对抗知识焦虑,从看懂这条开始
App 下载
会写代码的AI,玩不转普通电子游戏
路径规划工具|电子游戏通关|宝可梦蓝|Gemini 2.5 Pro|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载路径规划工具|电子游戏通关|宝可梦蓝|Gemini 2.5 Pro|大语言模型|人工智能
2025年5月,Gemini 2.5 Pro通关了《宝可梦蓝》——这是AI首次独立完成一款经典RPG游戏。但没人真的为它欢呼:它花了远超人类玩家的时间,全程依赖网格导航、路径规划工具等外挂,还会犯找不存在的“茶”道具、故意让宝可梦全灭这种离谱错误。更讽刺的是,这款连普通小学生都能流畅通关的游戏,出自一个能精准写出复杂代码、解出竞赛级数学题的AI之手。为什么在代码世界如鱼得水的LLM,一到电子游戏里就成了“手残党”?
纽约大学游戏创新实验室主任Julian Togelius把代码比作“极其规矩的游戏”:你有明确的任务,像游戏里的关卡;写完代码能立刻得到反馈——编译成功、通过测试,或者清晰的失败原因。这完全符合游戏设计师Raph Koster的理论:游戏的乐趣来自“边玩边学”,而代码就是被设计得最完美的“学习型游戏”。
但电子游戏是另一回事。它没有统一的规则框架,从《超级马里奥》的平台跳跃到《文明》的战略规划,每款游戏的状态空间、反馈逻辑都天差地别。LLM的训练数据里全是文本,它能理解“把变量a赋值给b”,却没法直观感知“马里奥跳到砖块上会弹起”这种空间物理规则;它能根据代码报错修正错误,却没法从“角色掉坑死亡”里快速总结出“要避开黑洞区域”的经验——因为这种反馈没有统一的“错误提示语”。
更关键的是,LLM没有“世界模型”。它不会像人类一样,在脑子里构建出游戏世界的空间地图、物理规律和因果链条。它的决策更像是“根据文本概率猜下一步该说什么”,而非“基于对世界的理解做出选择”。
空间推理能力的缺失,是LLM玩不转游戏的核心硬伤。所谓空间推理,就是理解物体的位置、距离、遮挡关系,以及它们在动态环境中的变化——比如判断“从当前位置到宝箱需要绕开哪堵墙”“敌人的攻击范围是否覆盖了我站的地方”。
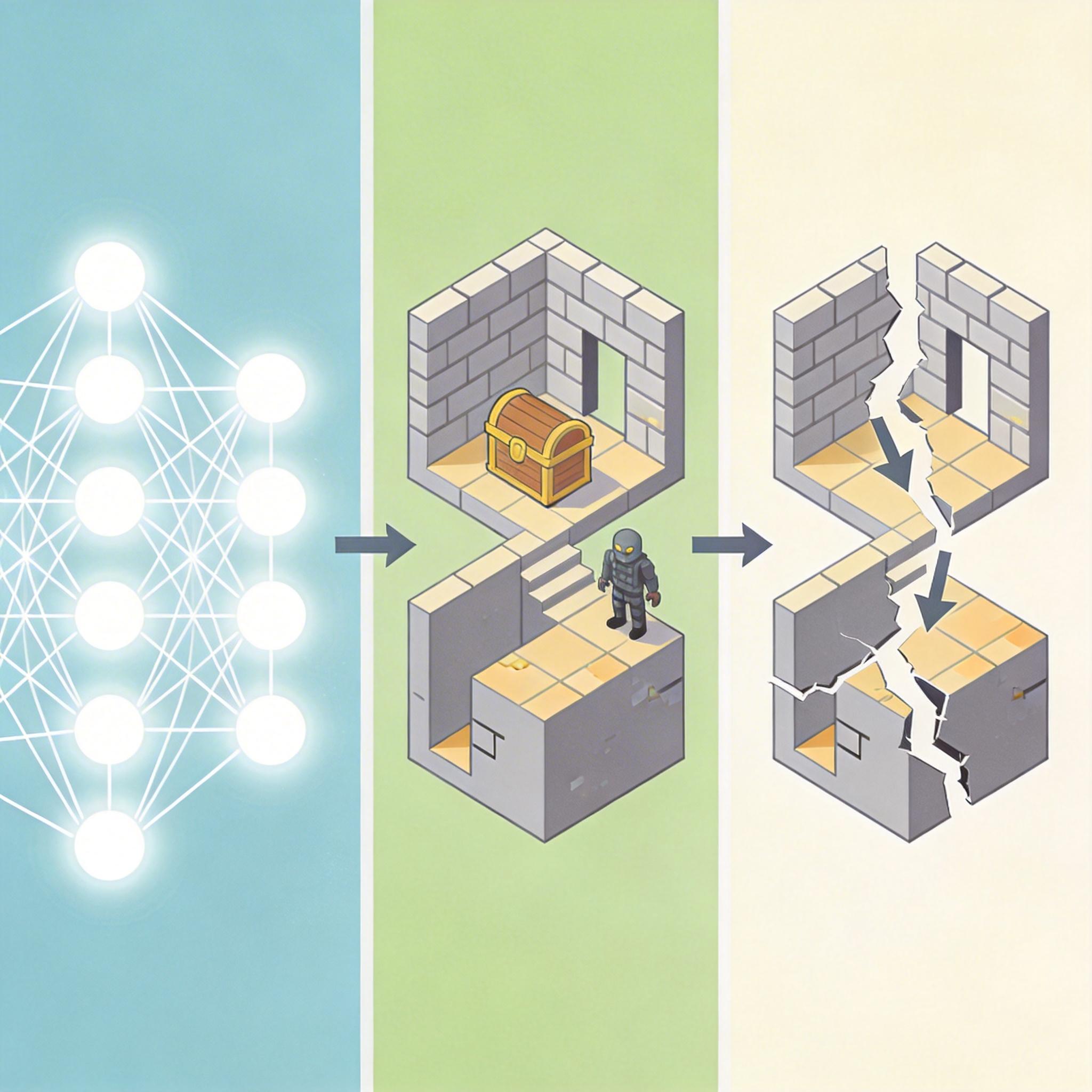
人类的空间推理能力刻在基因里,我们从小玩积木、走迷宫,大脑会自动构建空间认知模型。但LLM的训练数据几乎没有“空间经验”:它能读懂“猫在桌子下面”这句话,却没法想象出猫和桌子的立体位置关系;它能生成描述3D场景的文本,却没法像人类一样,仅凭一张截图就规划出合理的移动路径。
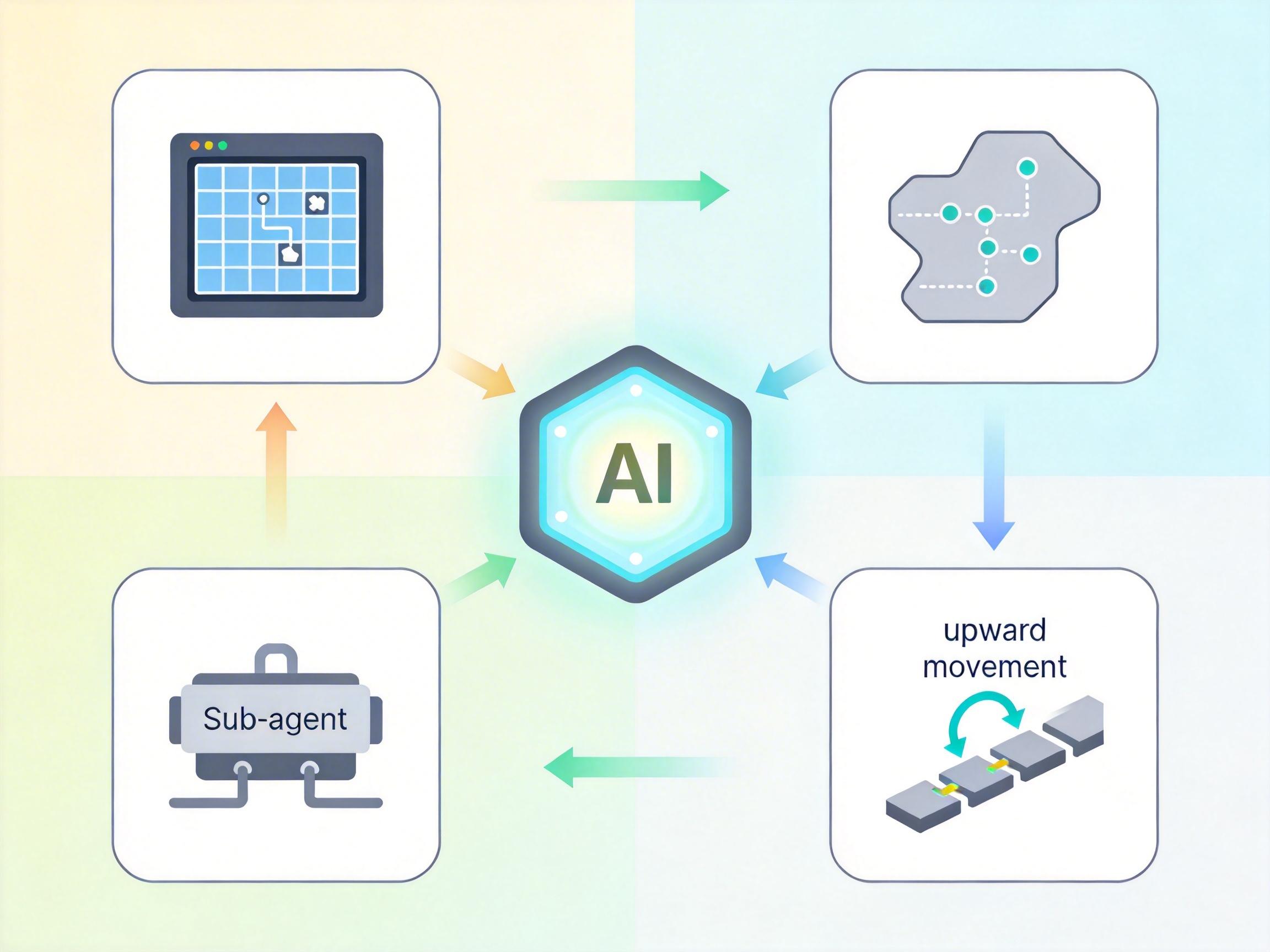
为了弥补这个缺陷,Gemini 2.5 Pro通关《宝可梦蓝》时,不得不依赖外部工具:用网格把屏幕分割成一个个坐标点,用文本化地图记录探索过的区域,甚至专门调用“岩石谜题策略子代理”来处理需要空间推理的难题。但即便如此,它还是会在复杂场景中“恐慌”——比如被岩壁卡住时,忘记调用导航工具,只会反复输出“向上走”的无效指令。
纽约大学的实验更直白:让LLM和简单的搜索算法比拼玩自定义游戏,LLM的表现全面落后。它甚至连“推箱子”这种基础空间游戏都玩不明白,因为它没法理解“推动箱子后,箱子的位置会如何影响后续路径”。
LLM玩不转游戏,不是它一个人的问题——整个AI领域都没搞定“通用游戏AI”。
从2014年到2021年,通用游戏AI竞赛(GVGAI)连续办了7年。每届竞赛都会发明10款全新的游戏,考验AI快速适应新规则的能力。但竞赛办了7年,研究者们发现:AI只会在熟悉的游戏类型里进步,换个全新的游戏机制,它就会打回原形。比如擅长玩平台跳跃游戏的AI,遇到回合制策略游戏会完全不知所措;能解出复杂谜题的AI,面对需要实时反应的射击游戏会手忙脚乱。
传统游戏AI比如AlphaZero,能在围棋、国际象棋里击败人类,但它是“专用AI”——每种游戏都要重新训练,而且只适用于规则、状态空间相似的游戏。而电子游戏的多样性,远超棋类的范畴:从2D到3D,从回合制到实时,从单人到多人,每款游戏的“输入输出接口”都不一样。LLM虽然是“通用模型”,但它的通用性只限于文本领域,面对游戏的多模态输入(视觉、动作、声音)和动态交互,它的“通用能力”毫无用武之地。
现在的AI游戏解决方案,本质上都是“拆东墙补西墙”:用感知模块把游戏画面转成文本,用记忆模块记录游戏状态,用推理模块生成操作指令。但这些模块的组合,只是把游戏问题“翻译”成LLM能处理的文本问题,并没有真正让LLM理解游戏的核心机制。
我们总以为,AI能搞定复杂的代码、数学题,就一定能玩转电子游戏——毕竟在我们的直觉里,游戏比代码“简单”。但电子游戏恰恰戳中了当前AI的命门:它需要的不是对文本的理解,而是对世界的感知;不是静态的推理,而是动态的适应;不是基于概率的猜测,而是基于经验的判断。
能说会算的AI,还没学会“理解”世界。
电子游戏就像一面镜子,照出了LLM的“伪智能”:它能模仿人类的语言和逻辑,却没法拥有人类的感知和体验。或许当AI真能像人类一样,仅凭直觉就通关一款从未玩过的游戏时,我们才敢说,它离真正的通用智能更近了一步。