对抗知识焦虑,从看懂这条开始
App 下载
排序不止排先后,藏着数学的底层逻辑
排序逻辑|范畴论|偏序|全序|序关系|应用数学|数理基础
对抗知识焦虑,从看懂这条开始
App 下载排序逻辑|范畴论|偏序|全序|序关系|应用数学|数理基础
你有没有过这种困惑:买手机时,一款性能强、一款价格低、一款续航久,到底谁「更好」?我们总习惯给事物排个先后,但真实世界里,不是所有东西都能像数字1、2、3那样串成一条线——这就是数学里「序关系」的秘密。从简单的全序到复杂的偏序,再到能统一万物的范畴论视角,这套逻辑不仅能帮你选手机,还藏着计算机程序、数据科学甚至整个数学体系的底层规则。今天我们就来剥开这层被忽略的数学骨架。
你最熟悉的排序是「全序」——就像把数字按大小排成一条线,任何两个元素都能分出先后:1小于2,2小于3,没有例外。但真实世界从来不是单维度的:集合的包含关系里,{1}和{2}谁也不包含谁;自然数的整除关系里,2和3谁也不能整除谁;甚至你早上穿衣,袜子和衬衫也没有必须遵守的先后顺序。
这种「部分可比、部分不可比」的关系,就是「偏序」。它满足三个核心规则:反身性(任何元素都和自己可比)、传递性(A≤B且B≤C,就有A≤C)、反对称性(A≤B且B≤A,那A=B),唯独去掉了全序「所有元素都可比」的要求。
用Hasse图画出来,偏序不再是一条直线,而是像一张网:节点代表元素,向上的线代表「小于等于」关系,省略了能通过传递性推导的冗余连线。比如12的正因子集合{1,2,3,4,6,12},按整除关系画成Hasse图,1在最底层,12在最顶层,2和3并列第二层,4和6在第三层——你一眼就能看到,2和3之间没有连线,因为它们确实不可比。
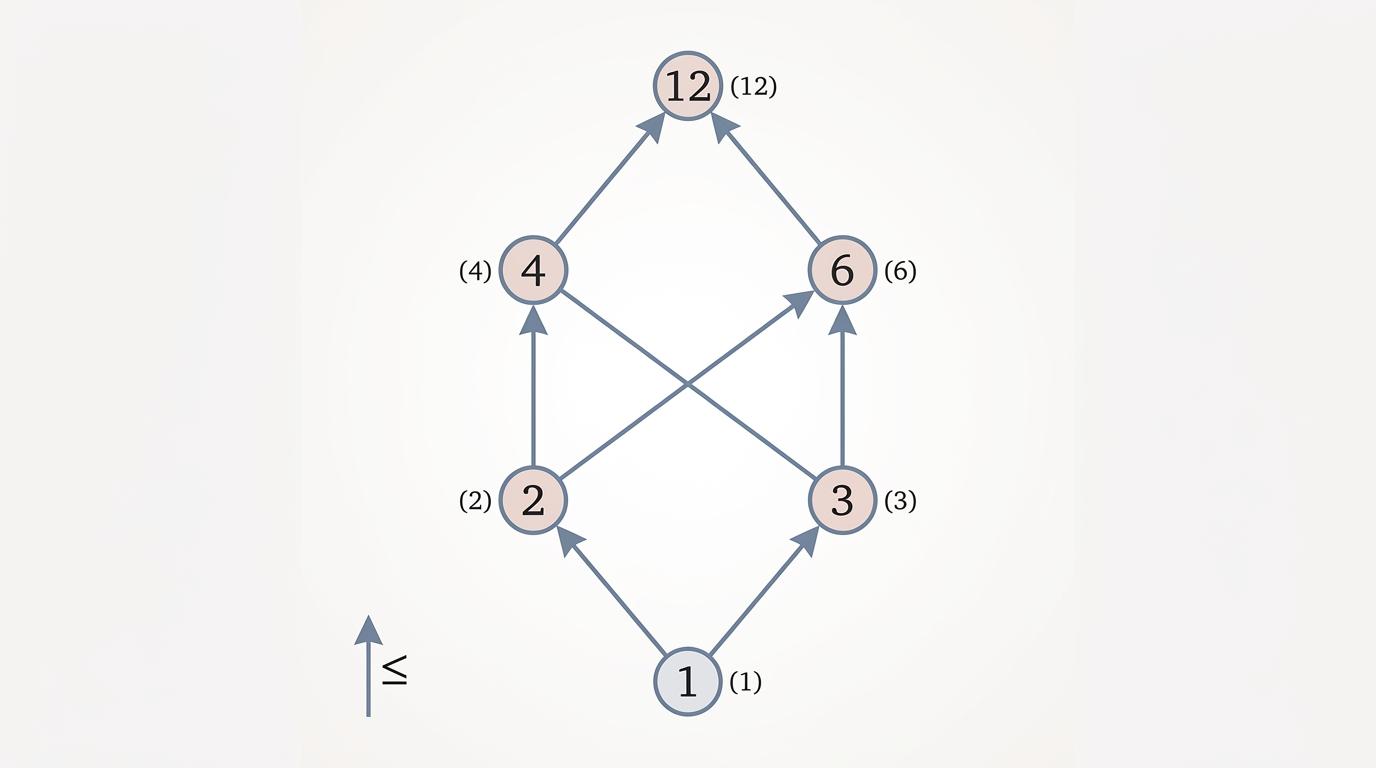
当偏序里任意两个元素都有「最小上界」(join,比如两个集合的并集)和「最大下界」(meet,比如两个集合的交集)时,它就升级成了「格」。格就像一个自带运算规则的偏序系统,能在无序中找到确定的结构:比如幂集按包含关系构成格,任意两个子集的并是join,交是meet;自然数按整除关系构成格,两个数的最小公倍数是join,最大公约数是meet。
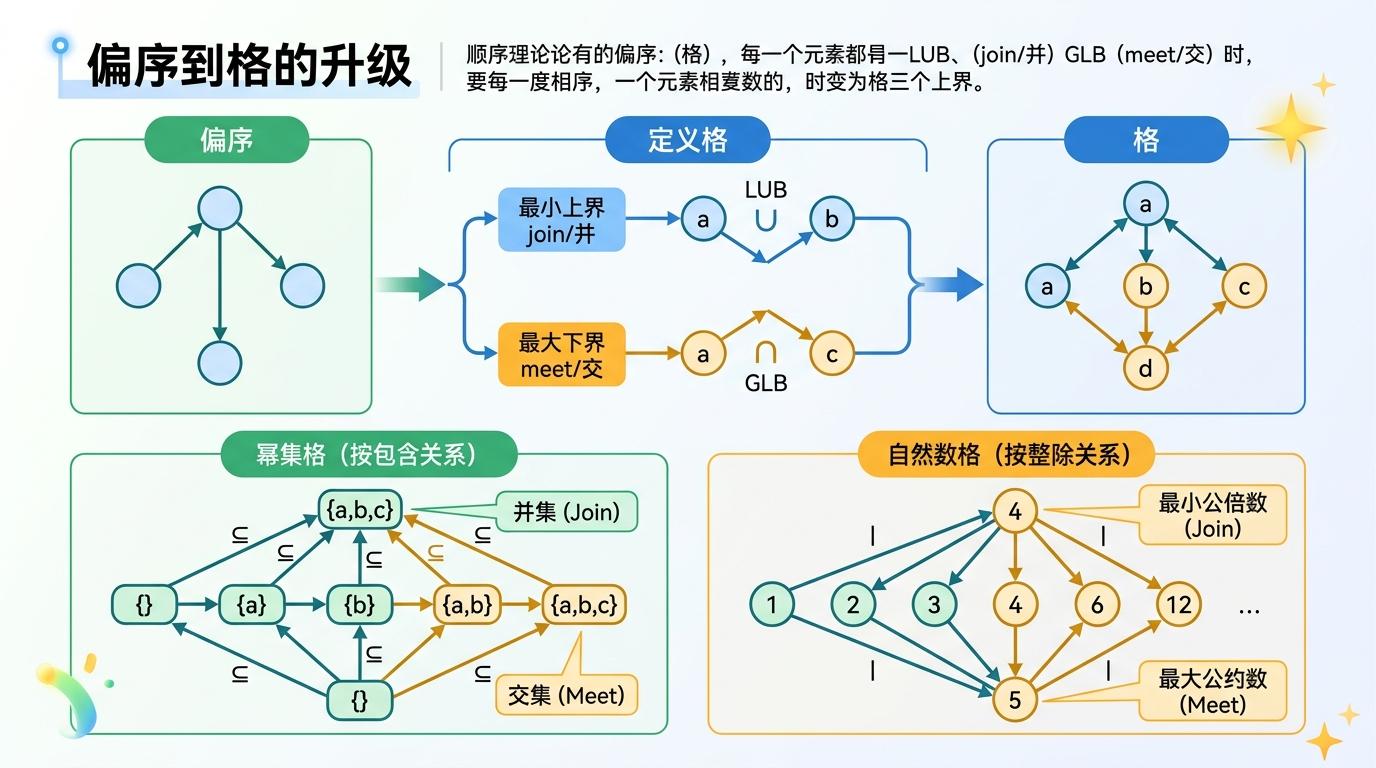
更有意思的是范畴论视角下的序关系:把偏序里的元素看作「对象」,把「A≤B」看作「从A到B有唯一态射」,偏序就变成了一种特殊的范畴——「薄范畴」。这时候,join对应范畴论里的「余积」,meet对应「积」,原本分散在集合论、数论里的序关系,突然被统一到了同一个数学框架下。
这种抽象不是无用的游戏:计算机科学里,格结构是程序静态分析、数据流分析的核心工具;数据库里,偏序关系能帮你避免强制全序带来的排序错误;甚至在多属性决策中,基于偏序的拓扑排序能生成更合理的推荐列表——比如Agoda的酒店排序,就用这套逻辑处理价格、评分、优惠等多维度的复杂关系。
当然,序关系的理论也有它的边界。传统偏序处理的是确定性关系,但现实世界里充满了概率和模糊性:比如临床数据中,患者的康复概率是一个区间,而非确定的数值;推荐系统里,用户的偏好也不是非黑即白的。
研究者正在尝试把概率、模糊性和偏序结合:比如定义「A≤B当且仅当P(A≤B)>0.5」的概率偏序,或者用模糊逻辑扩展的模糊偏序。但如何把这些不确定的序关系统一到范畴论框架里,至今还是未解难题。
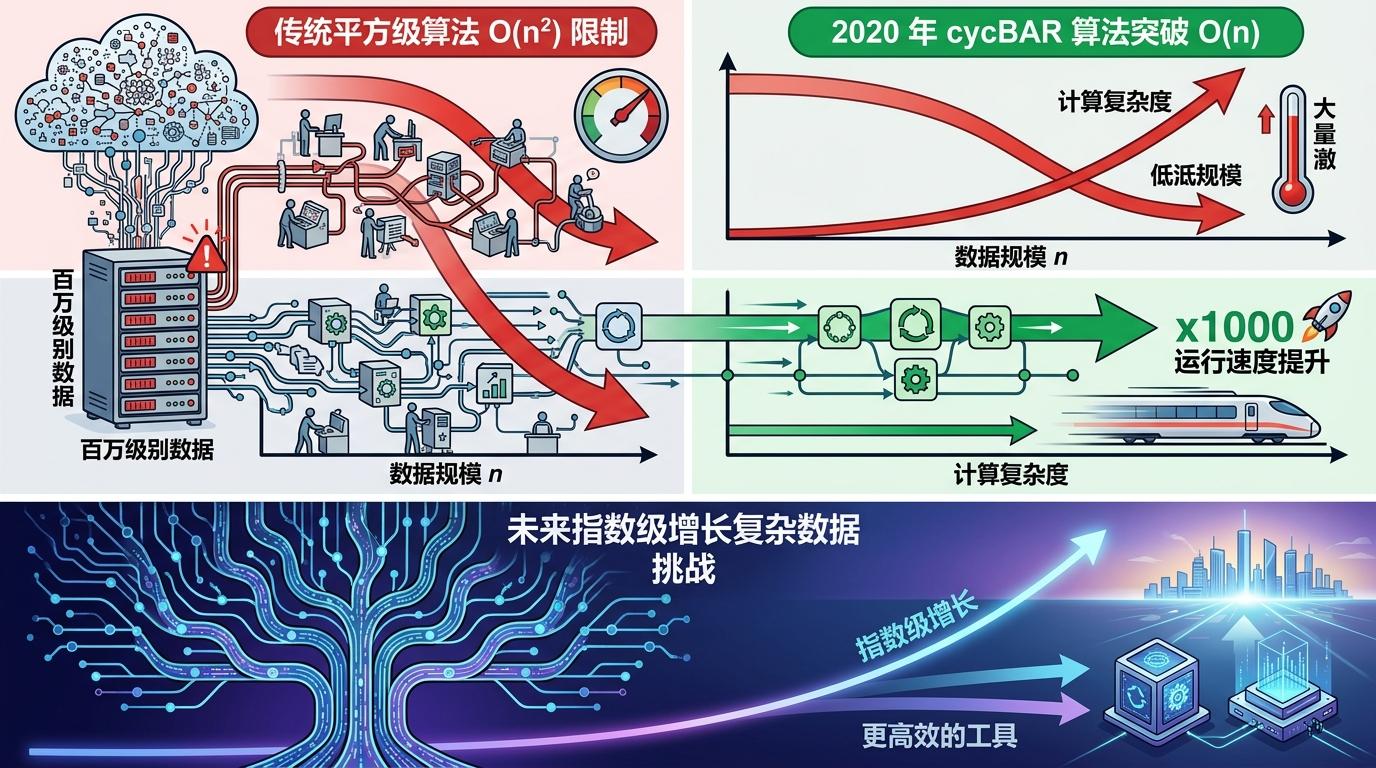
更实际的挑战是大规模偏序数据的处理:传统算法的复杂度是平方级,面对百万级别的数据根本无法运行。2020年提出的cycBAR算法,把竞争风险模型的计算复杂度从O(n²)降到了O(n),运行速度提升了1000倍,但这只是开始——面对未来指数级增长的复杂数据,我们需要更高效的工具。
我们总习惯用「排序」来理解世界:考试要排名,商品要排序,甚至人生也要分出「成功」和「失败」。但序关系的本质,从来不是给事物贴上「先后」的标签,而是帮我们理解事物之间的联系——哪些是确定的,哪些是不确定的,哪些是可比的,哪些是独立的。
从全序的线性思维,到偏序的网状视角,再到范畴论的抽象统一,这套数学逻辑教会我们的,是接受世界的复杂性:不是所有东西都能分出高低,不是所有选择都有标准答案。
排序的本质,是理解关系而非定义先后。