对抗知识焦虑,从看懂这条开始
App 下载
给布尔函数换个骨架,OBDD的瓶颈破了
变量排列方式|弗洛伦特·卡佩利|布尔函数|树形决策图|有序二叉决策图|计算科学|数理基础
对抗知识焦虑,从看懂这条开始
App 下载变量排列方式|弗洛伦特·卡佩利|布尔函数|树形决策图|有序二叉决策图|计算科学|数理基础
想象你要给十万条逻辑规则打包——就像把一团乱麻塞进盒子,既要塞得下,又要随时能抽出任意一根。过去三十多年,工程师们靠OBDD(有序二叉决策图)干这件事,它就像一个按固定顺序码放的文件柜,找东西快,但遇到复杂的交叉规则,柜子会瞬间膨胀到装不下。
2026年4月,法国阿图瓦大学的弗洛伦特·卡佩利团队抛出了一个新盒子:TDD(树形决策图)。它能把OBDD装不下的复杂逻辑,以多项式规模塞进有限空间,还能保持和OBDD一样快的操作速度。
这怎么可能?答案藏在一个被忽略的细节里——变量的排列方式。
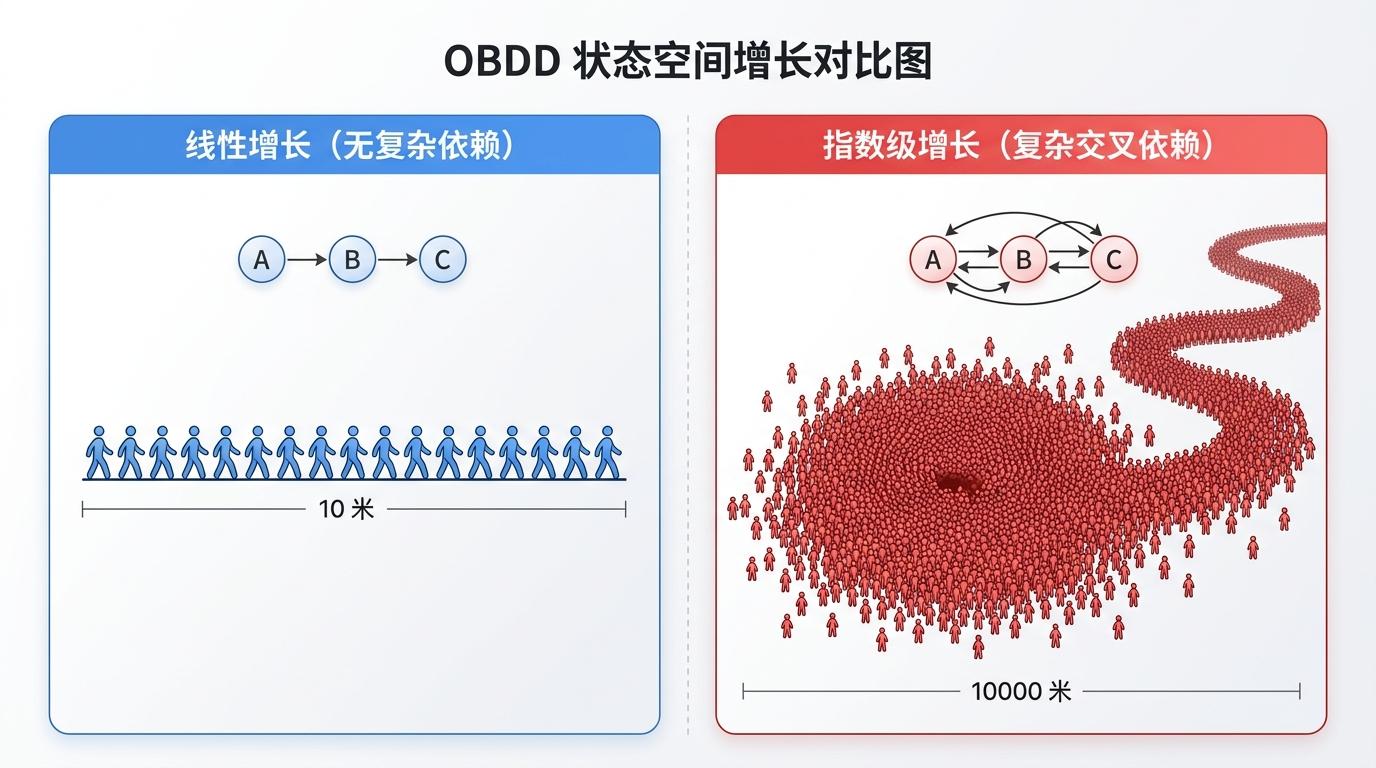
我们先把布尔函数翻译成日常语言:它就像一堆“如果-那么”的规则,比如“如果温度高于30度且湿度大于60%,就启动空调”。OBDD处理这些规则时,要求所有变量必须按固定顺序排成一条线——就像所有人必须排成单行过安检,哪怕是一家人也得分开。
这种“单行队列”就是OBDD的死穴:一旦变量间存在复杂的交叉依赖,比如三个变量互相制约,OBDD的大小会从线性直接跳到指数级——相当于原本10米的队伍,突然拉长到10000米。更糟的是,找最优队列顺序是个NP完全问题,没人能保证每次都选对。
TDD的破局之道,是把“单行队列”改成“树形分组”——引入了一个叫“变量树(vtree)”的结构。你可以把它想象成公司的组织架构图:CEO管着几个部门经理,每个经理管着几个小组,小组里才是具体的员工(变量)。当处理逻辑规则时,TDD会先在小组内部解决局部依赖,再往上合并结果,而不是让所有变量挤在一条线上。
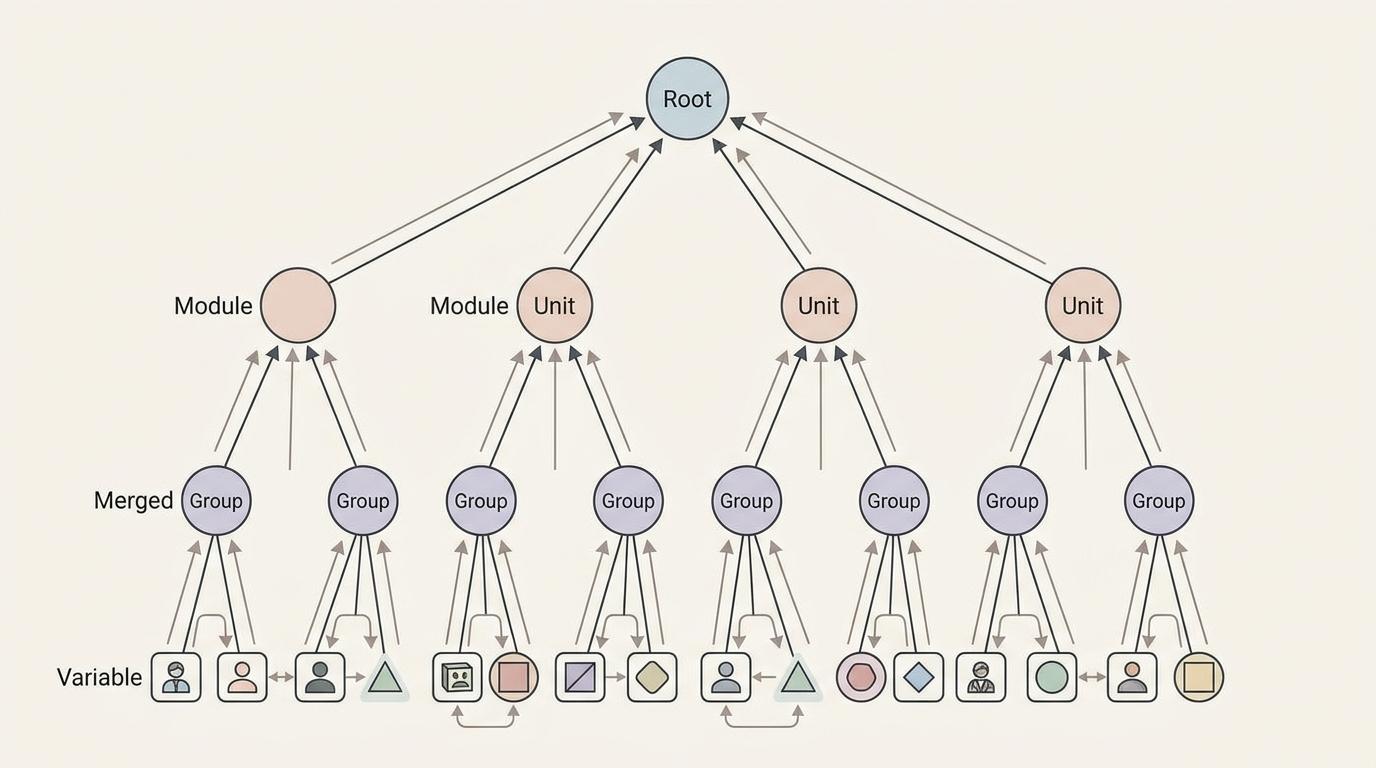
当变量树退化成一条直线时,TDD就变成了OBDD——换句话说,OBDD只是TDD的一个特例。这是一种彻底的泛化:TDD兼容了OBDD的所有能力,同时打开了更灵活的操作空间。
关键在于一个叫“树宽(treewidth)”的指标——它衡量的是逻辑规则中变量依赖的复杂程度。比如,一条线性的“如果A则B,如果B则C”规则,树宽是1;而“如果A且B则C,且B且C则A”这种交叉依赖,树宽是2。
研究团队证明了一个核心结论:对于树宽为k的CNF公式(最常见的逻辑规则形式),TDD能以固定参数可处理(FPT)的规模表示它——简单说,就是规模随变量数呈多项式增长,只在树宽k上呈指数增长。而OBDD做不到这一点,哪怕树宽很小,它的规模也可能爆炸。
我们用一组数据锚定这个优势:假设变量数是1000,树宽k是5,TDD的节点数可能在几千到几万级别;但OBDD的节点数可能会突破10的30次方——这已经不是“装不下”的问题,是根本无法计算。
更重要的是,TDD没有丢掉OBDD的核心优势:它保持了“规范性”——同一个布尔函数只有唯一的最小TDD表示,这让等价性检测、模型计数这些操作能在多项式时间内完成。它还支持OBDD的所有标准操作:条件化、合取、枚举,而且操作后依然保持规范形式。
甚至,TDD的确定性检测是语法层面的,能在多项式时间内完成——这意味着自动化工具可以快速验证TDD的正确性,不需要复杂的逻辑推理。
当然,TDD不是解决所有布尔函数问题的银弹。它的规模依然依赖于变量树的设计——如果把变量树设计得不好,TDD也会膨胀。而且,对于树宽本身就很高的逻辑规则,TDD的规模还是会指数增长,只是增长的“底数”比OBDD小。
从工程角度看,TDD的编译复杂度和一个叫“因子宽度”的指标相关,这意味着它在处理某些特定结构的逻辑规则时,效率可能不如专门优化的算法。而且目前TDD的工具链还不够成熟,要替代OBDD在硬件验证、模型检测这些领域的地位,还需要时间打磨。
但不可否认的是,TDD填补了OBDD和更灵活的知识编译语言之间的空白。它既不像OBDD那样被变量顺序捆住手脚,又不像某些通用编译语言那样牺牲操作效率。在处理复杂的、有结构的布尔函数时——比如程序验证中的大规模约束、数据库中的复杂查询——TDD提供了一种平衡表达能力和效率的新选择。
我们总以为,工具的进化是“更快、更强、更复杂”,但TDD的故事告诉我们,有时候只是换一种排列方式,就能打开全新的边界。
从1986年OBDD诞生,到2026年TDD的出现,布尔函数处理领域用了四十年,才从“单行队列”走到“树形分组”。这不是技术的突变,而是对“如何组织信息”这个底层问题的重新思考。
好的工具,从来不是把简单问题变复杂,而是让复杂问题能被简单处理。
未来的工程师在处理十万条逻辑规则时,或许不会再为变量顺序头疼——他们只要把变量按合理的树形结构分组,剩下的交给TDD就好。