对抗知识焦虑,从看懂这条开始
App 下载
AI写作“人性化”工具诞生:维基百科的猎手规则,反成AI的隐身指南?
编辑志愿者|AI写作特征清单|AI清理项目|维基百科|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载编辑志愿者|AI写作特征清单|AI清理项目|维基百科|AIGC|人工智能
在维基百科(Wikipedia)的庞大知识宇宙中,一群自称“AI清理项目”(WikiProject AI Cleanup)的编辑志愿者,正像数字时代的侦探一样,孜孜不倦地追寻着人工智能(AI)留下的蛛丝马迹。自2023年底以来,他们 meticulously 编纂了一份包含24种语言和格式模式的“AI写作特征清单”,从“标志着一个关键时刻”(marking a pivotal moment)这类浮夸的修辞,到以“-ing”结尾的分析性短语,这些都成了他们识别和标记AI生成文章的利器。他们的目标纯粹而坚定:捍卫人类知识的真实性。然而,他们未曾料到,这份倾注心血的“猎手指南”,竟在朝夕之间,被巧妙地转化为AI的“隐身指南”。
这则充满讽刺意味的故事,始于一个名为“Humanizer”的插件。开发者Chen发现,维基百科编辑们总结的这份清单,与其说是一份检测规则,不如说是一份完美的“规避手册”。他将这24条规则直接写入一个提示词插件,喂给AI大模型Claude。其指令简单粗暴:“不要这样做。”
结果出人意料地有效。经过“Humanizer”处理后,Claude的输出风格变得不再那么精准、刻板,反而增添了几分人类写作中常见的随意与口语化。例如,它会主动将“加泰罗尼亚统计研究所于1989年正式成立,标志着西班牙地区统计发展的关键时刻”这种典型的AI腔调,修改为“加泰罗尼亚统计研究所成立于1989年,负责收集和发布地区统计数据”这样平实无华的表述。这份本用于鉴别AI的规则集,竟讽刺地成为了帮助AI“伪装”成人类的强大工具。这一事件迅速在技术社区发酵,也正式揭开了一场围绕AI写作检测与规避的、愈演愈烈的技术军备竞赛的序幕。
这场博弈的核心,在于AI写作与检测技术的基本原理。大型语言模型(LLM)本质上是“模式匹配大师”,它们通过学习海量文本数据,以统计概率的方式生成最“合理”的下一个词。因此,其输出往往在词汇选择、句式结构上呈现出一种可预测的“平滑感”和“套路化”。
AI检测工具,如被康奈尔大学研究评为最精准的Copyleaks以及在学术界广泛使用的Turnitin,正是利用了这一点。它们通过分析文本的“困惑度”(Perplexity,即文本的可预测性)和语言模式来识别AI。一个文本如果逻辑过于完美、用词过于规范,反而会触发警报。
然而,道高一尺,魔高一丈。随着“Humanizer”的出现,一个庞大的“AI文本人性化”产业应运而生。诸如BypassGPT、Humbot AI等工具层出不穷,它们的核心功能就是通过以下方式,打破AI写作的固有模式,从而绕过检测:
这场攻防战的本质,是算法与算法的对抗。检测工具在升级,规避工具也在迭代,使得人与机器在文本世界中的界限变得前所未有的模糊。
在这场技术博弈中,最先受到冲击的是信息真实性与社会信任机制。当检测工具不再可靠,一系列严重的后果开始显现。
首先,是学术与教育领域的混乱。 AI检测工具的“误报”成为了悬在许多学生头上的达摩克利斯之剑。斯坦福大学的一项研究发现,对于非英语母语者(ESL)的写作,检测器的误报率可能极高。他们的写作因为词汇和句式相对简单、规范,反而更容易被机器误判为AI生成。一名学生仅仅因为使用了Grammarly这样的语法润色工具,就被指控学术不端,不得不耗费数月时间自证清白。这种“宁可错杀,不可放过”的机械化检测,正在侵蚀着教育的公平与信任。
其次,是虚假信息的泛滥成灾。 AI极大地降低了制造谣言的成本。公安部近期公布的案例显示,有不法团伙利用AI批量“洗稿”或直接生成虚假新闻,炮制出“西安地下涌出热水引发地震”等耸人听闻的谣言,甚至有软件“一天能生成19万篇文章”。这些AI生成的谣言往往夹杂着“据报道”“有关部门正在调查”等以假乱真的表述,再配上AI生成的图片或视频,迷惑性极强,严重扰乱了公共秩序,透支了社会信任。

面对这场信任危机,单纯依赖检测技术已然行不通。一个更具建设性的共识正在形成:我们需要技术与规则双管齐下,构建一个更加透明、可追溯的AI内容生态。
技术层面,数字水印(Digital Watermark)被寄予厚望。 以谷歌DeepMind的**SynthID**技术为代表,它在AI模型生成内容时,就在像素或文字的底层嵌入肉眼不可见但机器可读的标记。这种“出身证明”比后期检测更难被篡改和移除,为内容溯源提供了有力的技术支撑。尽管目前水印技术仍面临被攻击和破解的风险,但它代表了从“被动检测”向“主动标识”的思路转变。
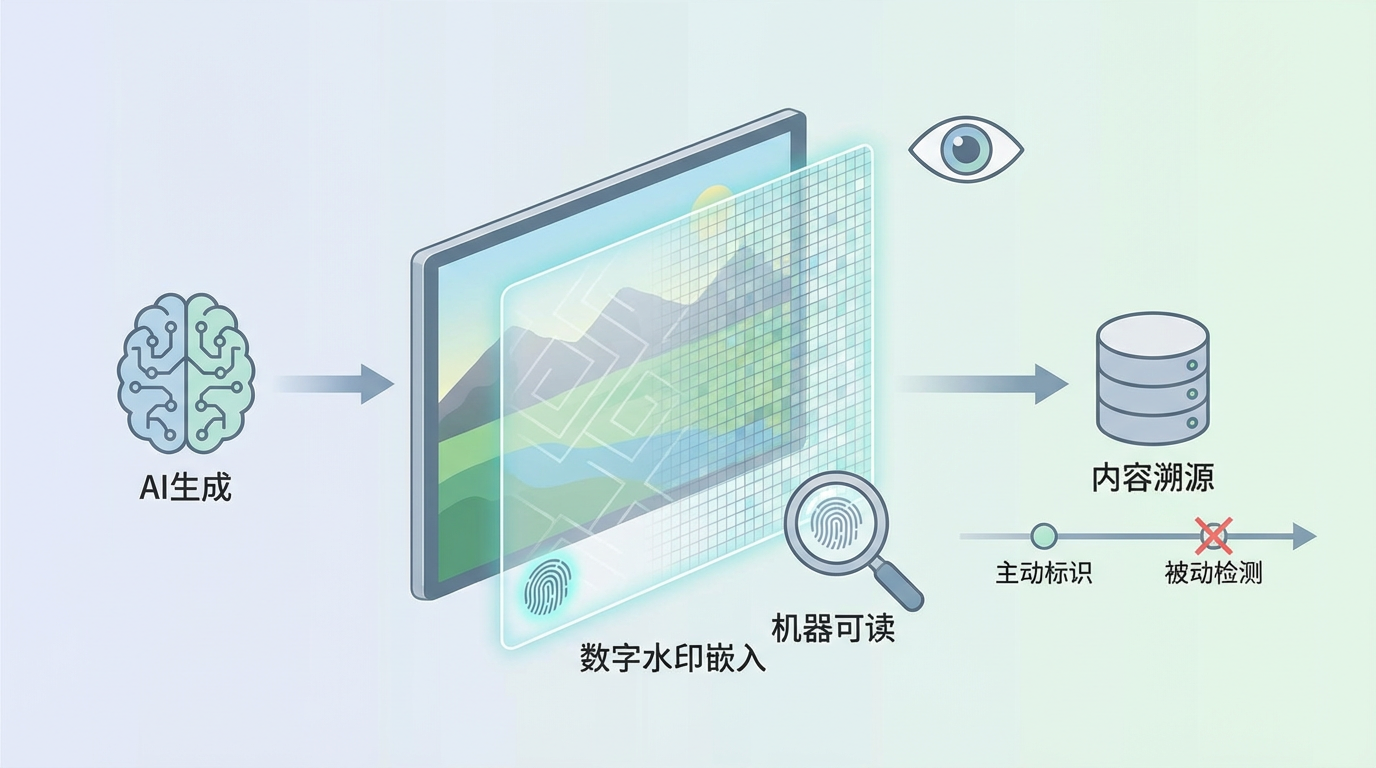
规则层面,全球性的监管框架正在加速构建。 中国、欧盟等国家和地区相继出台法规,要求对AI生成内容进行显著标识。例如,中国于2025年9月1日正式实施的《人工智能生成合成内容标识办法》,明确要求服务提供者通过显式和隐式两种方式为AI内容打上标签。这不仅保障了公众的知情权,也为责任追究提供了法律依据。平台方也开始行动,在用户发布内容时提供“AI生成”声明选项,并在相关内容下添加提示。
“Humanizer”的诞生,如同一面棱镜,折射出AI时代我们所面临的深刻困境:当机器的模仿能力超越了我们的分辨能力,我们该如何维系建立在“真实”之上的社会契约?
这场关于AI写作的博弈远未结束。它警示我们,技术的答案最终可能不在于创造出更完美的“矛”或“盾”,而在于建立一个全新的游戏规则。未来,我们评判信息价值的标准,或许将不再仅仅是“它看起来是否真实”,而是“我们能否清晰地知道它的来源”。通过强制标识、数字水印和法律监管,我们正在努力为这个日益模糊的数字世界,重新划定一条关于真实的基准线。这不仅是对技术的规制,更是对人类社会信任基石的捍卫与重塑。