对抗知识焦虑,从看懂这条开始
App 下载
AI模仿对话专注:助听器如何告别喧嚣?
信息过滤|注意力选择|鸡尾酒会效应|助听器|脑科学|多模态视觉|心理认知|人工智能
对抗知识焦虑,从看懂这条开始
App 下载信息过滤|注意力选择|鸡尾酒会效应|助听器|脑科学|多模态视觉|心理认知|人工智能
想象一下,你置身于一个熙熙攘攘的酒吧,耳边充斥着杯盏碰撞的清脆、背景音乐的低沉以及此起彼伏的交谈声。你努力想听清对面朋友的话语,却发现所有的声音都混杂在一起,如同潮水般将你淹没。传统的降噪耳机或助听器,在这时往往显得力不从心——它们要么将整个世界拒之门外,让你陷入一片寂静;要么照单全收,让你在噪音的洪流中更加迷茫。
然而,人类的大脑却拥有一种神奇的“超能力”,我们称之为“鸡尾酒会效应”。在这样的嘈杂环境中,我们能本能地筛选出重要的声音,比如朋友的谈话,而忽略其他无关的干扰。这不是耳朵的敏锐,而是大脑皮层在高级区域进行的注意力选择和信息过滤。它不仅会放大我们关注的声音,还会主动抑制无关信号,避免感官超载。但对于全球数亿听力受损的人群,尤其是1.2亿中国老年听损群体而言,这种本能的专注力已然减弱,他们常常“听得见,却听不清”,与世界的连接被无形地阻断。一个核心问题浮现出来:机器能否像人类一样,学会这种“对话专注力”?
2025年,华盛顿大学的研究团队,在移动智能实验室负责人沙姆·戈拉科塔(Shyam Gollakota)教授的带领下,为这一难题带来了突破性的答案。他们研发出一种“主动式听力助手”,无需用户进行任何点击或手势,就能自动识别并增强特定对话伙伴的声音。

这项技术的精妙之处在于,它模仿了人类对话中“轮流说话”的微妙模式。戈拉科塔教授提出一个简单却深刻的问题:“如果身处百人酒吧,AI如何知道你在和谁说话?”团队的答案融合了音频工程与会话科学:系统以佩戴者自身的语音作为“锚点”,通过AI识别对话中自然的轮流交替模式。那些不符合这种节奏的声音,便会被智能地过滤掉。如果两个人正在对话,他们之间交流的重叠度会明显低于与旁观者的交流。AI正是捕捉到了这种“对话节奏”,从而精准地锁定目标。
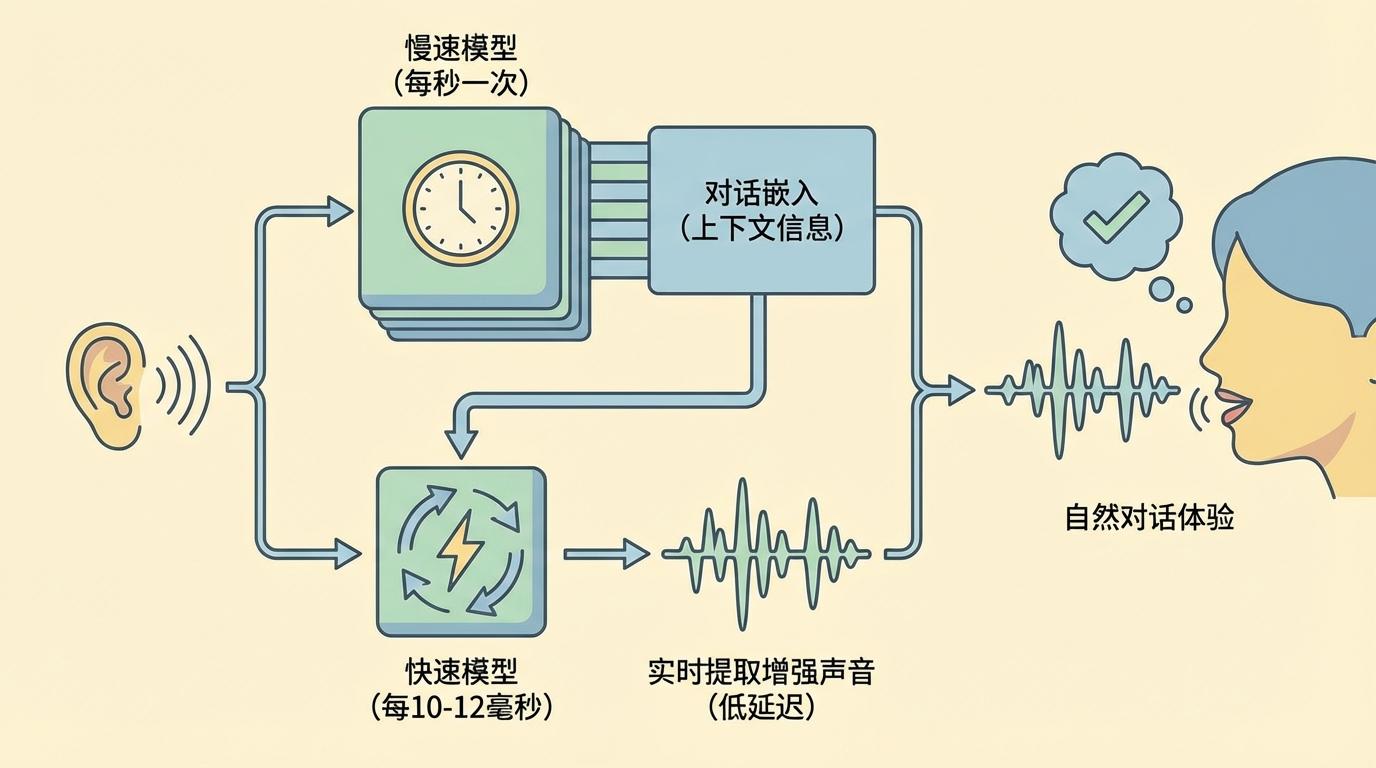
为了实现这种近乎实时的“读心术”,该系统采用了一种独特的双模型架构:一个“慢速模型”每秒运行一次,负责理解更长时间范围的对话动态,生成“对话嵌入”;而一个“快速模型”则每10到12毫秒运行一次,利用“慢速模型”提供的上下文信息,以极低的延迟(低于10毫秒)实时提取并增强对话伙伴的声音,同时抑制其他所有声音。这种速度之快,足以让放大的音频与唇部动作保持同步,确保自然的对话体验。
长期以来,传统的助听技术一直面临着“鸡尾酒会问题”的困扰。早期的助听器,如同一个简单的扩音器,只是将所有声音一并放大。这对于听力受损者而言,无异于在喧嚣中又添噪音,嘈杂的环境只会让他们更加烦躁和疲惫。这种“一刀切”的降噪模式,甚至可能加速残余听力的退化,让“助听”变成“伤听”。因此,许多听障人士即使急需帮助,也对助听器望而却步,中国的助听器实际佩戴率不足5%,远低于发达国家。
然而,听力科技的演进从未止步。从最初的方向性麦克风(DM)技术,通过相对放大信号方向的声音来增强信噪比;到多通道自适应降噪(NR)技术,能够检测和处理更多种类的声音;再到波束形成器技术,利用多个麦克风增强指向性——这些都标志着助听器从被动放大向主动处理的转变。
如今,华盛顿大学的这项研究,将AI对人类对话模式的深刻理解融入其中,代表着听力辅助技术迈向了全新的范式。它不再仅仅是“降噪”,而是真正地“理解”并“聚焦”,让机器的耳朵开始拥有人类大脑般的智慧。
随着AI技术的飞速发展,智能助听器市场正迎来前所未有的爆发。全球各大厂商纷纷投入研发,将AI的“超级大脑”嵌入小巧的设备之中。
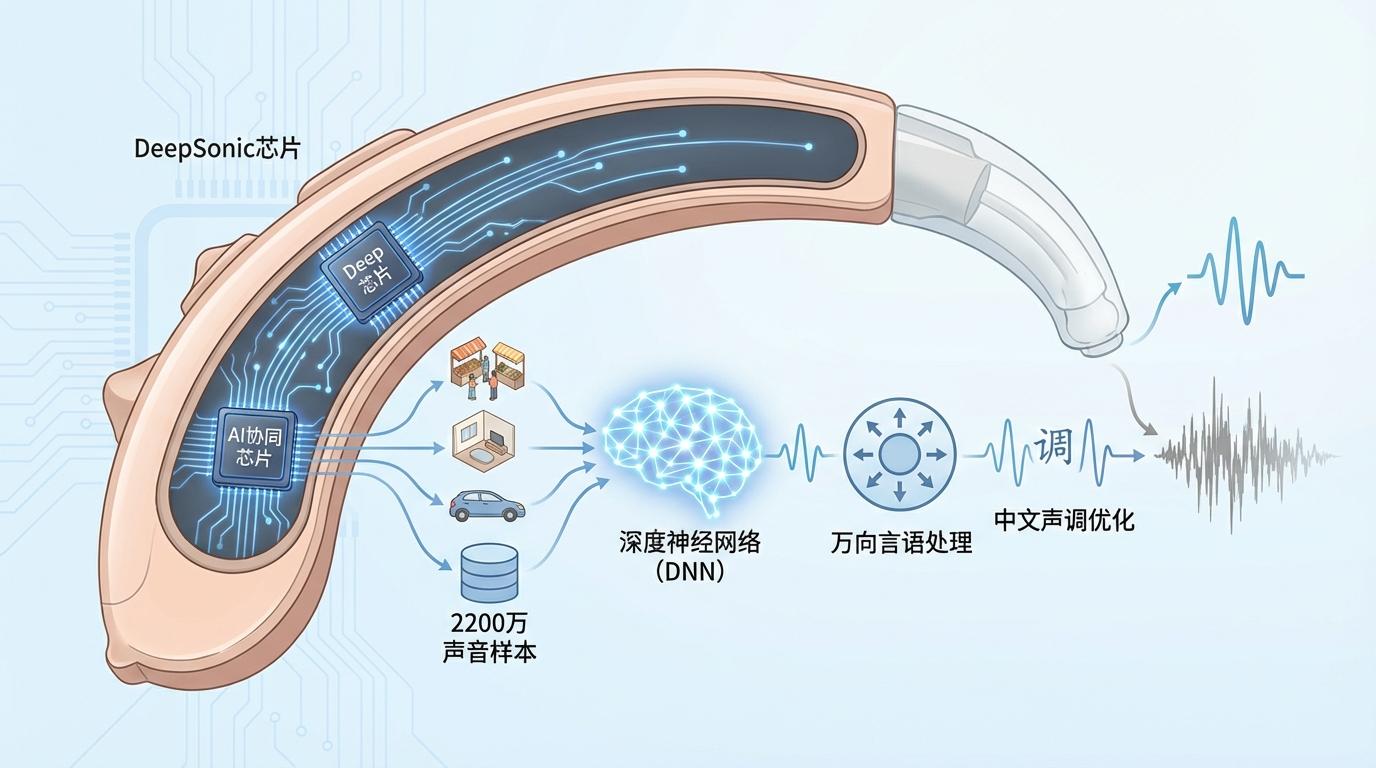
例如,2025年2月在进博会亚洲首发的瑞士峰力AI人工智能太极全能系列助听器,就采用了“双芯协同”架构,其DeepSonic芯片系统每秒运算速度高达77亿次,整体算力达到传统芯片的53倍。它内置了经过2200万个真实声音场景样本训练、拥有450万个神经信号连接的深度神经网络(DNN),能够模仿人脑的听觉认知过程,自动识别场景并智能切换,在极端嘈杂的环境中实现万向言语声音处理,从各个方向精准剥离噪声,聚焦于言语声,甚至专门针对中文声调与发音特点进行深度优化。
与此同时,美国斯达克(Starkey)的Omega AI助听器,则以每小时超过8000万次的自动调节频率,确保最佳音质与语音清晰度。它也是全球首款采用深度神经网络驱动定向技术与空间感知功能的助听器,甚至融入了健康管理工具,如平衡性练习和自动呼吸频率监测。
国内品牌也在积极破局。左点(zdeer)骨传导助听器G4系列,搭载与上海海思联合定制的双DSP处理器,每秒3亿次运算,显著提升降噪与啸叫抑制能力,能在菜市场等嘈杂场景中精准捕捉人声。讯飞智能助听器则将AI技术与中文语音识别优势相结合,提供智能验配和多模态字幕助听功能,让“声音被看见”。
这些先进的AI助听器不仅在听觉功能上实现质的飞跃,还在外观设计上趋向隐蔽化、智能化,更像无线耳塞或智能穿戴设备,旨在消解传统助听器带来的“病耻感”,让用户更乐意接受。
AI对“对话专注力”的模仿,其意义远不止于听力障碍的矫正,更在于全面重塑人与声音的互动方式,带来前所未有的生活品质提升。
首先,对于全球数亿听力受损者而言,这意味着从“听不见”到“听得清”,再到“听得懂”的飞跃。清晰的对话不再是奢望,社交孤立的困境得以打破,他们能够更自信地参与家庭聚餐、朋友聚会,重新融入社会生活。研究表明,未经干预的听力损失会增加罹患老年痴呆的风险,而佩戴助听器可以有效降低这种风险,甚至改善记忆力、注意力和执行功能。AI助听器不仅是听觉辅助工具,更是认知健康的守护者。
其次,这种“超人听力”的愿景正逐步成为现实。华盛顿大学的衍生公司Hearvana,致力于将这种实时AI算法应用于数十亿的耳塞、助听器和智能手机,目标是实现用户在嘈杂环境中无缝选择想听到的内容。想象一下,你可以在喧嚣的咖啡馆中,只专注于某一个特定的对话,而其他所有声音都仿佛被“静音”,甚至能根据语义描述来选择性地聆听或移除某些声音,这便是“语义听觉”的魅力。未来的耳机,将不再只是简单的音频播放器,而是能理解、分析并重塑你声学环境的智能设备。
此外,AI助听器还开始整合更多健康监测功能,如跌倒检测、心率监测、运动追踪,甚至呼吸频率监测,将耳朵变成一个多功能的“身体设备”,为老年人提供全方位的健康管理和情感陪伴,从而减轻他们的孤独感和抑郁问题。
尽管AI在模仿人类“对话专注力”方面取得了令人振奋的进展,但通往“超人听力”的道路并非坦途,仍面临诸多现实的“杂音”和未解之谜。
华盛顿大学的原型系统,虽然在受控测试中表现出色(识别准确率达80-92%,语音清晰度提升14.6dB),但也存在局限性:它高度依赖佩戴者的自言自语,长时间的沉默会使其“困惑”;重叠的讲话和同时轮流转换仍然是挑战;此外,该方法不适用于被动聆听,因为它假设用户是积极的对话参与者。
业界对此也持有审慎态度。AI眼镜公司SoftEye的CEO李泰元(Te-Won Lee)指出,真实世界的声景远比实验室环境复杂得多,充斥着音乐、不可预测的噪音和频繁的打断。在这些混沌场景中,模型的性能可能会下降。他认为,传统的盲源分离和语音增强技术,在处理不可预测的噪音环境方面可能更具鲁棒性。
更深层次的挑战来自AI自身的特性。
这些问题提醒我们,AI助听技术的发展,不仅是技术层面的突破,更是对人类听觉、认知和社会互动方式的深刻反思。
展望未来,AI对人类“对话专注力”的模仿,无疑将开启人与声音互动的新篇章。随着大语言模型(LLM)与听力技术的深度融合,未来的听力助手将不仅仅识别“谁在说话”,更将理解“谁在有意义地贡献”,从而实现更灵活、更具人性的对话跟随。
例如,讯飞星火智能验配师正从1.0升级到2.0,通过多轮对话收集更精细的听力问题,智能优化助听器的音质以及降噪参数。腾讯天籁行动则致力于开放音频AI技术,提升助听设备的降噪效果,并构建远程听力服务平台,让听力健康服务覆盖前期筛查、中期诊疗到后期验配的全链条。
这场科技浪潮不仅关乎听力障碍的解决,更触及人类认知的本质。当机器能够模仿我们最精微的感官与认知能力时,我们与技术的关系将变得更加共生。AI不再仅仅是工具,它开始成为我们感官的延伸,甚至是我们认知过程的辅助者。然而,我们也需警惕,在享受技术带来便利的同时,不应放弃人类自身的核心能力。真正的进步,或许在于找到一个平衡点:让AI成为我们重拾与世界连接的桥梁,而非取代我们感知和理解世界的本能。
最终,AI助听器所描绘的未来,是一个人人都能在喧嚣中清晰聆听、在交流中自由表达、在生活中感受温暖的世界。这不仅是科技的胜利,更是人性的回归,它将帮助我们所有人,在日益嘈杂的现代生活中,重新找回那份久违的“对话专注力”,让生命的旋律更加和谐动听。