对抗知识焦虑,从看懂这条开始
App 下载
不用搭Elasticsearch,数据库里也能搜全文
SQL查询|BM25算法|全文搜索|FTS扩展|DuckDB|软件工程|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载SQL查询|BM25算法|全文搜索|FTS扩展|DuckDB|软件工程|前沿科技
想象你面对13000多封杂乱的.eml邮件,要找出所有聊到“预算”的内容——用SQL的LIKE?得等上好几分钟,还会漏掉“budgets”“budgeting”这类变形;搭个Elasticsearch?光是部署配置就得花大半天。但现在,有个工具能让你在熟悉的数据库里,用几行SQL就完成精准的全文搜索,甚至还能给结果按相关性打分排序。这就是DuckDB刚推出的FTS扩展,它把专业搜索引擎的核心能力,直接搬进了轻量级分析数据库里。问题是,它怎么做到不用额外服务,还能保证搜索的准确性?
你可以把全文搜索的评分逻辑,比作老师改作文——过去的LIKE只看“有没有用到关键词”,就像只看作文里有没有出现“梦想”这俩字;而DuckDB用的Okapi BM25算法,是看“这篇作文有多贴合‘梦想’这个主题”。
它的核心逻辑拆成三步:首先看关键词在单篇文档里出现的频率——就像作文里“梦想”出现3次比只提1次更切题,但也不是越多越好,重复10次和重复8次的差别其实不大,这就是“词频饱和”;然后看关键词在整个文档库的稀有度——如果“梦想”是个所有人都用的烂大街词,那它的区分度就很低,这是“逆文档频率”;最后还要给长文档打个折——一篇1000字的作文里提3次“梦想”,和一篇100字的作文里提3次,显然后者更聚焦,这就是“文档长度归一化”。
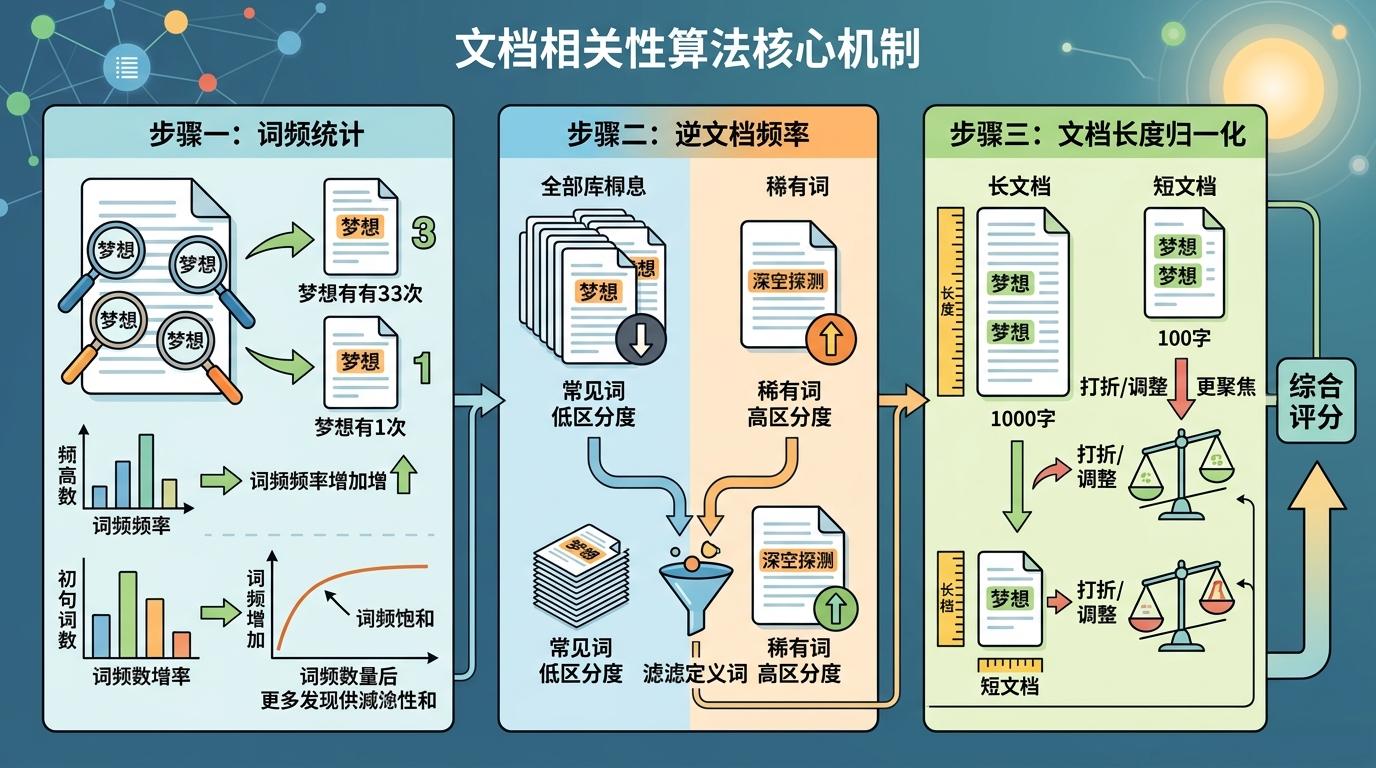
用公式总结就是:每一个关键词的得分,是「稀有度」乘以「(词频×(k₁+1))÷(词频 + k₁×(1 - b + b×文档长度/平均长度))」,最后把所有关键词的得分加起来。其中k₁控制词频的饱和速度,b控制长度惩罚的强度——默认值k₁=1.2、b=0.75,刚好适配大多数通用文本场景。
你搜“talk”,希望能同时找到“talked”“talking”甚至“talks”,这就得靠词干提取——把各种变形的词语“卸妆”,还原到最核心的词根。DuckDB用的是Snowball项目提供的算法,它就像一个熟练的化妆师,能精准去掉“-ed”“-ing”这类后缀,把“walking”变回“walk”,把“cats”变回“cat”。
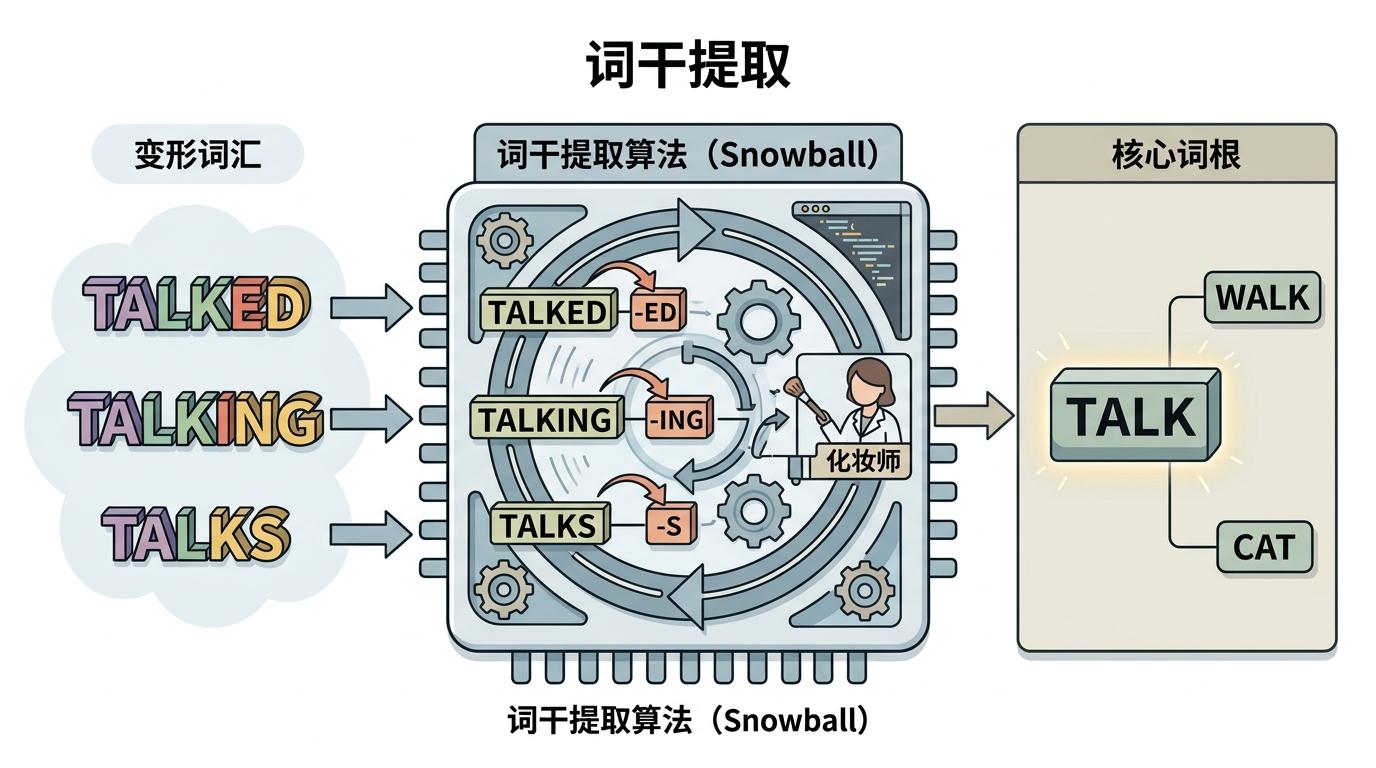
但它也有失手的时候:比如“mouse”和“mice”,这种不规则的复数变化,它就认不出来;还有“go”和“went”,也没法归到同一个词根。这时候你就得靠手动调试——用Python的snowballstemmer库,提前测试每个关键词的处理结果,避免出现“搜不到”的尴尬。
除了词干提取,DuckDB还会自动过滤掉“the”“and”这类停用词——就像改作文时去掉那些凑字数的废话;还能把“ᔓä”都变成“a”,统一字符格式。这些预处理步骤,就像给文档“洗了个澡”,让搜索结果更干净准确。
DuckDB FTS的优点很明显:不用搭额外服务,几行SQL就能创建索引、完成搜索;和分析任务无缝集成——你可以在搜索结果上直接跑统计、做可视化;速度也够快,百万级文本的查询响应时间能压到毫秒级。
但它也有绕不开的短板:索引不会自动更新——如果你新增了100封邮件,得手动删掉旧索引重建;没有高亮功能——找到匹配的文档后,你得自己去翻正文找关键词在哪;也不支持短语搜索——你搜“New York”,它可能会返回分别包含“New”和“York”的文档,而不是同时出现这两个词的短语。
说白了,它更适合“探索式分析”——比如你拿到一批陌生的文本数据,想快速看看里面都在聊什么;或者中小规模的日常搜索——比如公司内部的邮件归档检索。但如果是需要实时更新、高并发访问的生产场景,或者需要同义词、拼写纠错这类高级功能,你还是得回到Elasticsearch这类专用引擎。
当我们在讨论全文搜索时,其实一直在平衡“能力”和“成本”——专用引擎功能强大,但部署维护的成本也高;数据库内置的搜索功能虽然简单,但胜在不用额外折腾。DuckDB FTS的出现,就是给了数据分析者一个新选项:在不需要复杂功能的时候,不用再为了搜个文本,去搭一整套重型架构。
它就像一个随身的多功能工具刀,虽然不能取代专业的电锯、锤子,但日常拆个快递、拧个螺丝足够好用。轻量不等于简陋,合适才是最优解。未来也许会有越来越多的数据库,把这类“刚刚好”的能力内置进去,让数据分析的门槛,再低一点。