对抗知识焦虑,从看懂这条开始
App 下载
卡了百年的物理难题,AI几秒就解了
洛斯阿拉莫斯国家实验室|新墨西哥大学|高维配置积分|张量网络|THOR框架|大语言模型|凝聚态物理|数理基础|人工智能
对抗知识焦虑,从看懂这条开始
App 下载洛斯阿拉莫斯国家实验室|新墨西哥大学|高维配置积分|张量网络|THOR框架|大语言模型|凝聚态物理|数理基础|人工智能
想象一下:你要算清一块铜里所有原子的相互作用——每个原子的位置、受力、振动都要考虑,最后得出它在零下200度到室温的硬度变化。放在昨天,这需要一台超级计算机连跑三周。今天,新墨西哥大学和洛斯阿拉莫斯国家实验室的团队,用一个叫THOR的AI框架,把时间压缩到了几秒。
这不是普通的加速。他们解决的是统计物理里卡了一百年的死结:高维配置积分——简单说就是把一堆原子的所有可能状态都算清楚的数学题。过去大家都觉得这题根本没法直接解,直到THOR掏出了张量网络和机器学习的组合拳。
为什么这招能破局?
先搞懂为什么这题难。一块100个原子的材料,每个原子有3个空间坐标,对应的配置积分就是300维的——相当于在300层的迷宫里找所有可能的路径。这就是「维度诅咒」:每多一个维度,计算量就翻好几倍,到300维时,哪怕用最快的超算,算完的时间都比宇宙年龄还长。
你可以把传统方法想象成用渔网捞鱼:为了捞到所有原子的状态,得把整个300维的池塘都铺满渔网,网眼还得细到能接住单个原子。这渔网的大小是100的300次方——数字大到没有意义。过去科学家只能退而求其次,用分子动力学或者蒙特卡洛模拟「抽样估算」,就像在池塘里随机捞几网,靠样本猜整体,不仅慢,还总有误差。
THOR的破局点,在于它根本没打算铺整张渔网。
它用的是「张量列车分解」——把300维的巨型数据块,拆成一串低维的小张量,像把一条大铁链拆成一个个小铁环。每个小铁环只记录相邻原子的相互作用,不用管整个体系的所有可能。这样一来,计算量从指数级直接降到了线性级,相当于把渔网换成了一根钓鱼线,精准勾住关键的原子相互作用。
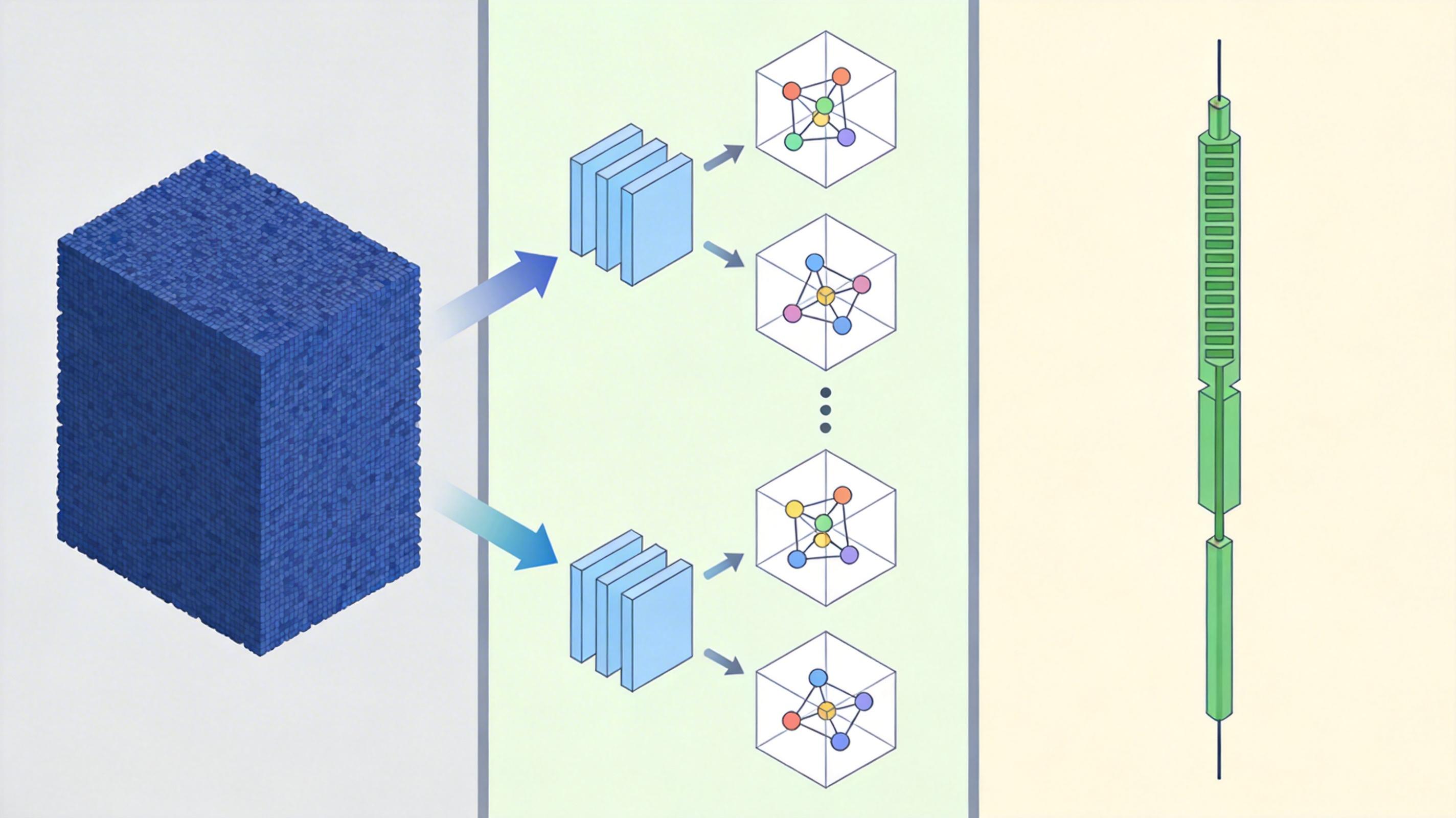
光靠张量网络还不够。THOR还加了机器学习势能模型——相当于给钓鱼线装了个智能鱼钩,能自动识别原子间的作用力规律。
过去模拟原子相互作用,要么用近似的经验公式,要么用量子力学从头算:经验公式不准,从头算慢到离谱。机器学习势能模型就不一样,它先学一遍量子力学算出来的精准结果,然后记住原子间的受力模式,之后不用再从头算,直接就能给出高精度的作用力数据。
更聪明的是,THOR还会「偷懒」。它能自动识别材料的晶体对称性——比如铜原子是整齐排列的,很多位置的原子状态其实是重复的,THOR会把这些重复的状态合并计算,又省了一大半力气。
他们用铜、高压下的氩和锡的相变做了测试:THOR算出来的内能、压力-温度曲线,和超算跑了三周的分子动力学模拟结果几乎一模一样,但速度快了400倍。放在单个GPU上,几秒就能出结果——这就像用计算器算出了过去需要超级计算机才能搞定的题。
我认为,这才是真正的突破:它不是在旧方法上加速,而是直接换了一套解题思路——从「抽样估算」变成了「直接计算」,相当于证明了过去大家觉得「不可能」的题,其实是有解的。
现在THOR还只能处理晶体材料,非晶态、多组分合金这些更复杂的体系,还需要进一步优化机器学习势能的泛化能力——毕竟现在它还只能「看懂」学过的原子组合,遇到全新的材料可能还会出错。但这已经足够改变很多事了。
比如新能源材料:过去研发一种新的电池正极材料,得先在计算机里模拟它的热力学稳定性,再做实验,整个流程要几年。现在用THOR,几天就能模拟出上百种候选材料的性能,直接把筛选速度提上去。再比如航空航天的高温合金,过去要模拟它在1000度高温下的蠕变行为,得超算跑一个月,现在几秒就能出结果,能大大缩短研发周期。
更重要的是,它给基础研究打开了新窗口。过去科学家只能靠近似模拟猜材料的相变机制,现在能直接算出精准的配置积分,就能更深入地理解统计力学的底层规律——比如金属为什么会在某个温度下突然变软,极端压力下的气体怎么变成固体。
THOR的出现,其实是一个信号:当AI开始真正理解物理规律,而不是单纯拟合数据时,它能解决的就不是「工程问题」,而是「科学问题」了。
过去我们总说「用AI加速科研」,但很多时候只是让AI帮忙筛选数据、画图表。THOR不一样,它直接用AI重构了物理问题的解题方式——把人类用了一百年都没搞定的数学难题,变成了AI能秒解的常规任务。
算力不是瓶颈,思路才是。这可能就是AI给基础科学带来的最珍贵的礼物:它能帮我们打破那些「理所当然」的不可能,让我们重新去问:「为什么这题一定要这么解?」