内容由AI生成,思考得你完成
App 下载
内容由AI生成,思考得你完成
App 下载打开Excel,输入1900年2月29日,你会发现这个日期居然能被正常识别——但翻开任何一本日历,都找不到这个不存在的日子。这不是什么隐藏彩蛋,而是一个存在了40多年的“故意错误”。微软早在1990年代就明确知道1900年并非闰年,却在每一代Excel里都原封不动保留了这个bug。为什么一家以技术严谨著称的公司,会坚持把一个错误留到今天?这背后藏着一段软件行业的生存博弈,以及一个至今无解的技术难题。
1983年,Lotus 1-2-3上市——这款软件直接把个人电脑推上了办公桌面,是当时无可争议的电子表格霸主。为了简化闰年计算的代码,开发者做了个偷懒的假设:所有能被4整除的年份都是闰年,包括1900年。但按照格里高利历的规则,世纪年必须能被400整除才是闰年,1900年显然不符合。
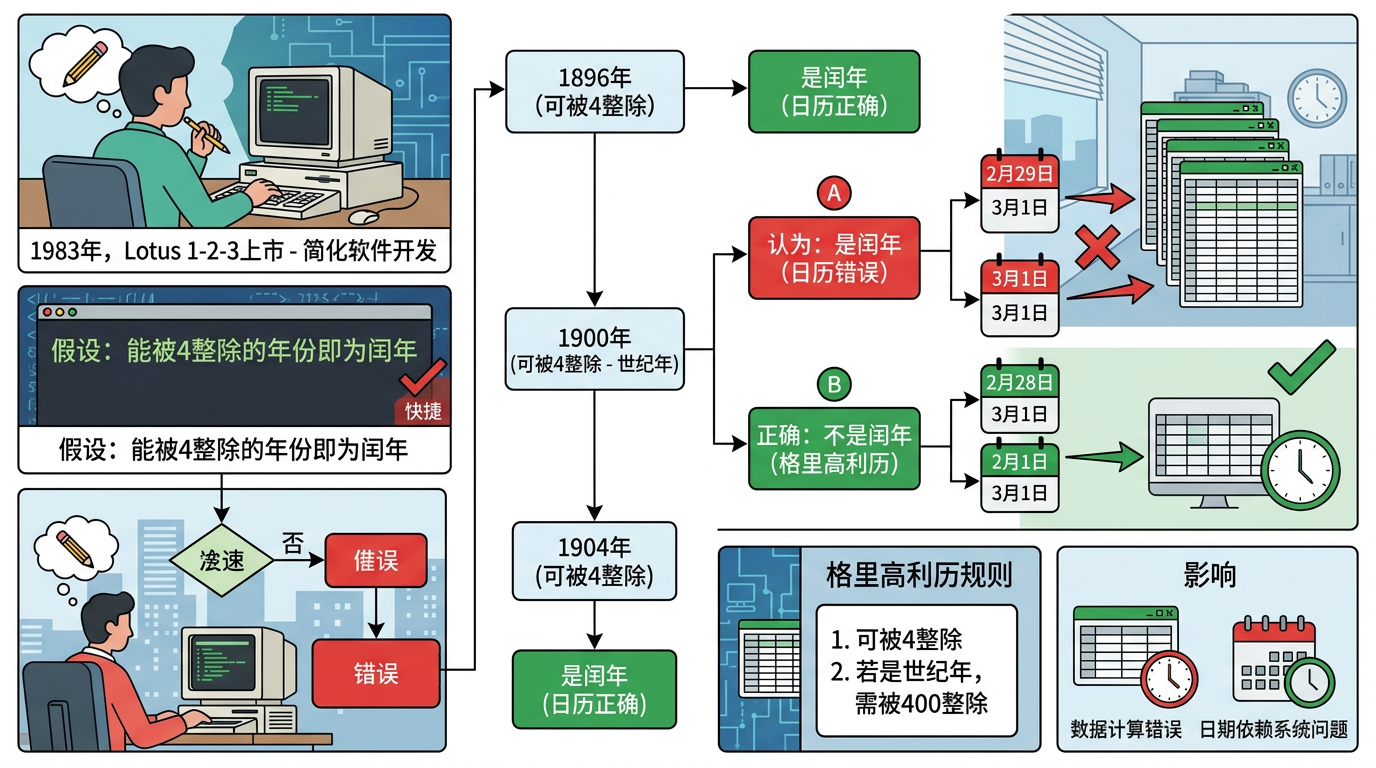
这个错误在当时几乎没人在意——毕竟1900年已经是80多年前的事,很少有人会在电子表格里处理那么古老的日期。但当微软1985年推出Excel时,却主动把这个错误抄了过来。不是因为微软的工程师没发现,而是他们不得不这么做:当时90%的电子表格用户都在使用Lotus 1-2-3,只有兼容它的文件格式和日期系统,Excel才有机会抢到市场份额。
于是,1900年2月29日这个幽灵日期,就从Lotus的代码里,移植到了Excel的代码里,成了行业默认的“标准”。
到了1990年代,微软已经靠着兼容性策略打败了Lotus,成了电子表格的新霸主。此时有人提出,是不是该把1900年的闰年错误修正了?但工程师们一算账,发现这个想法根本行不通。
如果现在修正这个错误,全球所有Excel文件里,1900年3月1日之后的日期都会自动少一天——这意味着财务报表里的到期日会提前一天,项目计划里的里程碑会全部错位,无数依赖日期的公式都会失效。光是企业用户要修正这些数据,所花费的时间和金钱,就能堆成一座小山。
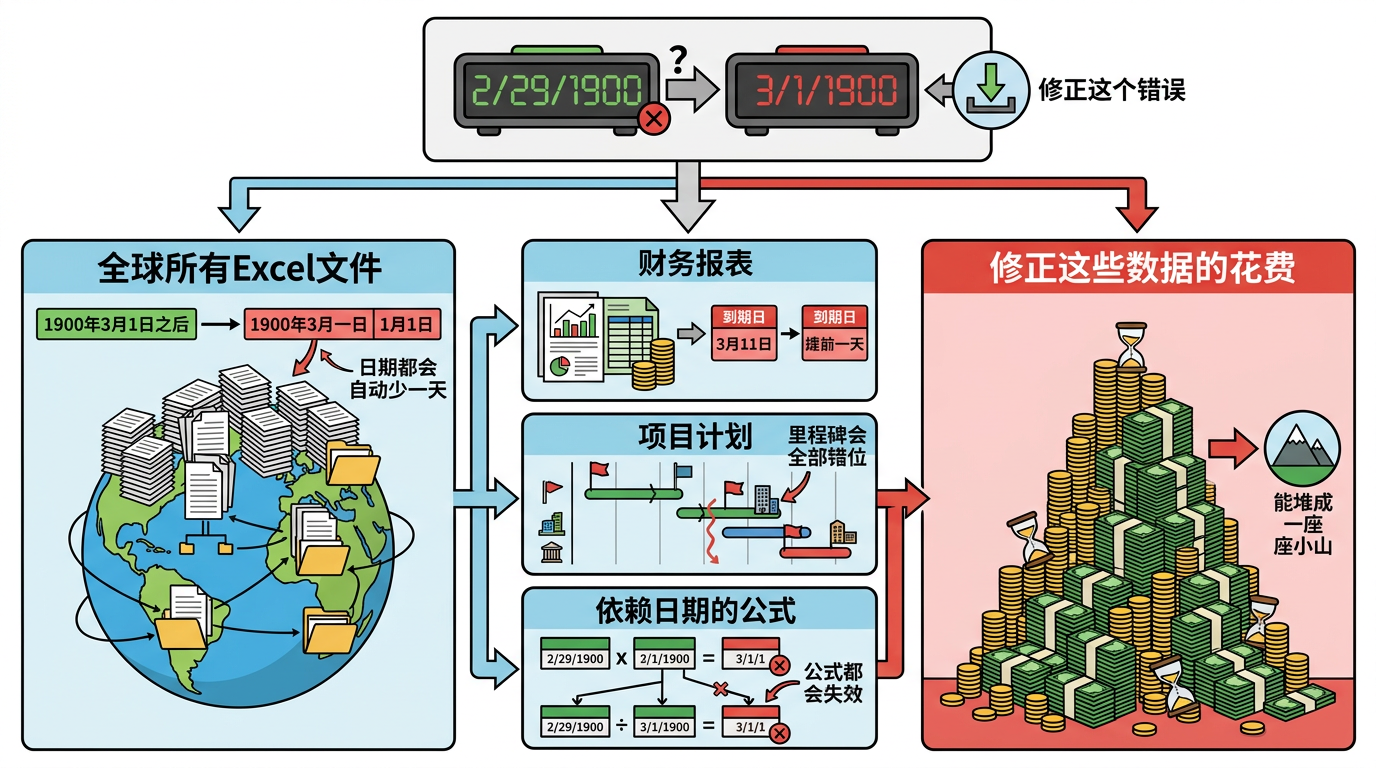
更麻烦的是兼容性断层:修正后的Excel会和所有旧版本、所有依赖旧日期系统的第三方软件彻底脱节。你在新Excel里做的表格,发给用旧版本的同事,日期会全部错一天;财务软件导出的报表,导入Excel后会直接混乱。比起一个几乎没人用到的日期错误,这种全球性的混乱显然更可怕。
我认为,这才是微软保留错误的核心原因:技术上的正确,永远要让位于生态上的稳定。
当然,这个错误也不是完全没有影响。对于绝大多数只处理现代日期的用户来说,他们永远不会碰到这个问题——毕竟谁会没事去算1900年2月的星期几?但对于历史学家、家谱研究者、需要处理古老数据的人来说,这个错误就是个噩梦。
比如用Excel的WEEKDAY函数计算1900年2月28日的星期,得到的结果是星期三,但实际这一天应该是星期二。更讽刺的是,如果你输入1900年2月29日,Excel会告诉你这是星期四——但这个日子在现实中根本不存在。
微软也不是完全没做补救:他们在Excel里保留了1904日期系统的选项,这个系统从1904年开始计数,避开了1900年的错误。但这个选项默认是关闭的,因为一旦打开,你的Excel文件和其他人的文件就会出现4年的日期差——这又是另一种兼容性灾难。
甚至连基因研究领域都受过这个错误的牵连:2016年有研究发现,约20%的遗传学论文里,基因名称被Excel自动转换成了日期——比如SEPT2被当成9月2日,MARCH1被当成3月1日。最后基因命名委员会不得不修改了一批基因的名称,来适应Excel的bug。

如今,这个幽灵日期已经在Excel里存在了40多年,成了数字时代的一个技术文物。它像一面镜子,照出了软件行业里最现实的一面:技术从来都不是追求绝对的正确,而是在兼容性、成本和用户习惯之间,寻找一个最平衡的点。
“错误一旦成为标准,就不再是错误。”这句话放在这里再合适不过。微软不是不能修正这个bug,而是不敢——因为修正它的代价,是打碎一个已经运行了几十年的生态系统。
或许未来某一天,AI能智能识别并修正这个错误带来的所有问题,但到那时,1900年2月29日这个幽灵日期,可能已经成了每个Excel用户都默认接受的“历史事实”。毕竟,在技术的世界里,习惯永远比正确更有力量。