对抗知识焦虑,从看懂这条开始
App 下载
用Zig写函数式代码,比Haskell还快?
类型抽象|手动内存管理|编译时计算|函数式编程|Zig语言|软件工程|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载类型抽象|手动内存管理|编译时计算|函数式编程|Zig语言|软件工程|前沿科技
想象你写了一段优雅的函数式代码——纯函数、不可变数据、类型安全,一切都符合数学美感,但运行起来却像老黄牛拉车:GC停顿突然卡住程序,堆内存的指针迷宫拖慢CPU缓存,明明是2026年的旗舰芯片,却跑不出10年前C语言的性能。这是困了函数式开发者30年的死局:要表达力就得牺牲性能,要性能就得放弃抽象。直到有人用Zig写出了Haskell级别的类型抽象,同时跑出了接近C的速度——这不是魔法,是编译时计算和手动内存管理的协奏。
你可以把Zig的comptime(编译时执行)想象成一个提前上班的程序员:在代码真正运行前,它就把所有复杂的类型检查、抽象展开、代码生成工作做完了。比如你要实现Haskell里的Maybe类型,不用依赖运行时的类型擦除或装箱,Zig会在编译时直接生成针对具体类型的二进制代码——没有多余的函数调用,没有隐藏的内存分配,就像你手动写的底层代码一样高效。
这和Haskell的类型系统有本质区别:Haskell的类型推导和抽象是在运行时或虚拟机层面实现的,而Zig的comptime是把抽象直接“焊死”在机器码里。比如你用comptime实现一个类型类,编译器会在编译时检查所有实现是否符合规范,生成对应的函数调用表,完全没有运行时的字典查找开销。
但comptime不是万能的魔法。它不能访问运行时数据,不能做动态IO,甚至不能修改生成类型的方法——所有行为都必须是可预测的。这种限制反而成了优势:你不用担心隐藏的控制流,也不会遇到莫名其妙的性能损耗,一切都在编译阶段透明可见。
传统函数式语言的性能瓶颈,一半来自抽象层的开销,另一半来自垃圾回收。GC就像一个不定期来打扫的清洁工:平时让你不用操心垃圾,但打扫时会把所有人都赶出去,暂停程序运行。而现代CPU和内存的性能差距已经拉到了10000倍,GC的停顿和堆内存的指针迷宫,会让CPU缓存彻底失效——就像你在一个堆满杂物的仓库里找东西,每走一步都要绕路。
Zig的解决办法是:把垃圾回收的权力还给你,但给你一套趁手的工具。比如Arena分配器,你可以把所有生命周期相同的对象放在同一块内存里,用完直接整块释放——没有碎片,没有多次系统调用,速度比GC快一个数量级。你还可以自定义分配策略:给临时数据用固定缓冲区,给全局对象用页分配器,给高频对象用内存池,完全贴合你的程序需求。
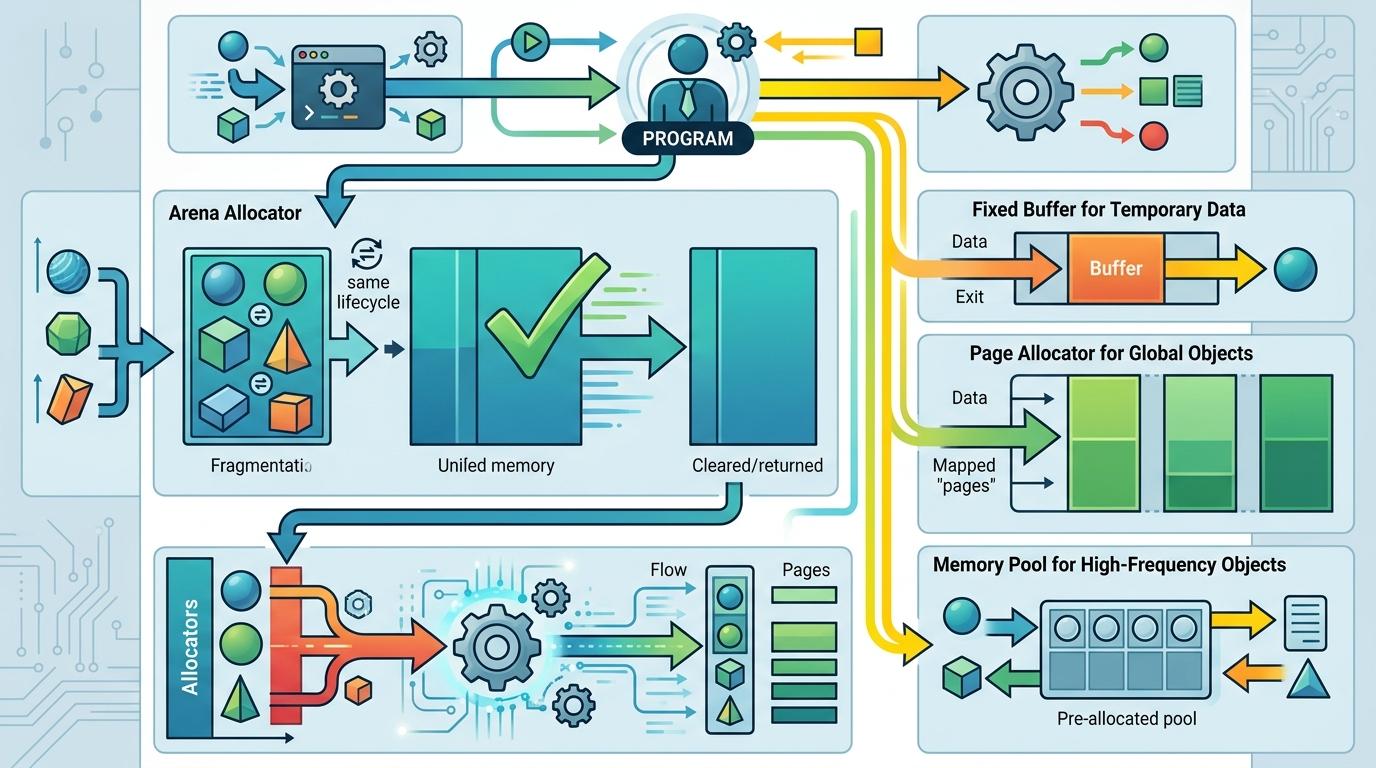
当然,手动管理内存意味着你要对每一块内存的生命周期负责。但Zig会帮你做好安全检查:Debug模式下会检测重复释放、使用后释放等问题,Release模式下可以关闭检查换取极致性能。这种“信任但验证”的设计,比Rust的所有权系统更灵活,也比C语言更安全。
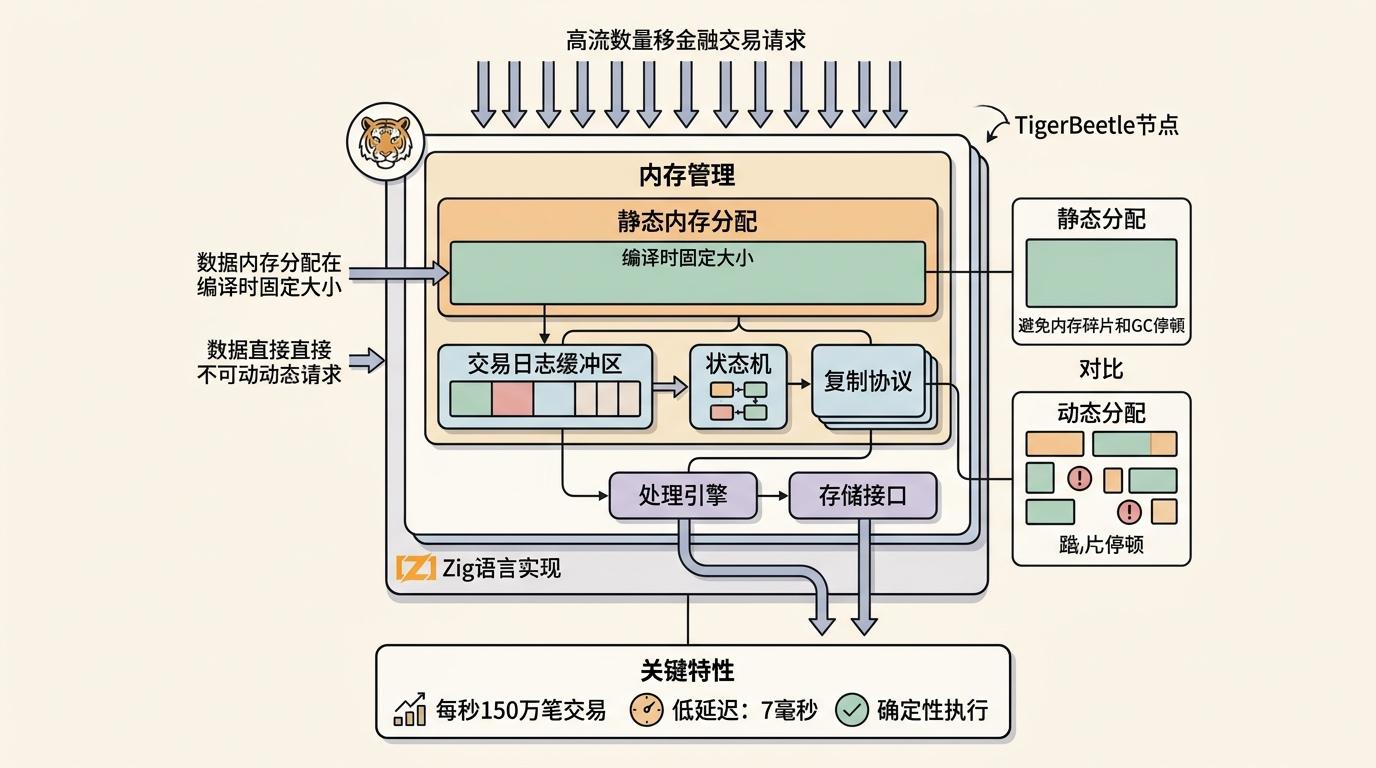
TigerBeetle数据库是Zig的最佳代言:这个专为金融交易设计的分布式数据库,用Zig实现了每秒150万笔交易的吞吐量,延迟控制在7毫秒以内。它的核心设计是“静态内存分配”——所有内存都在程序启动时一次性分配,运行时不做任何动态分配,彻底避免了内存碎片和GC停顿。
另一个案例是Bun,这个用Zig重写的Node.js替代品,启动速度比Node.js快4倍,内存占用只有1/3。它用Arena分配器管理模块内存,用comptime生成高效的JavaScript绑定代码,把函数式的模块化抽象和底层的性能控制完美结合。
但Zig也有自己的问题:生态还不够成熟,很多常用库还在开发中;comptime的学习曲线较陡,新手需要时间理解编译时计算的思维方式;多线程和并发支持还在完善中,高并发场景下的编程体验不如Rust。
30年来,函数式编程一直在“优雅”和“性能”之间摇摆:要么为了优雅牺牲性能,要么为了性能放弃优雅。Zig的出现,第一次让我们看到了第三条路:用编译时计算把抽象开销消除在运行前,用手动内存管理把性能控制权还给开发者。
这不是对函数式编程的否定,而是一种进化——函数式的抽象依然存在,但它不再是性能的负担,而是变成了高效代码的生成器。抽象不一定要牺牲性能,关键是在哪里买单。
Zig还不是完美的,但它给了我们一个新的视角:系统编程不需要在“底层控制”和“高层抽象”之间二选一。未来的编程语言,或许都会朝着这个方向走——让开发者既能写出优雅的代码,又能掌控每一个字节的性能。