对抗知识焦虑,从看懂这条开始
App 下载
CERN把AI硬烧进芯片,每秒筛掉千万亿字节数据
芯片级AI|纳秒级数据筛选|Level-1触发系统|LHC|CERN|高能物理|AI产业应用|数理基础|人工智能
对抗知识焦虑,从看懂这条开始
App 下载芯片级AI|纳秒级数据筛选|Level-1触发系统|LHC|CERN|高能物理|AI产业应用|数理基础|人工智能
想象一下:27公里长的环形隧道里,两束质子以99.9999991%的光速对撞,每25纳秒就炸出一堆粒子碎片——这场景每秒要重复4000万次。每一次碰撞都会产生数兆字节数据,全年下来的总量是40000艾字节,相当于把全球互联网流量的四分之一塞进一个实验室。
但没有任何硬盘能装下这些数据,甚至连传输都来不及。CERN必须在粒子碎片飞散的瞬间——也就是50纳秒内——判断:这堆数据里有没有可能藏着暗物质的线索?还是说,它只是毫无价值的宇宙“噪音”?答案是把超小型AI直接“焊”在芯片里,让硅片自己做决定。
你可以把LHC的数据筛选想象成机场安检,但速度要快1000万倍:每25纳秒就有一架“飞机”降落,你必须在50纳秒内决定是放行还是直接销毁——没有存档,没有复核。这就是LHC的Level-1触发系统,由1000块FPGA芯片组成的“第一道闸门”。

过去,这道闸门靠硬编码的物理规则运行:比如“能量超过某个阈值的事件留下”。但这种规则会漏掉不符合预期的新物理现象——比如暗物质粒子可能根本不会触发预设阈值。2023年,CERN把名为AXOL1TL的AI算法塞进了这些FPGA芯片。
AXOL1TL是个极度精简的变分自编码器,它不管粒子的能量有多高,只看“这堆粒子的组合是不是常见”。训练它的数据是数百万次普通碰撞事件,它会把这些“正常”事件的特征刻进参数里。当一个罕见的、可能藏着新物理的事件出现时,它会因为“无法理解”这个组合而触发警报——这就是无监督异常检测的逻辑。
但要在50纳秒内完成这个判断,普通AI模型根本做不到。CERN的工程师用了三把“压缩刀”:把32位浮点数压缩成8位整数(量化),剪掉90%以上的冗余神经元(剪枝),让小模型模仿大模型的判断逻辑(知识蒸馏)。最终的模型小到能直接“烧”进FPGA的硅电路里,不需要调用内存,不需要等待数据传输——运算就在触发事件的瞬间完成。
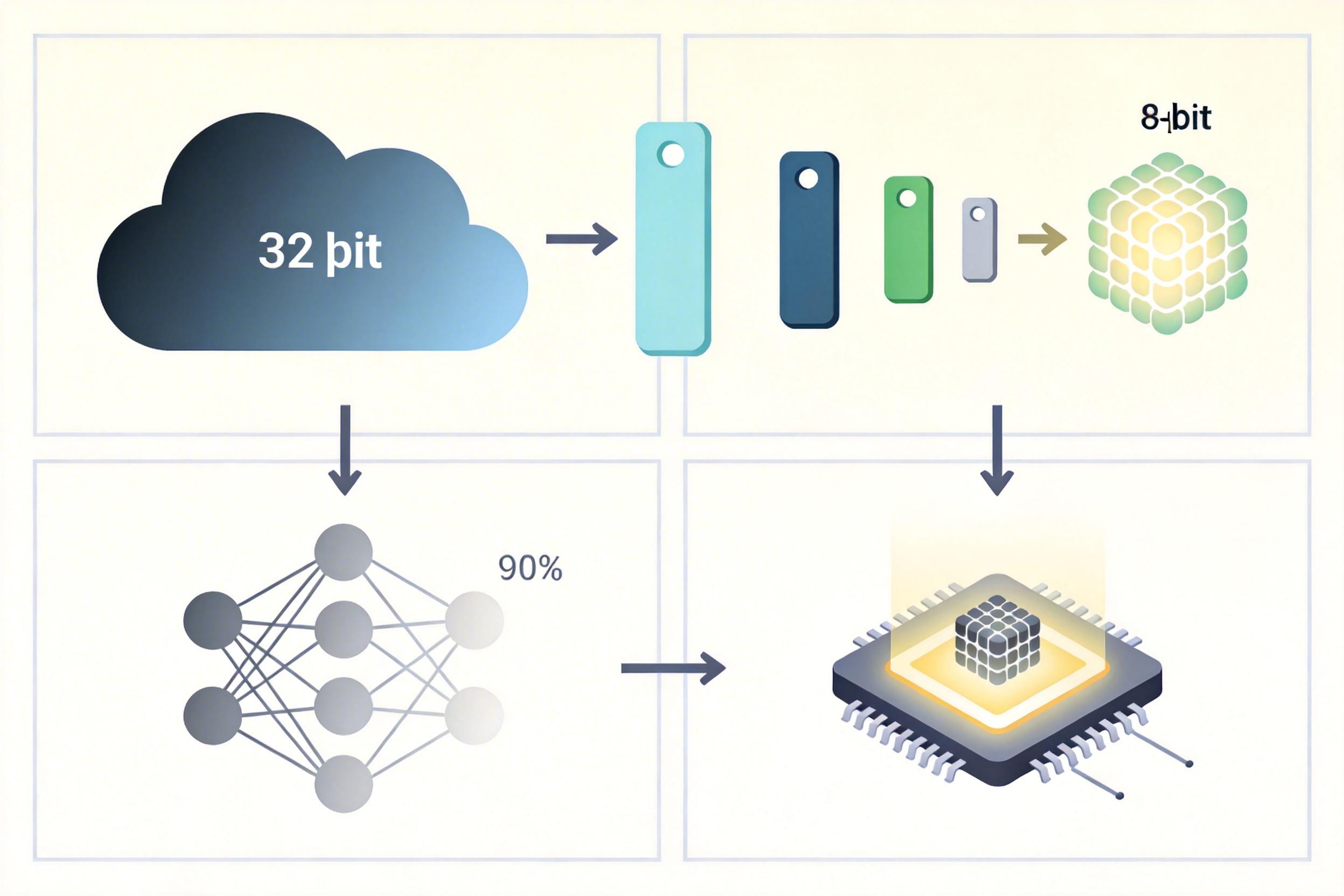
把AI模型“烧”进芯片不是把代码复制进去那么简单。传统的FPGA编程需要用硬件描述语言(HDL),这是芯片工程师的专属技能,物理学家根本看不懂。2018年,CERN和费米实验室联合开发了HLS4ML工具链——它就像一个翻译官,能把PyTorch、TensorFlow里写的AI模型,自动转换成FPGA能读懂的硬件逻辑。
举个例子,CICADA算法是另一个用于LHC的AI模型,它把探测器的能量分布当成“图像”,用卷积自编码器找异常。最初的“教师模型”有30万个参数,根本塞不进FPGA。工程师用知识蒸馏技术,把它压缩成只有1万个参数的“学生模型”,再用HLS4ML转换成硬件代码。为了进一步提速,他们把模型里的乘法运算全部换成了查找表——提前算好所有可能的输入对应的输出,让芯片直接“查表”而不是现场计算,把延迟从微秒级压到了纳秒级。
这种“硬件优先”的设计思路,完全颠覆了传统AI的玩法。通常我们是先做模型,再找硬件跑;但CERN是先看硬件能提供什么:FPGA有多少个逻辑单元,多少个查找表,延迟极限是多少——然后反过来设计刚好能塞进这些资源的模型。比如AXOL1TL的V5版本,整个模型只有3层全连接层,总共52个神经元,却能比传统触发系统多识别46%的罕见事件。
当然,这种极致优化也有代价:这些AI模型只能干“找异常”这一件事,换个任务就完全没用。但在LHC的场景里,专一就是最大的效率——它不需要理解语言,不需要生成图片,只需要在50纳秒内说“留”或“扔”。
LHC的隧道里不是实验室的恒温环境,这里的辐射剂量是太空的100倍——普通芯片在这里撑不过一天就会被辐射打坏。CERN的工程师必须解决另一个难题:让AI芯片在强辐射下稳定工作10年以上。
哥伦比亚大学的Peter Kinget团队为ATLAS探测器设计了专用的ADC芯片,它采用商业130nm CMOS工艺,但加了三重冗余电路:同一个计算会在三个独立的模块里做,然后投票选结果——只要不是三个模块同时被辐射打坏,就能保证数据正确。他们还把芯片里最容易被辐射影响的电容DAC做了特殊加固,通过调整电路布局和尺寸,把辐射诱发的故障率降低了1000倍。
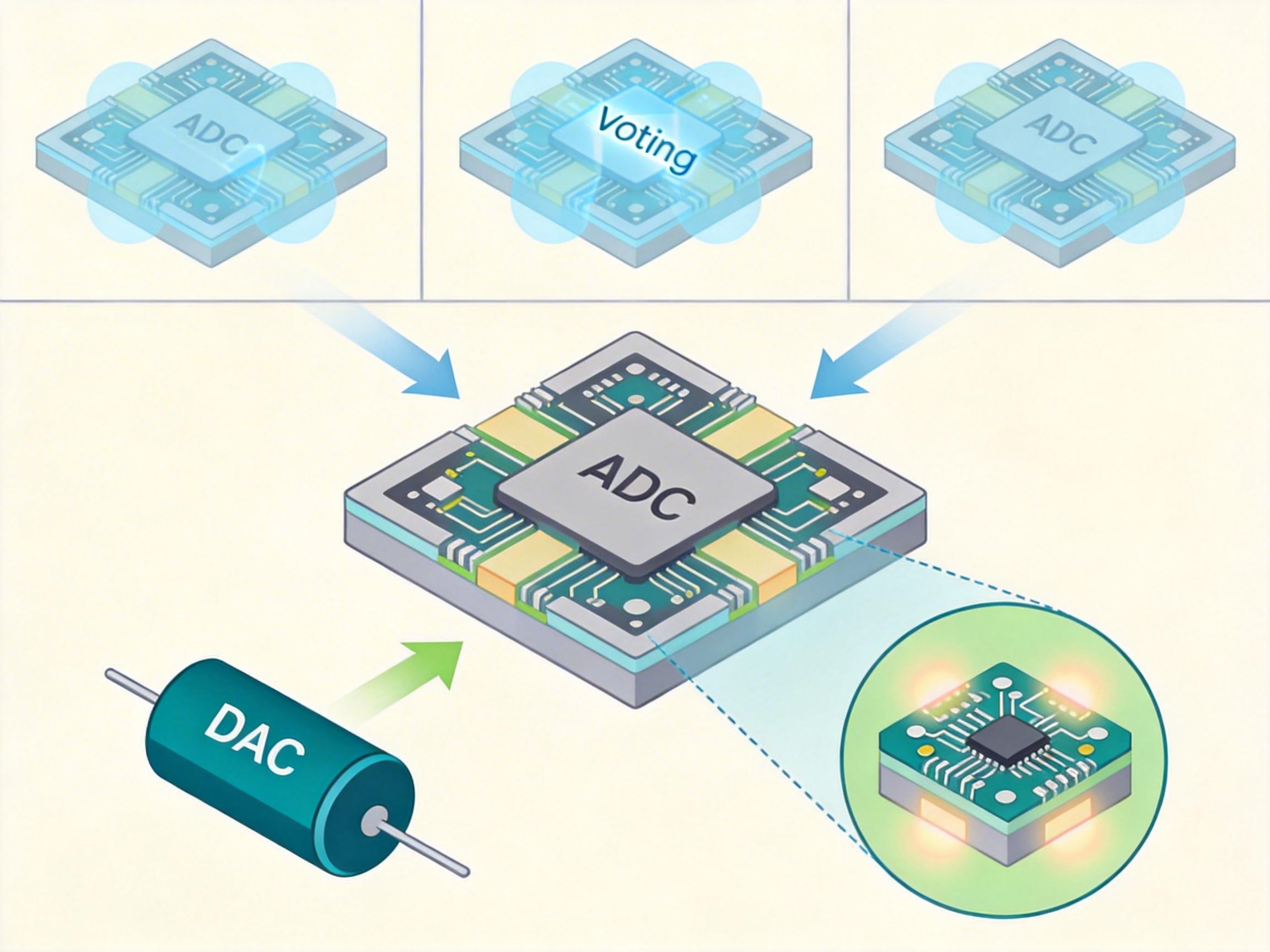
FPGA芯片也做了耐辐射处理:Xilinx的Virtex-7 FPGA采用了“辐射硬化”工艺,能抵抗总电离剂量高达100千拉德的辐射。工程师还在AI模型里加了容错设计:比如某个神经元被辐射打坏了,模型会自动跳过它,用其他神经元的结果补全——就像人失去了一个手指,还能用剩下的手指写字。
这些细节听起来不起眼,但正是它们让AI芯片能在LHC的极端环境里持续工作。2022年安装的第一批触发ADC芯片,至今已经运行了4年,没有出现过一次致命故障——它们每天要处理10亿次碰撞数据,相当于每秒做1000万次AI推理。
当整个AI行业都在追求“更大的模型、更多的参数”时,CERN反其道而行之,把AI压缩到了极致。这种“小而专”的思路,正在改变我们对AI的认知:AI不一定是要无所不能的“通用大脑”,也可以是嵌入硅片里的“专用开关”。
2031年,高亮度LHC将启动,那时的数据量会是现在的10倍,每一次碰撞会产生200个重叠事件。CERN的工程师已经在研发下一代AI芯片,它会更小、更快、更耐辐射——可能会用异构量化Transformer,也可能会用更高效的决策树模型。
极致的专一,才是极致的效率。这句话不仅适用于LHC的AI芯片,也适用于所有被“大而全”绑架的技术领域:有时候,把一件事做到极致,比什么都做但什么都做不好更有价值。