对抗知识焦虑,从看懂这条开始
App 下载
内存卡顿的终极解法:让数据自己“抢跑道”
C++优化|内存卡顿|DRAM刷新|尾延迟|Tailslayer库|软件工程|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载C++优化|内存卡顿|DRAM刷新|尾延迟|Tailslayer库|软件工程|前沿科技
你有没有过这种体验:手机明明只剩几个后台,刷信息流却突然卡成PPT;游戏团战正激烈,画面突然定格半秒——这些不是硬件性能不够,更可能是被“尾延迟”击中了。
所谓尾延迟,就是系统里那1%甚至0.1%的极端慢请求,它们像隐形的路障,悄悄拖垮整体体验。而在所有引发尾延迟的元凶里,DRAM内存的“刷新卡顿”最隐蔽:为了保住数据,内存每隔几十毫秒就要暂停服务“补电”,偏偏这几十毫秒,刚好可能撞上你的关键操作。
现在,一群工程师用一个叫Tailslayer的C++库,把这种随机卡顿的概率降到了近乎零。他们是怎么让内存学会“避峰出行”的?
要懂Tailslayer的魔法,得先搞懂DRAM内存的“天生缺陷”:它的每个存储单元都是个微型电容,电荷会像水杯里的水一样慢慢漏光——所以必须每隔64毫秒就集体“刷新”一次:把所有电容里的数据读到放大器,再重新写回去补电。
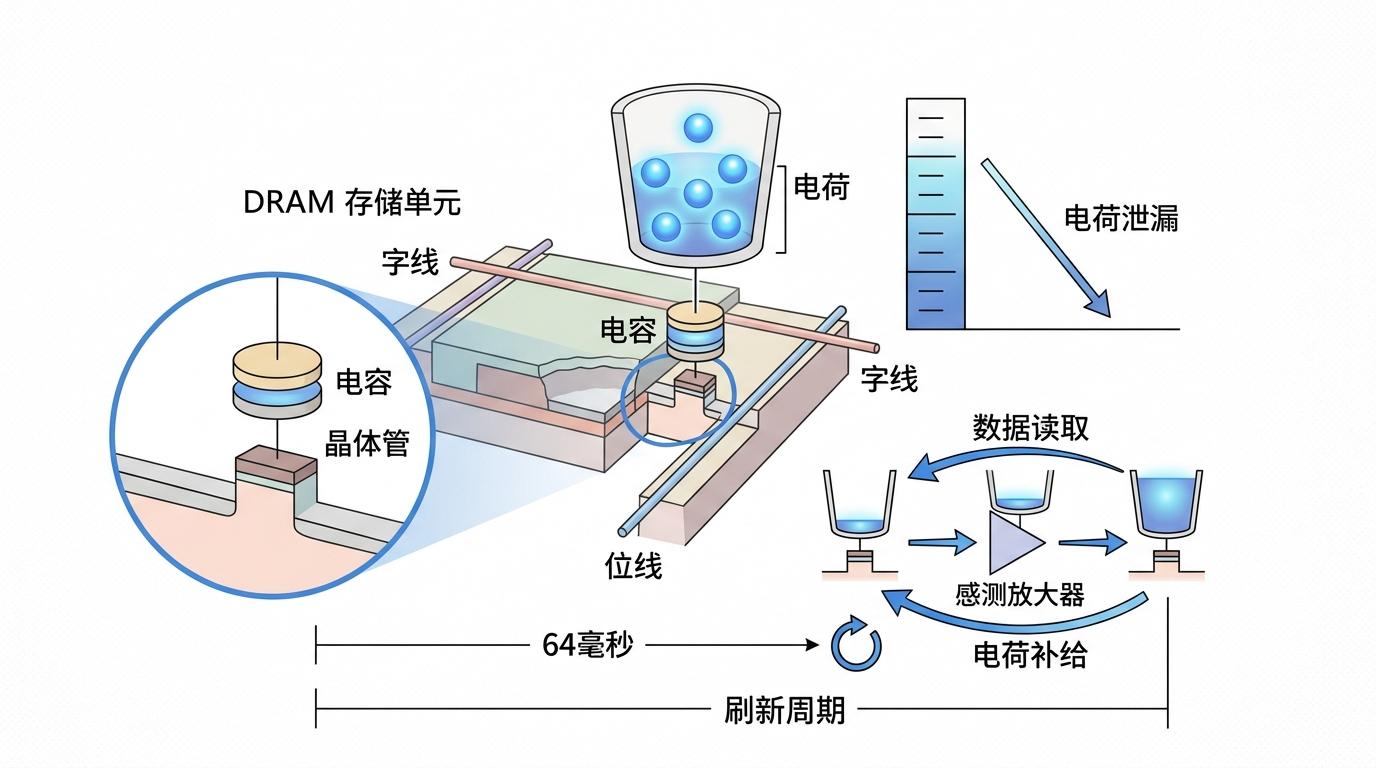
你可以把这个过程想象成写字楼的消防演习:整栋楼的人都要停下工作去楼道集合,不管你是不是正在签百万合同。在刷新的几十微秒里,对应的内存行完全拒绝访问,要是你的数据刚好存在那一行,只能乖乖等着。
更糟的是,多通道内存的刷新是错开的——就像几栋写字楼轮流演习,你躲过了A楼的演习,转头可能撞上B楼的。这种随机的“撞车”,就是尾延迟的核心来源:平均延迟看起来很正常,但总有小概率的极端慢请求突然冒出来。
过去工程师们要么让刷新更“聪明”,比如只漏得多的电容补电;要么给内存加缓存,但都没解决“万一撞上了怎么办”的问题——直到Tailslayer换了个思路:既然躲不开,那就给数据多开几条路。
Tailslayer的核心逻辑简单到像生活常识:既然单条路可能堵车,那就同时走几条路,谁先到用谁的。
它会把同一份数据复制到多个独立的DRAM通道里——就像你把一份文件同时存在U盘、硬盘和云盘里。关键在于,这些通道的刷新时间是完全错开的,就像三条永远不会同时堵车的平行高速。当你需要读数据时,Tailslayer会同时向所有通道发请求,哪个通道没在刷新、能最快返回,就用哪个通道的数据,其他请求直接取消。
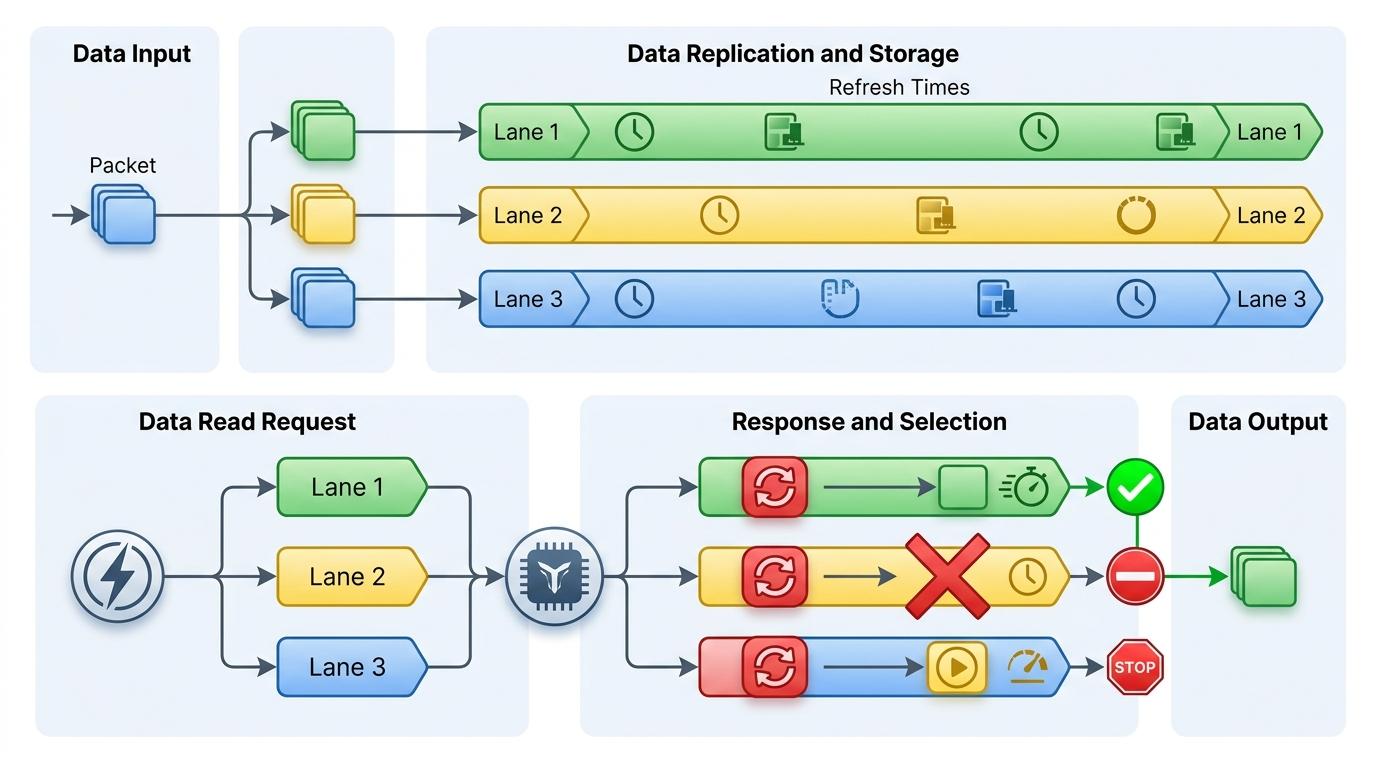
这种“投机读取”的思路其实不算新鲜,Google早在2013年就提出用冗余请求解决分布式系统的尾延迟,但Tailslayer把它搬到了硬件内存层面,还解决了两个关键问题:
首先是跨平台适配。它利用AMD、Intel和Graviton处理器里没公开的“通道扰码偏移”,能自动在不同平台的内存通道间复制数据,不用用户操心硬件细节。
其次是资源控制。它会把每个通道的读取任务绑定到独立的CPU核心,用自旋等待代替系统调用,把调度延迟降到最低。你只需要告诉它什么时候读、读到数据后做什么,剩下的它自动搞定。
测试数据显示,在双通道环境下,Tailslayer能把刷新引发的P99尾延迟降低数倍——相当于把写字楼演习导致的合同延误概率,从1%降到了0.1%以下。
当然,Tailslayer也不是没有代价:复制数据意味着要占用更多内存空间,就像你为了不堵车同时开三辆车,得付三倍的油费。目前它只支持双通道,N通道的完整版本还在测试阶段,而且只适合读多写少的场景——毕竟写数据时要同时更新所有副本,反而会增加延迟。
但它的价值恰恰在于“精准打击”:那些对尾延迟零容忍的场景,比如高频交易系统、实时数据库、AI推理平台,哪怕只降低0.1%的极端延迟,都意味着真金白银的收益或用户体验的质变。Global Payments用类似的投机读取策略,把信用卡授权系统的P99延迟降低了30%,就是最好的例子。
更重要的是,它给了工程师一个新的思路:与其和硬件的天生缺陷死磕,不如换个角度利用它的特性。DRAM的多通道刷新本来是个麻烦,Tailslayer却把它变成了对抗尾延迟的武器——就像你利用写字楼的轮流演习时间,在另一栋楼里完成了合同签署。
我们总在追求更快的硬件:更高的主频、更大的带宽,但决定体验的往往不是平均速度,而是那些“慢时刻”。就像通勤路上,你不会记得每天平均花了多久,只会记得那些被堵在半路的绝望瞬间。
Tailslayer的意义,不在于它让内存变快了多少,而在于它让内存的速度变得“可靠”——把随机的卡顿变成可预测的流畅。与其追求极致速度,不如消灭极端延迟,这不仅是内存优化的思路,也是所有系统设计的底层逻辑:稳定的流畅,永远比爆发的速度更重要。
毕竟,没人会为了偶尔的极速体验,忍受随时可能出现的卡顿。