对抗知识焦虑,从看懂这条开始
App 下载
靠房价海拔分城市的AI,为啥一遇新数据就失灵
泛化能力|住宅数据|过拟合|决策树模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载泛化能力|住宅数据|过拟合|决策树模型|大语言模型|人工智能
当你站在一套200英尺海拔、每平方英尺售价1700美元的公寓里,要判断它在纽约还是旧金山——你可能会犯难,但AI能瞬间给出答案。2026年初的一项实验显示,用决策树训练的AI,在区分两座城市的住宅数据时,训练集准确率能冲到100%。但当把从未见过的新数据喂给它,错误率直接飙升,连一半都没猜对。这不是AI偷懒,而是它钻进了一个精心布置的陷阱——它记住了训练数据里每一个偶然的细节,却没学会真正的判断逻辑。我们总以为AI能看透数据背后的规律,可这次它连最基本的「举一反三」都没做到。为什么会这样?
决策树(Decision Tree),就是把人类「分情况讨论」的思路写成了代码——它像一棵倒置的树,从根节点开始,每一个分叉都是一次「是/否」的判断,最终在叶子节点给出结论。比如区分两座城市的住宅,它先看海拔:超过240英尺,直接归为旧金山;如果没超过,再看每平方英尺价格:高于1776美元就算纽约。
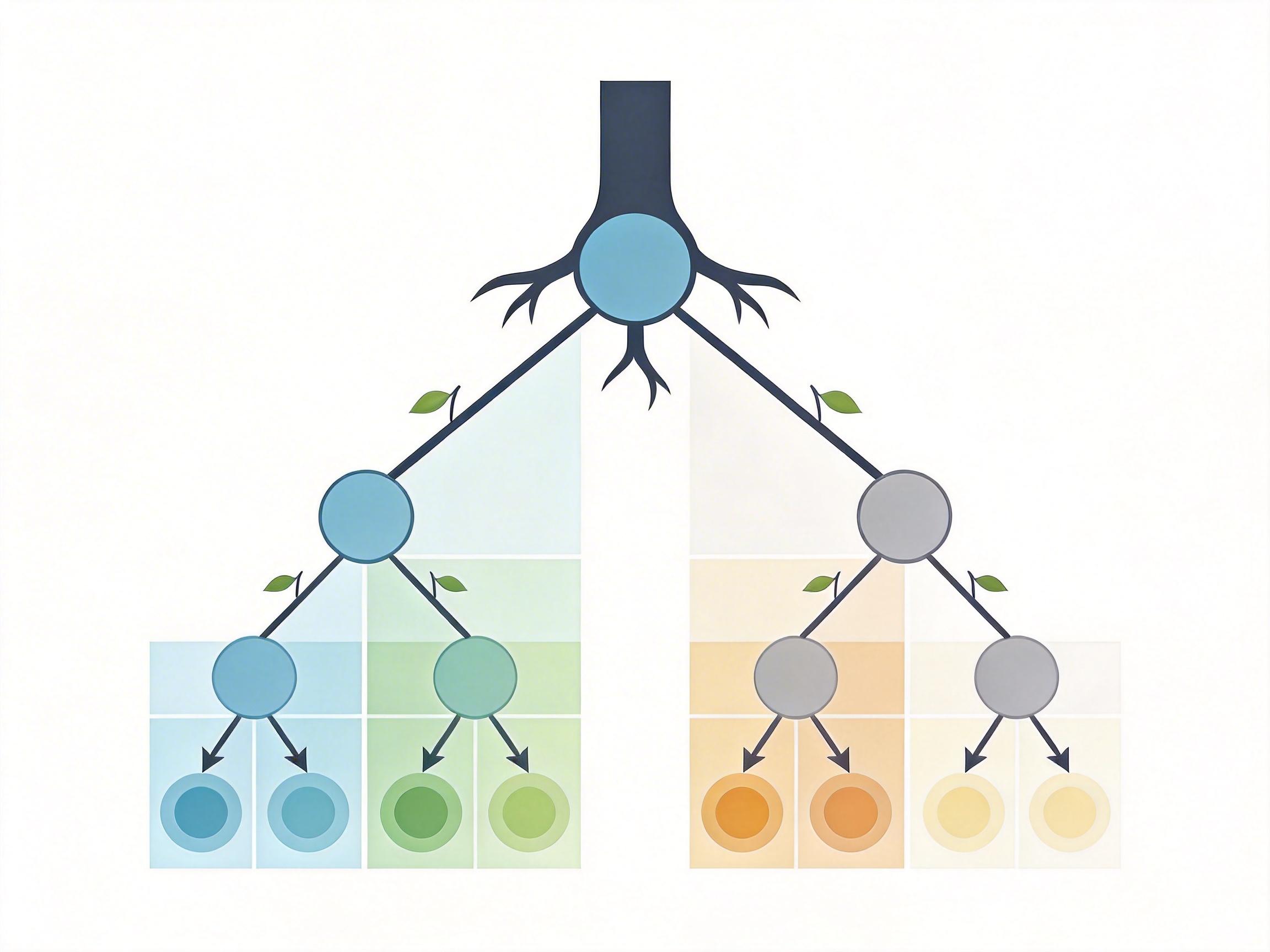
这个过程听起来简单,背后却藏着一套严格的数学逻辑。它会用基尼指数或信息增益计算「最佳分割点」——比如为什么是240英尺而不是239英尺?因为这个数值能让分割后的两组数据最「纯净」,也就是同一城市的住宅尽可能集中在同一分支。它还会用递归的方式不断细分,直到每个叶子节点里的样本都属于同一类别,或者再也分不出更细的组。
这种「白盒模型」最大的优势,就是能把决策路径摊开给人看。你可以顺着树的分叉,一步步找到AI判断的依据,这在医疗、金融这种需要「可解释性」的领域,比那些说不清道不明的黑盒模型靠谱得多。
当决策树的分叉越来越多,叶子节点越来越细,训练数据的准确率就会不断攀升,直到100%——每一个训练样本都能在树里找到完美对应的路径。但这不是因为AI真的懂了两座城市的差异,而是它把训练数据里的噪声和偶然细节都当成了规律。
比如训练数据里刚好有一套旧金山的住宅,海拔230英尺、每平方英尺售价1700美元,决策树就会为它专门开一条分叉:「如果海拔≤240英尺且价格≤1700美元,归为旧金山」。可这套房子只是个偶然的例外,当新数据里出现一套纽约的低海拔低价住宅,AI就会直接错判。这就是过拟合(Overfitting)——模型把训练数据学「死」了,却失去了对新数据的适应能力。
更麻烦的是,决策树天生就有「不稳定」的毛病。训练数据里哪怕只换一个样本,或者某个特征的数值稍有变动,整个树的结构都可能完全不同。比如把之前那套旧金山例外住宅的价格改成1701美元,决策树的分割点可能就会从1776美元变成1700美元,整个判断逻辑都跟着变。这种对数据的极度敏感,让它的泛化能力大打折扣。
要解决过拟合的问题,最直接的办法就是「剪枝」——把那些多余的分叉砍掉。预剪枝是在树生长的时候就设好限制:比如最多只能分5层,每个叶子节点至少要有10个样本;后剪枝则是等树完全长到100%准确率,再把那些对提升新数据准确率没用的分叉剪掉。
但单棵决策树的局限终究难以突破,于是人们想到了「集成学习」——用多棵树来投票。随机森林就是其中最典型的代表:它会随机选一部分训练数据、一部分特征,训练出几十上百棵不同的决策树,最后用投票的方式得出结论。因为每棵树的训练数据和特征都不一样,它们的过拟合方向也不同,投票之后就能互相抵消,大幅提升泛化能力。
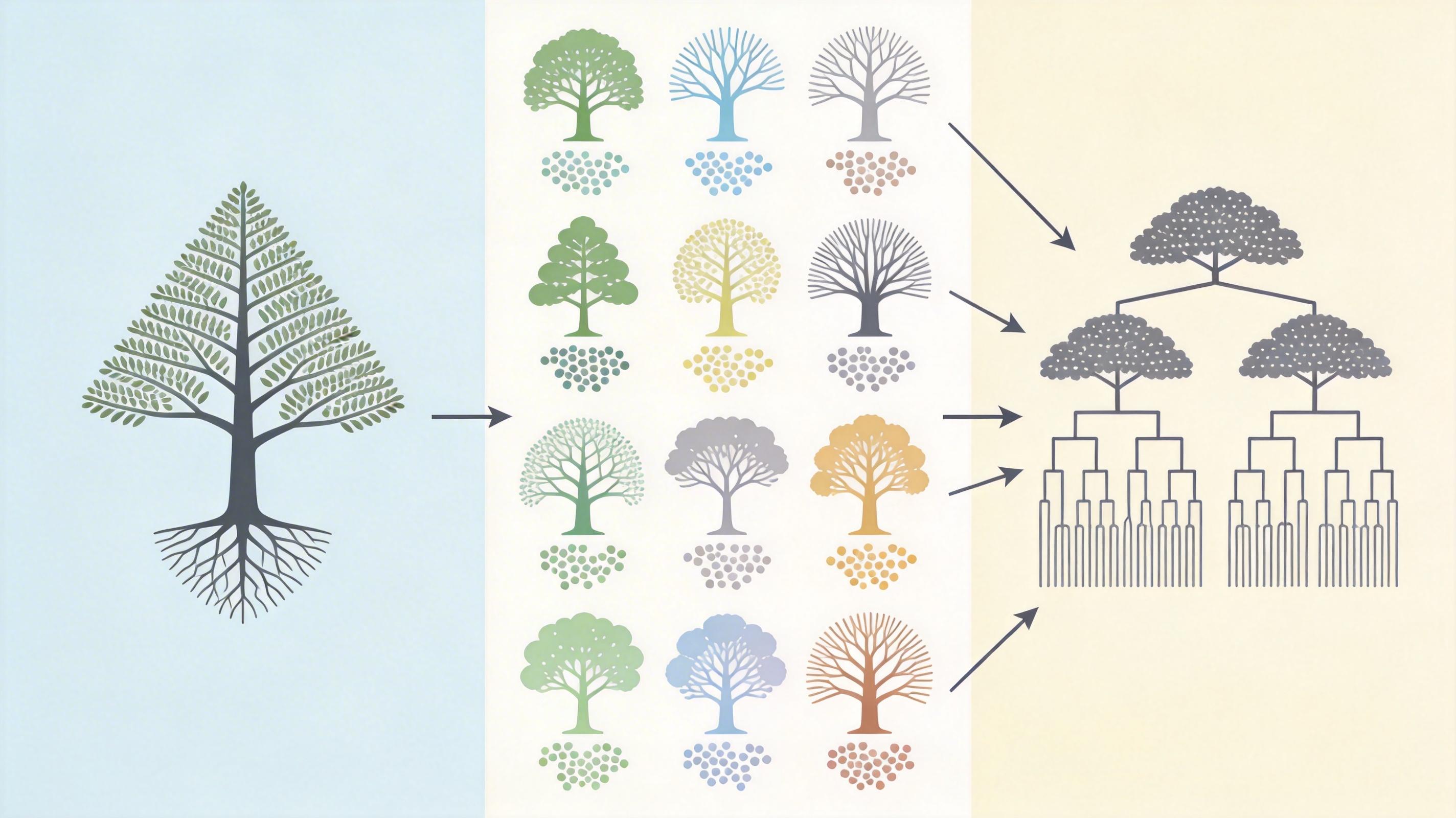
我认为,决策树真正的价值,从来都不是它能做到100%的训练准确率,而是它像一面镜子,照出了机器学习最本质的矛盾:模型越复杂,越容易记住细节,却越难抓住规律;越想贴合现有数据,越容易在新数据面前失灵。这不是技术的缺陷,而是我们对「智能」的误解——真正的智能不是记住所有细节,而是能在混乱中找到不变的逻辑。
当我们为AI的高准确率欢呼时,往往忘了问一句:它真的懂了吗?那个能100%区分纽约和旧金山住宅的决策树,可能连两座城市的地理位置都不知道——它只是记住了一堆数字的组合。
「懂规律,比记细节更重要。」这句话不仅适用于AI,也适用于我们自己。在这个信息爆炸的时代,我们总在追求记住更多的细节,却忘了去提炼那些不变的逻辑。就像那棵过拟合的决策树,看似掌握了所有信息,却在真正的问题面前一败涂地。
真正的智能,从来都不是无所不知,而是能在纷繁复杂的世界里,找到那几条最简单、最本质的规则。