对抗知识焦虑,从看懂这条开始
App 下载
生成32位素数:从24分钟到32秒的算法竞速
算法效率|试除法|埃拉托斯特尼筛法|C语言实现|32位素数|计算科学|数理基础
对抗知识焦虑,从看懂这条开始
App 下载算法效率|试除法|埃拉托斯特尼筛法|C语言实现|32位素数|计算科学|数理基础
2026年初,一位开发者在Linux环境下发起了一场特殊竞速:用C语言生成所有32位无符号整数范围内的素数,并写入文件。最开始他用了最直观的试除法,结果程序跑了24分20秒才完成。不甘心的他加了轮筛优化,把时间压缩到23分30秒——这点提升几乎可以忽略不计。直到他用上了公元前3世纪就诞生的埃拉托斯特尼筛法,程序只用32秒就输出了结果,速度提升了45倍。为什么一个2300年前的算法,能把现代优化的试除法甩在身后?这背后藏着素数生成算法最核心的效率逻辑。
试除法的逻辑简单到像小学生做算术:要判断一个数是不是素数,就用小于它平方根的所有素数挨个试除,都除不尽就是素数。为了优化,开发者会跳过偶数,甚至用轮筛法预先剔除2、3、5的倍数——比如模30的轮筛,只检查余数为1、7、11等8种情况的数,理论上能减少80%的候选数。
但试除法的本质是「逐个验证」,每一个候选数都要重复一轮除法运算。哪怕是轮筛优化,剔除的也只是最容易判断的合数——那些能被小素数整除的数,本来用试除法也能在几步内排除,节省的时间对整体流程影响极小。这就像你要从一堆沙子里挑出黄金,每颗沙子都要拿放大镜看一遍,哪怕先筛掉明显的石头,剩下的沙子还是得挨个检查。
埃拉托斯特尼筛法的思路则完全相反:它先把所有数排成一列,从2开始,把2的所有倍数标记为合数;接着找到下一个未标记的数3,再标记3的所有倍数;以此类推,直到筛到目标数的平方根。最后剩下的未标记数,全都是素数。这相当于先在沙子里撒上能粘住黄金的磁铁,直接把所有黄金吸出来,不用挨个检查。
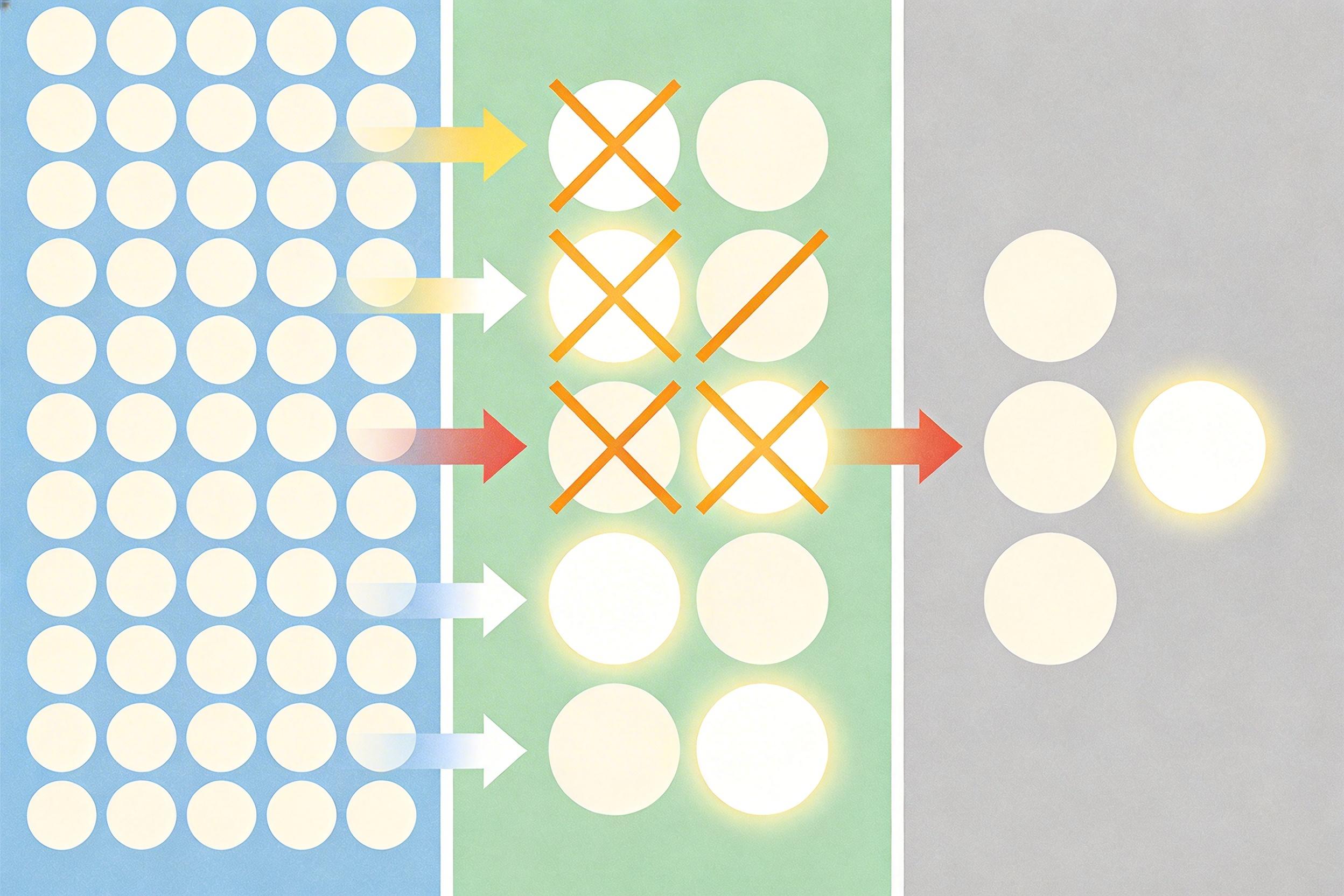
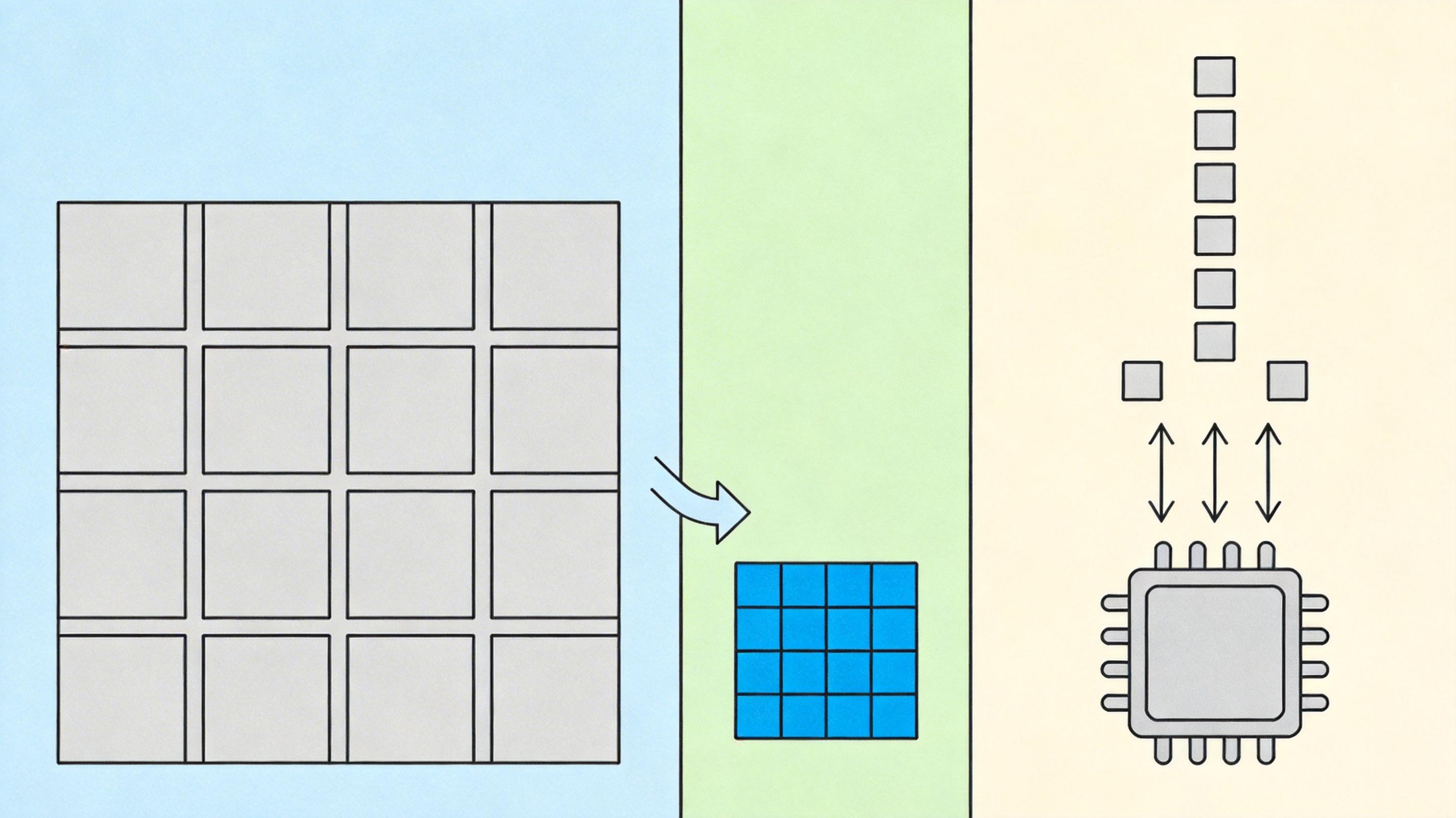
埃拉托斯特尼筛法的问题也很明显:传统实现需要一个能容纳所有目标数的数组,生成32位素数时,光是存储布尔值就要4.3GB内存——这显然不现实。但开发者用了两个关键优化,把这个2300年前的算法盘活了。
第一个优化是用位数组代替布尔数组。每个布尔值占1字节,而位数组能把8个状态塞进1字节,直接把内存需求降到537MB,刚好在1GB的限制内。第二个优化是分段筛法:把整个32位范围分成一个个适合CPU缓存的小块,每次只处理一块数据,用完就释放内存。这就像你不用把整堆沙子都搬回家,而是分成小份,每份用磁铁吸完就倒掉,既省空间又能利用缓存提升速度。
我认为,埃拉托斯特尼筛法的逆袭,本质是「批量处理」对「逐个验证」的碾压。试除法的时间复杂度是O(n^1.5 / log²n),而筛法是O(n log log n)——当n大到32位整数的上限时,后者的效率优势会被无限放大。就像你数1000颗豆子,一颗一颗数要10分钟,但用秤称出总重量再除以单颗重量,可能只需要10秒。
开发者最终用筛法实现的程序跑了32秒,但这还不是终点。Kim Walisch开发的primesieve库,能在0.061秒内生成所有32位素数——速度又提升了500多倍。它的核心是把分段筛和轮筛法结合,还利用了CPU的L1、L2缓存特性,甚至支持多线程并行处理。
但primesieve的优化已经触及了当前硬件的天花板。再要提升效率,可能就要等待新的数学发现或硬件革命了。比如基于椭圆曲线的素性测试算法,或者量子计算的应用——不过量子计算也可能反过来破解基于素数的密码体系,这又是另一个悖论。
更值得关注的是,素数生成算法的竞争,从来都不是为了生成那2亿多个32位素数,而是为了探索「效率」的本质:如何用最少的计算资源,解决最复杂的问题。从试除法到筛法,再到primesieve,每一次效率的飞跃,都是对计算逻辑的一次重构。
当开发者最终验证生成的素数文件SHA-256哈希值正确时,这场算法竞速才算真正结束。从24分钟到32秒,再到0.061秒,数字的变化背后,是人类对素数规律的不断理解,也是对计算效率的极致追求。
最好的算法,往往是最贴合问题本质的算法。 埃拉托斯特尼筛法的重生告诉我们,有时候最先进的技术,不过是把古老的智慧用对了地方。未来的素数生成算法会走向何方?可能是AI辅助筛选,也可能是量子计算的突破,但不变的,是人类对「更快、更省、更准」的永恒探索。