对抗知识焦虑,从看懂这条开始
App 下载
AI训练的隐形陷阱:样本顺序决定模型命运
模型参数偏移|人脸属性识别|Lie括号|训练数据顺序|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型参数偏移|人脸属性识别|Lie括号|训练数据顺序|大语言模型|人工智能
你或许从未留意过:给AI喂训练数据的顺序,居然能悄悄改变它的“智商”。我们一直默认,只要数据集足够好,先喂猫照片还是先喂狗照片,对最终模型没区别——毕竟从数学上看,理想的机器学习模型应该对样本顺序“免疫”。但2023年的一项研究彻底打破了这个假设:研究者用一种叫Lie括号的数学工具,精确算出了交换两个训练样本顺序后,模型参数的细微偏移,结果远超预期。更诡异的是,在人脸属性识别任务中,“黑发”和“棕发”这两个属性的预测结果,对样本顺序的敏感度远高于其他特征。这背后藏着怎样的秘密?
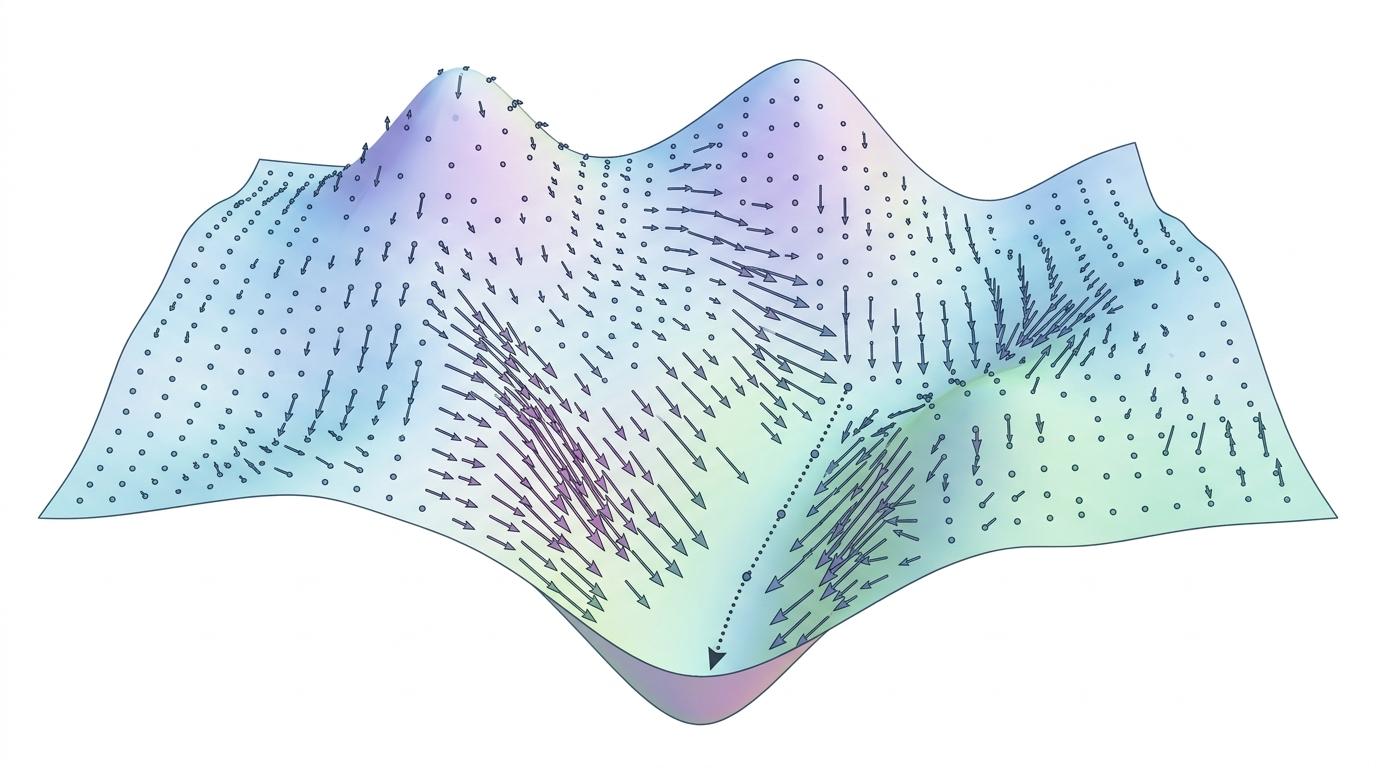
你可以把神经网络的参数空间想象成一片布满箭头的荒野——每个训练样本就是一个指向特定方向的箭头,它会“推”着模型参数往降低损失的方向挪一步。这个由样本定义的“箭头场”,在数学上叫向量场(vector field),对应每个样本的负梯度:$v^{(x)}(\theta) = -
abla_{\theta} \mathcal{L}^{(x)}$。
平时我们说的梯度更新,就是顺着这个箭头,以学习率为步长往前走一小步:$\theta' = \theta + \epsilon v^{(x)}(\theta)$。但问题在于,这些箭头不是孤立的——当你先跟着样本x的箭头走,再跟着样本y的箭头走,和反过来走,最终到达的位置居然不一样。
这就是关键:两个向量场的“先后作用”不满足交换律。而量化这种非交换性的工具,就是Lie括号(Lie bracket)。它的公式看起来复杂:$[v^{(x)}, v^{(y)}] = (v^{(x)}\cdot abla_\theta) v^{(y)} - (v^{(y)}\cdot abla_\theta) v^{(x)}$,但核心意思很简单:它算出了“先x后y”和“先y后x”两种路径的参数差。通过泰勒展开能更直观看到,这个差异是和学习率平方成正比的二阶小量——单次交换影响微小,但训练上万步后,累积的偏移足以让模型性能天差地别。
研究者在CelebA人脸数据集上做了实验:用MXResNet训练40个人脸属性的预测模型,每训练一定步数就计算测试样本的Lie括号。结果发现,训练到600步之后,“黑发”和“棕发”这两个属性的预测结果,对样本顺序的敏感度突然飙升——交换任意两个样本的顺序,这两个属性的输出波动远大于其他特征。
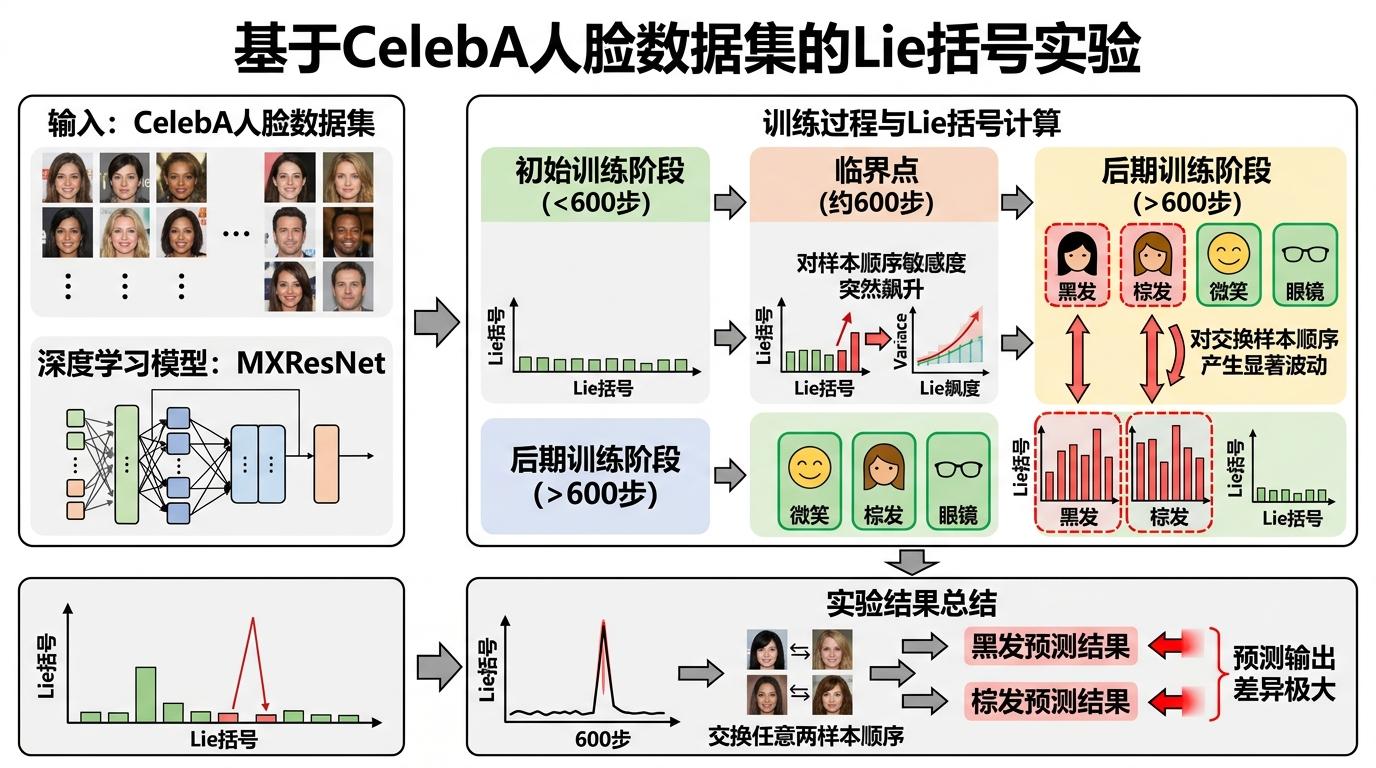
为什么偏偏是这两个属性?答案藏在数据集和损失函数的矛盾里:在真实世界中,一个人的头发不可能同时是黑色和棕色,但模型的损失函数默认这40个属性是相互独立的。当照片里的头发颜色因光线模糊时,模型会给“黑发”和“棕发”各打50%的概率,损失函数会把这解读为“25%概率同时是黑棕发”——但这在现实中不可能发生。
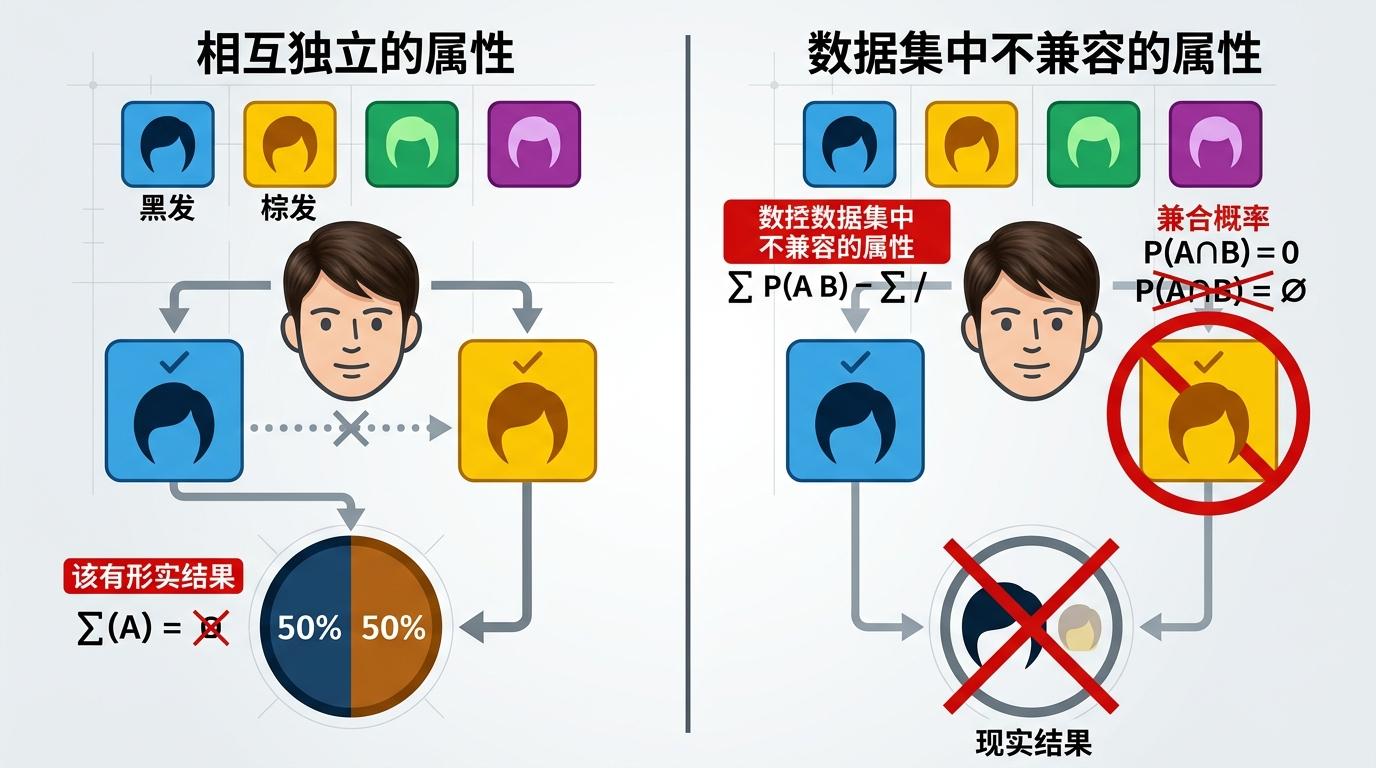
这种损失函数的“先天缺陷”,让模型在这两个属性上的训练始终处于“拧巴”的状态:它想表达“非黑即棕”,但损失函数逼它输出独立概率。这种内在矛盾,直接放大了样本顺序对参数更新的影响——就像一个人在两个相反的推力下,稍微调整施力顺序,就能让他彻底失去平衡。
实验还发现了一个更普遍的规律:Lie括号的幅度和对应梯度的幅度高度相关。也就是说,样本对参数影响越大,它们的顺序交换带来的偏移也越大。这意味着,那些对模型训练更“重要”的样本,反而成了顺序敏感的重灾区。
样本顺序的影响不止是学术问题,更藏着致命的安全隐患。2021年的研究就发现,攻击者不需要篡改任何样本内容,只要在训练时恶意调整样本顺序,就能让模型性能大幅下降,甚至悄悄植入后门——比如让模型在看到特定触发词时输出错误结果。
这种攻击的原理很直接:利用Lie括号揭示的非交换性,恶意的顺序会让模型的参数更新始终偏离最优路径,甚至陷入局部死循环。更可怕的是,这种攻击几乎无法被检测到——因为所有样本都是合法的,只是顺序被调整了。在金融风控、医疗诊断这些高敏感领域,模型性能的微小偏移都可能引发严重后果。
当然,我们也有应对的办法:最基础的就是每个训练周期都随机打乱样本顺序,让模型无法学习到固定的顺序模式;进阶的方法是结合课程学习——先喂简单样本,再逐步引入复杂样本,但同时加入随机扰动,避免过于严格的顺序依赖;还有研究者正在尝试用Lie括号的信息主动调整样本顺序,引导模型更快收敛到更稳定的参数区域。
但这些方法都只是“缓解”而非“根治”。毕竟,神经网络的参数空间是一个高维的非凸荒野,我们对它的理解还只是冰山一角。
当我们把神经网络当成一个“黑箱”时,很容易忽略这些看似无关的细节——样本的顺序、损失函数的假设、梯度的微小波动。但Lie括号的发现告诉我们:AI的“智能”不是凭空出现的,它是每一个训练样本、每一次参数更新、每一个数学假设共同作用的结果。
细节里藏着AI的真实逻辑。 我们总以为AI是“客观”的,但它的决策其实被无数看不见的因素影响——样本的顺序、数据的偏见、损失函数的缺陷。未来的AI研究,不仅要追求更高的准确率,更要理解这些“看不见的手”,才能让AI真正成为可靠的工具。
就像人类的学习一样,你学的知识很重要,但学习的顺序、方式,甚至当时的心情,都会悄悄改变你对世界的认知。AI也一样,它的“智商”从来不是由数据集的大小决定的,而是藏在每一个被我们忽略的细节里。