对抗知识焦虑,从看懂这条开始
App 下载
数据库并发之争:锁与版本,两种秩序的哲学对决
电商平台|事务一致性|多版本并发控制|锁机制|数据库并发控制|计算科学|数理基础
对抗知识焦虑,从看懂这条开始
App 下载电商平台|事务一致性|多版本并发控制|锁机制|数据库并发控制|计算科学|数理基础
想象一下,年度最大的购物节零点钟声敲响,数百万用户涌入一个电商平台,争抢一件限量版商品。在你看不到的服务器后台,一场无声的战争正在上演。当两个用户在同一毫秒点击“购买”最后一件库存时,系统如何决定谁是赢家?它如何确保库存不会被减成负数,订单不会重复创建,支付不会混乱?
这场战争每时每刻都在发生。从银行转账到社交媒体点赞,全球每天有数以万亿计的数据库“事务”在执行。它们是数字世界的基石,悄无声息地维护着我们习以为常的秩序。一个“事务”,就是一系列必须作为一个整体、不可分割地完成的操作。它要么全部成功,要么全部失败,绝不允许停在中间状态。这种承诺,就是数据库世界著名的ACID原则——原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
然而,当成千上万的事务试图同时操作同一份数据时,混乱的幽灵便开始游荡。如果缺乏有效的管理,数据库就会出现“脏读”(读到别人未提交的脏数据)、“不可重复读”(同一事务内两次读取结果不一)和“幻读”(两次范围查询,结果集无端多出或减少)等诡异现象。为了驱散这些幽灵,数据库工程师们设计了精密的并发控制机制。而在这场旷日持久的战争中,两大最受欢迎的开源关系型数据库——MySQL和PostgreSQL,走上了两条截然不同的哲学道路。
为了让多个事务在互不干扰的情况下同时工作,即实现“隔离性”,MySQL和PostgreSQL都采用了名为**MVCC(多版本并发控制)**的先进思想。其核心理念是:读操作不应该被写操作阻塞。与其让读者排队等待作者完稿,不如给读者一份作者动笔前的“快照”。然而,如何保存和管理这些“快照”,两位大师给出了不同的答案。
PostgreSQL:严谨的历史学家
PostgreSQL选择了一种近乎偏执的方式来记录历史。当一行数据被更新时,它从不直接覆盖旧数据。相反,它会创建一个全新的数据行版本,并将旧版本保留下来。每一行数据都像一份历史档案,带有两个关键的时间戳:xmin(创建该版本的事务ID)和xmax(废弃该版本的事务ID)。

xmin属于“过去”且xmax不属于“过去”的版本。这样,每个事务都活在自己专属的、凝固的时间切片里,看不到其他并发事务所做的未提交修改。这种方法的优点是读取历史版本非常快,因为它就是物理存在的。但代价也显而易见:数据库会像博物馆一样,堆积大量不再需要的旧版本(被称为“死元组”)。为此,PostgreSQL必须雇佣一位勤勉的“清洁工”——VACUUM进程,定期巡视并清理这些历史尘埃,回收空间。
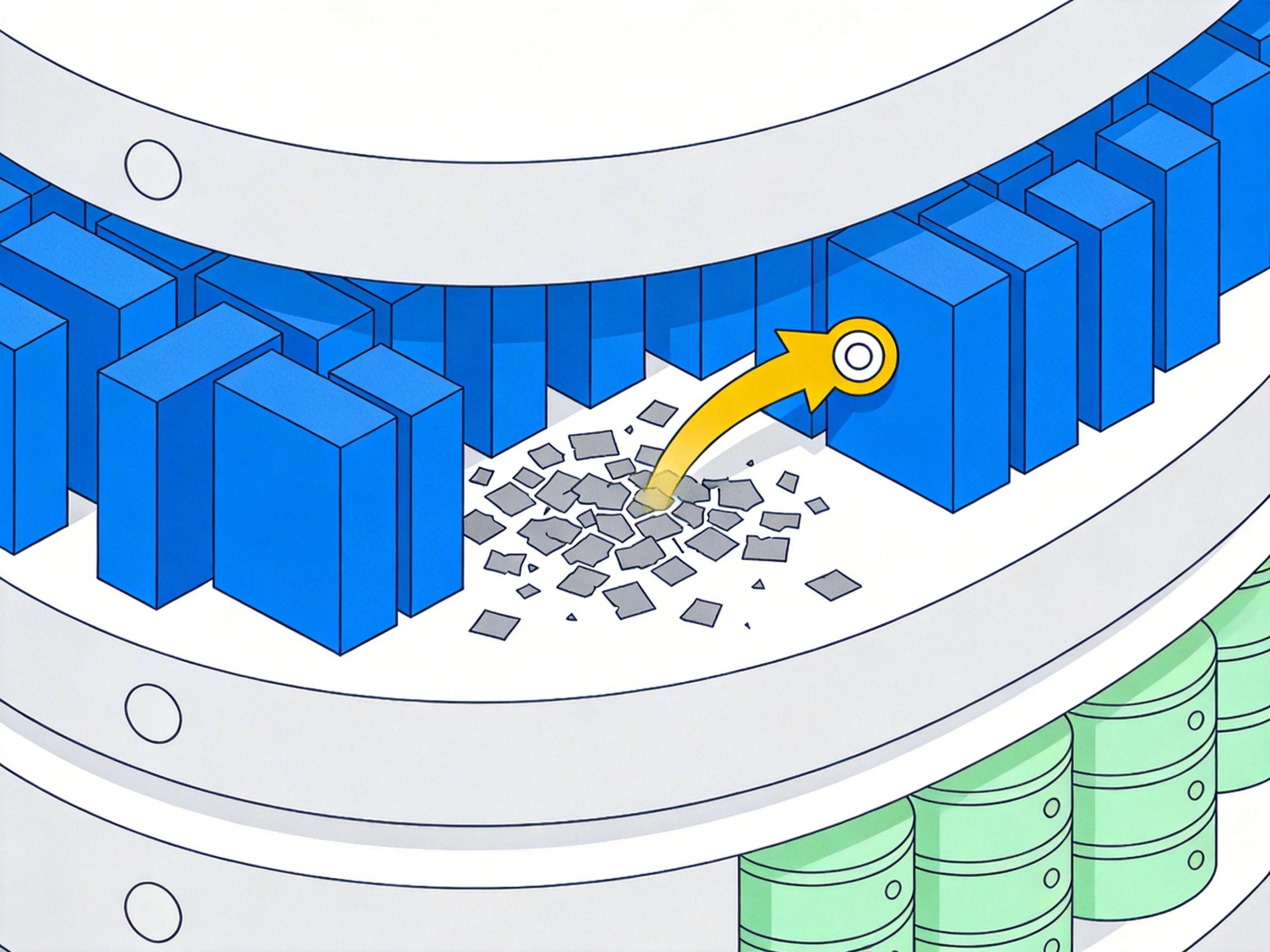
MySQL:精明的会计师
相比之下,MySQL(特指其默认的InnoDB引擎)则像一位注重效率的会计师。当数据更新时,它会直接在原地覆盖旧数据,保持数据文件的整洁。那么,历史版本去哪了?
答案藏在一个名为**Undo Log(撤销日志)**的账本里。每次修改数据前,MySQL会先把旧数据的模样记录到Undo Log中。这些日志被一个名为roll_pointer的指针串联起来,形成一条版本链。
roll_pointer指针回溯Undo Log,一步步地“撤销”后续的修改,直到构建出该事务所需要的那个“快照”版本。这种方式让主数据文件保持紧凑,无需频繁的大规模清理。但代价是,读取旧版本数据可能需要一个动态的、相对耗时的重构过程。它牺牲了历史读取的便利性,换取了存储空间的效率和更简单的维护模型。
当两个事务不只是读取,而是要同时修改同一行数据时,真正的哲学分歧出现了。这就像两辆车要同时驶入一个单行道,必须有一套交通规则。
MySQL的悲观主义:先上锁,再通行
MySQL天性谨慎,它采用的是悲观锁策略。它认为冲突是大概率事件,所以最好提前预防。当一个事务要修改某行数据时,它会先申请一个排它锁(Exclusive Lock)。这个锁就像一个“请勿打扰”的牌子,一旦挂上,其他任何想修改这行数据的事务都必须在门外排队等待,直到前一个事务完成并释放锁。
这种方式简单直接,规则清晰。但缺点是,如果一个持有锁的事务执行缓慢,后面的所有事务都会被阻塞,导致性能瓶颈。更糟糕的是,如果两个事务互相等待对方持有的锁,就会陷入**死锁(Deadlock)**的尴尬境地,就像两条首尾相接的贪吃蛇,谁也动弹不得。好在MySQL有自动的死锁检测机制,会选择“牺牲”一个事务来打破僵局。
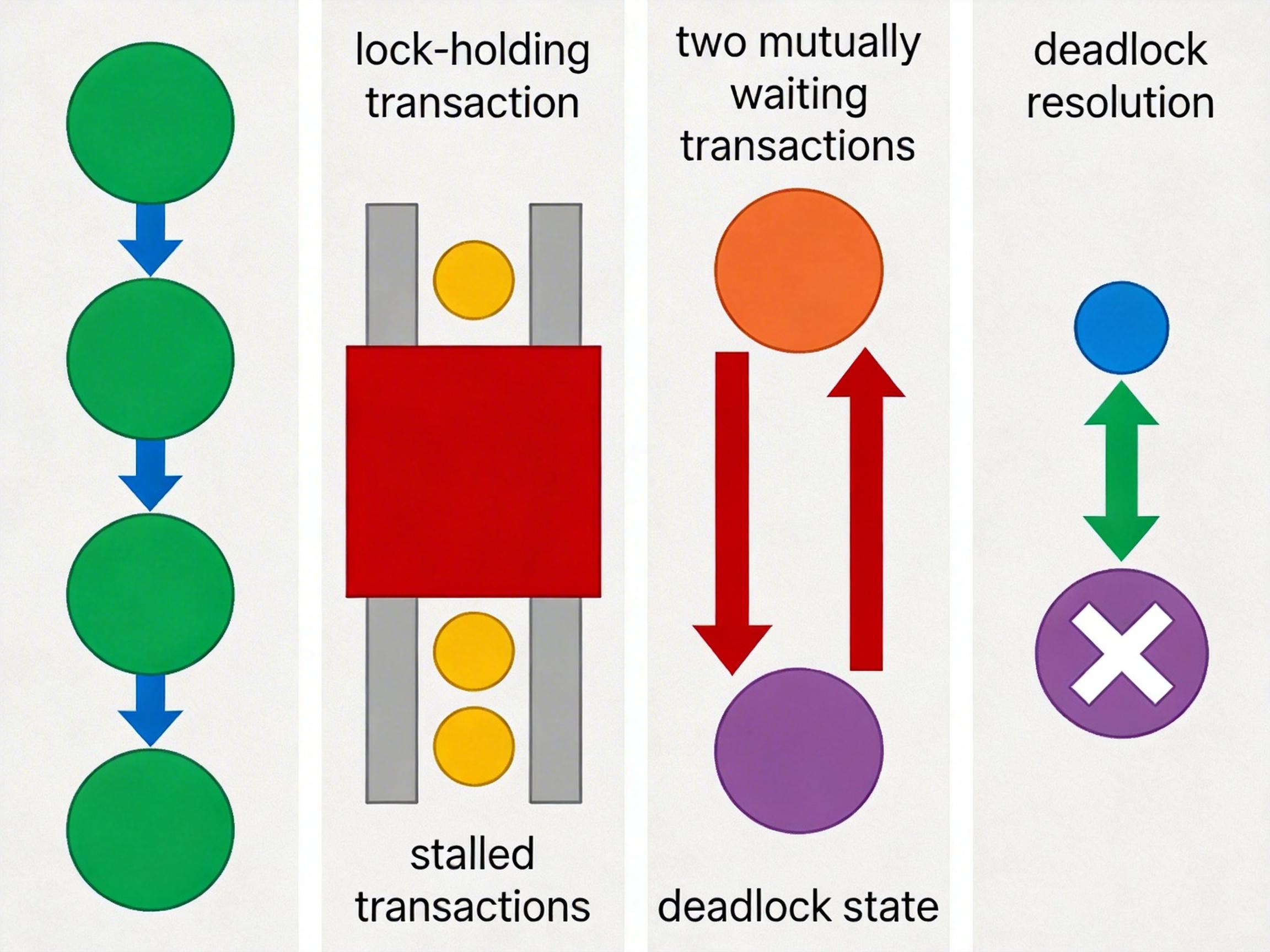
PostgreSQL的乐观主义:先通行,后裁决
PostgreSQL则更加乐观。它采用乐观并发控制,认为事务间的直接冲突是小概率事件。它允许事务自由地执行,不会因为写操作而轻易阻塞其他事务。它不使用传统的行锁来阻止写入,而是通过一种更高级的机制——**谓词锁(Predicate Locks)**来“监视”事务读取和写入的数据范围。
直到事务准备提交时,PostgreSQL才会进行冲突检测。如果它发现某个事务的执行破坏了“可串行化”的隔离保证(即执行结果无法等价于某种串行顺序),它就会果断出手,回滚其中一个事务,并抛出序列化失败的错误,告诉应用程序:“抱歉,你们的操作有冲突,其中一个需要重试。”
这种方法避免了锁等待和死锁,极大地提升了并发性能。但它将冲突解决的责任部分转移给了应用层——应用程序必须准备好捕获序列化失败的异常,并进行事务重试。
从MVCC的实现到冲突的处理,MySQL和PostgreSQL的差异背后,是两种截然不同的系统设计哲学。
MySQL的哲学,更偏向于一种命令与控制的模式。通过悲观锁,它为数据世界建立了严格的、可预测的秩序。这种确定性降低了应用层开发的复杂性,但在高并发写入场景下可能牺牲性能。
PostgreSQL的哲学,则是一种信任但验证的模式。它乐观地相信并发操作可以和谐共存,通过多版本和事后裁决来化解冲突。这赋予了系统极高的并发潜力,但要求应用开发者理解并处理好事务重试的逻辑。
这场技术路线的“战争”没有终极的胜利者。它们各自的取舍,塑造了它们在不同应用场景下的优势。选择哪一个,不仅仅是选择一个数据库,更是选择一种与数据世界打交道的方式。这趟深入数据库事务核心的旅程揭示了一个深刻的工程真理:最优秀的设计,往往不是最完美的设计,而是最懂得权衡与妥协的艺术。