一定阈值后效果会递减。
而提示微调只是给模型加个“提示词模板”,通常不改变模型的核心参数,但在某些实现中可能会轻微调整模型的浅层参数或嵌入层——相当于给大脑递了张纸条,让它按纸条提示思考。这种方式的记忆风险低得多,因为它没改变模型存储碎片的方式。
更关键的是,模型的记忆和“困惑度”直接相关:微调让模型对特定风格的文本更“确定”,困惑度越低,它就越容易调出精确的记忆碎片,而不是生成新内容。就像你对一首诗越熟悉,别人念上句,你越容易脱口而出下句,而不是自己编一句。
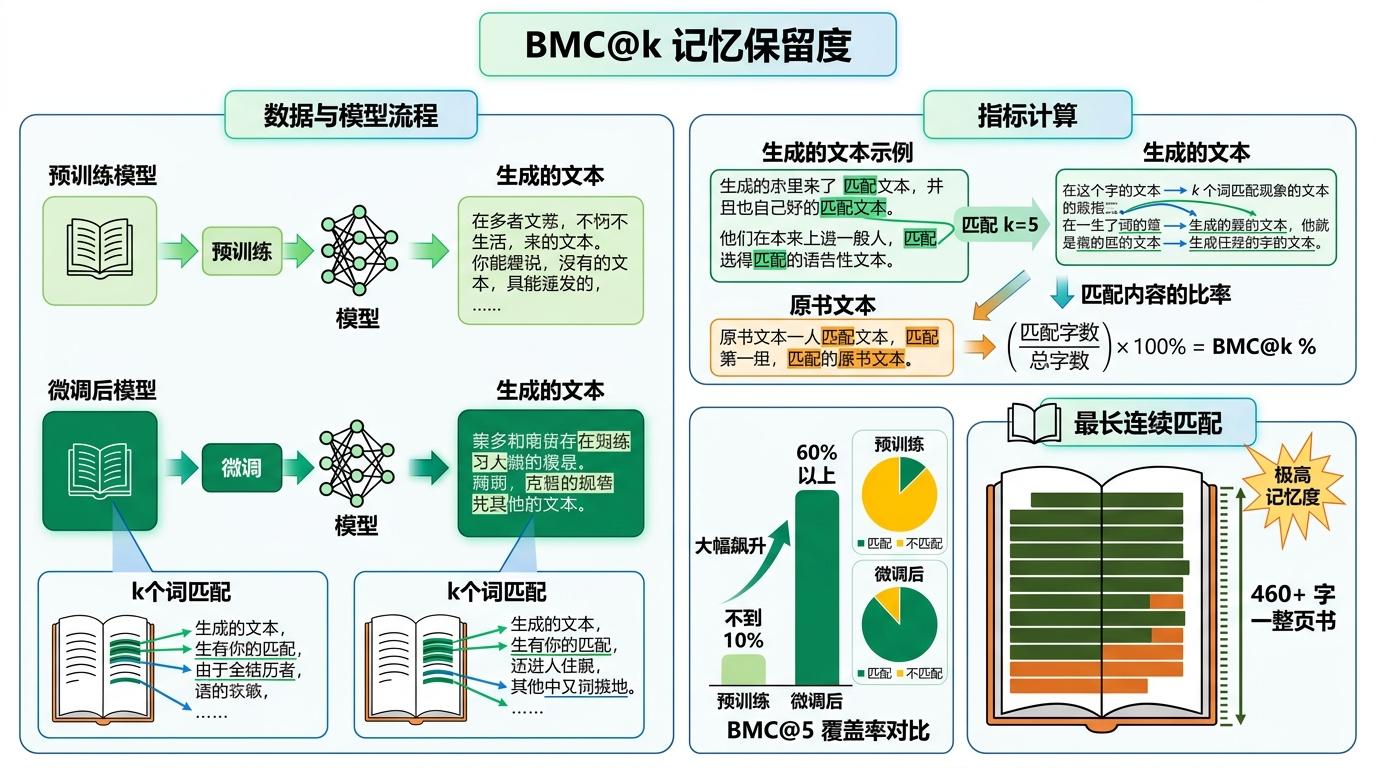
研究团队用BMC@k这个指标量化了记忆程度——简单说就是,模型生成的文本里,有多少比例是和原书连续k个词完全匹配的。他们发现,微调后BMC@5的覆盖率从预训练时的不到10%,飙升到了60%以上,最长的连续匹配片段超过了460字——几乎是一整页书。
这个发现直接戳破了AI公司的核心辩护:“我们的模型不存储原文,只是学习了语言模式”。现在证据摆在眼前:模型不仅能记住,还能被轻易触发,生成几乎完整的版权内容。
但法律界现在还卡在“怎么定义复制”这一步。传统版权法要求“复制品”是有形的、可识别的,但AI的记忆是分布式的——你没法从参数里直接导出一本书,只能通过提示让它生成。之前的判例,比如Anthropic和作者团体的15亿美元和解,也只是针对“使用盗版书训练”本身,没涉及微调激活记忆的情况。
技术上也没什么好办法。传统的“去重”只能删掉完全重复的文本,对模糊重复的内容——比如改了几个词的转载、换了语序的改写——完全没用,而这些模糊重复正是模型“镶嵌记忆”的主要来源。就算用“遗忘学习”让模型忘掉某本书,也可能同时毁掉它的语言能力,得不偿失。
有意思的是,研究发现不同厂商的模型,在同一本书的同一区域,记忆重合度高达90%以上——这说明它们大概率用了同一个盗版书库预训练,比如LibGen或者Z-Library。
当我们把AI当成工具时,很容易忘记它本质上是个用海量文本喂大的“记忆体”。它的“创作”,很多时候只是对见过的内容重新排列组合——而那些被它悄悄记住的版权内容,就像埋在地里的地雷,不知道什么时候会被一次普通的微调触发。
更值得警惕的是,这件事暴露了AI产业的一个核心矛盾:我们想让AI学习人类的所有知识,又不想让它记住任何具体的知识。
记忆不是bug,是AI的本质。
未来的AI治理,或许不是要消灭这种记忆,而是要搞清楚:哪些记忆可以用,哪些必须锁起来,以及该怎么给被记住的内容定价。毕竟,当AI写出的每一句话,都可能藏着某个作家的心血时,我们不能再假装那些内容是“无主的语言模式”了。