
4 天前
4 天前
当你对着日语的宾语前置一头雾水,或是为德语的框形动词挠头时,或许不会想到,这些看似天差地别的语言,其实共享着一套隐秘的底层逻辑。2026年4月,一项覆盖1700余种语言的研究给出了实锤:经过更严谨的统计检验,约三分之一长期争议的“语言学普遍性”得到了强证据支持。这不是语言学家的文字游戏——它指向一个更震撼的结论:人类的认知模式与交流需求,正在冥冥中塑造着所有语言的演化方向。我们为何说话?这个问题的答案,或许就藏在这些跨越地域与族群的语法规律里。
“语言学普遍性”是语言学家用来描述全球语言共性的核心概念——简单说,就是那些不管你说汉语、斯瓦希里语还是因纽特语,都可能存在的语法特征。它分为三类:绝对普遍规律是所有语言都绕不开的铁则,比如任何语言都有名词和动词;限制性普遍规律是“有A必有B”的条件关联,比如“如果形容词在名词前,那指示词大概率也在名词前”;统计性普遍规律则是多数语言遵循但允许例外的倾向,比如大部分宾语前置的语言会搭配后置词。
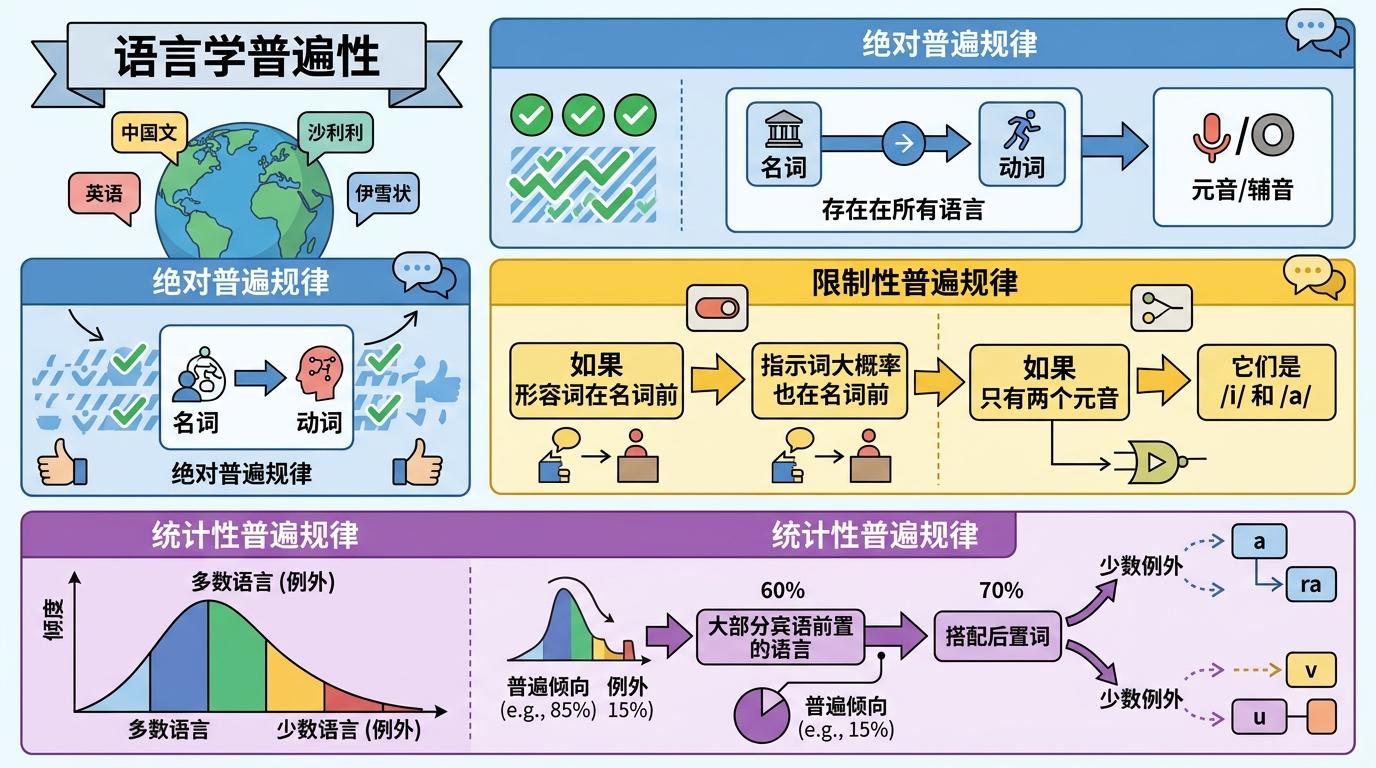
早在上世纪60年代,语言学家格林伯格就基于30余种语言提出了数十条这类规律,但受限于样本规模和统计方法,很多结论一直存在争议。过去的研究为了避开亲缘或地域语言的干扰,会刻意挑选远隔千里的语言样本,却反而削弱了统计效力,也没法追踪语言的演化轨迹。直到这次研究用上了更先进的方法,才终于为三分之一的经典猜想补上了关键证据。
让这项研究突破瓶颈的,是一种叫“贝叶斯空间-系统发育分析”的方法——它能同时兼顾语言的“血缘关系”和地理影响,彻底解决了传统研究的统计偏差问题。简单来说,它像给语言画了一张带时间轴的“家族树”,再叠加地理分布图层,以此区分“因为同源而相似”和“因为独立演化而趋同”的语法特征。
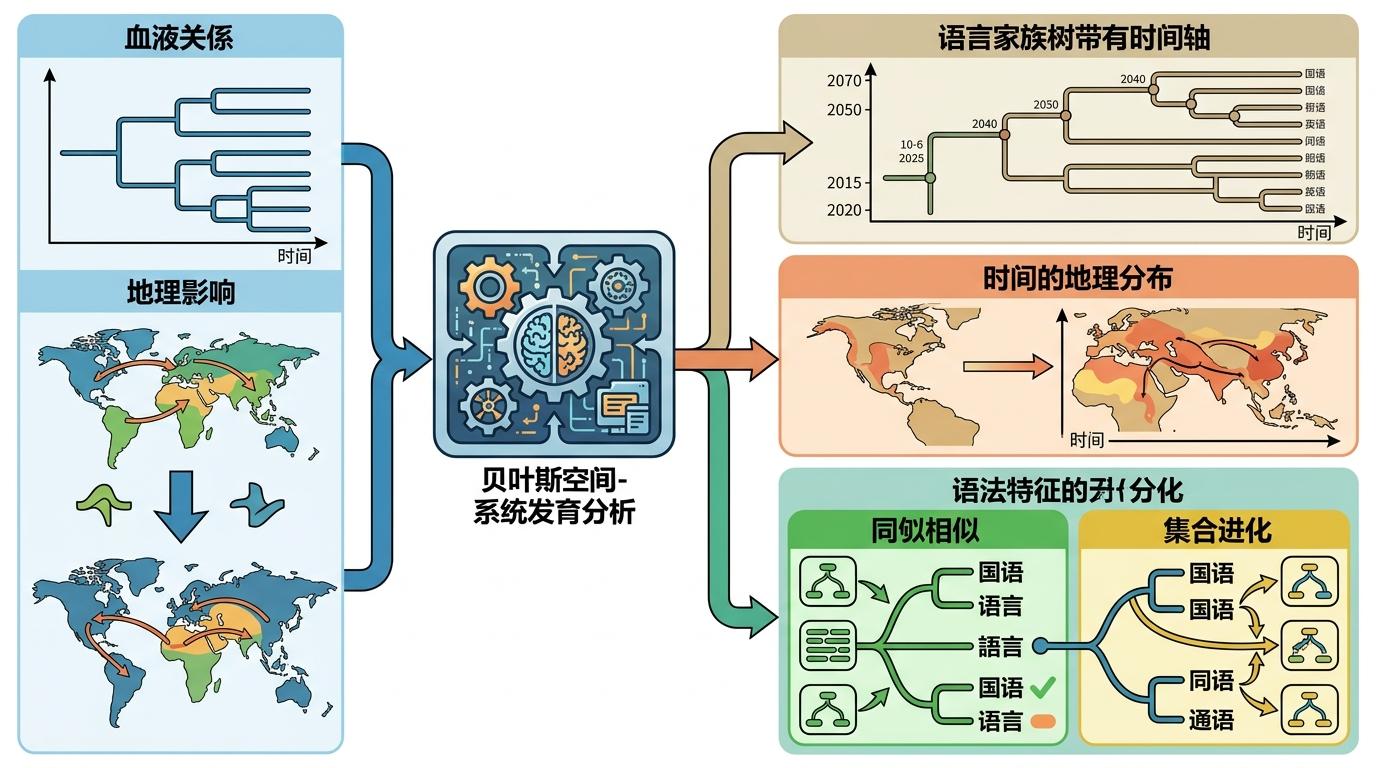
举个例子,日语和土耳其语毫无亲缘关系,也相隔万里,但两者都是宾语前置且用后置词的语言。传统方法可能会把这种相似归为巧合,而新方法能通过建模确认:这是它们在演化中各自受到认知压力,独立走向了同一种语法解决方案。研究团队用这套方法检验了191条普遍规律,最终筛选出了统计显著的那些——这不是靠“选样本凑结论”,而是让数据自己说话。
当然,这套方法也有局限:它依赖已有的语言谱系和语法数据库,对于那些几乎没留下记录的濒危语言,依然难以纳入分析;而且它只能揭示“是什么”,没法完全解释“为什么”——比如为什么人类认知偏偏偏好这种词序,而非另一种。
那些被证实的普遍规律,本质上都是人类认知和交流需求妥协的结果。从认知层面看,语言结构必须适配人类大脑的处理能力:比如“词序和谐”能减少理解时的认知负担,让我们不用反复调整解析逻辑;层级结构则是为了满足复杂思维的表达需求——没有递归嵌套的语法,我们没法说出“我知道你觉得他认为这件事不对”这样的句子。
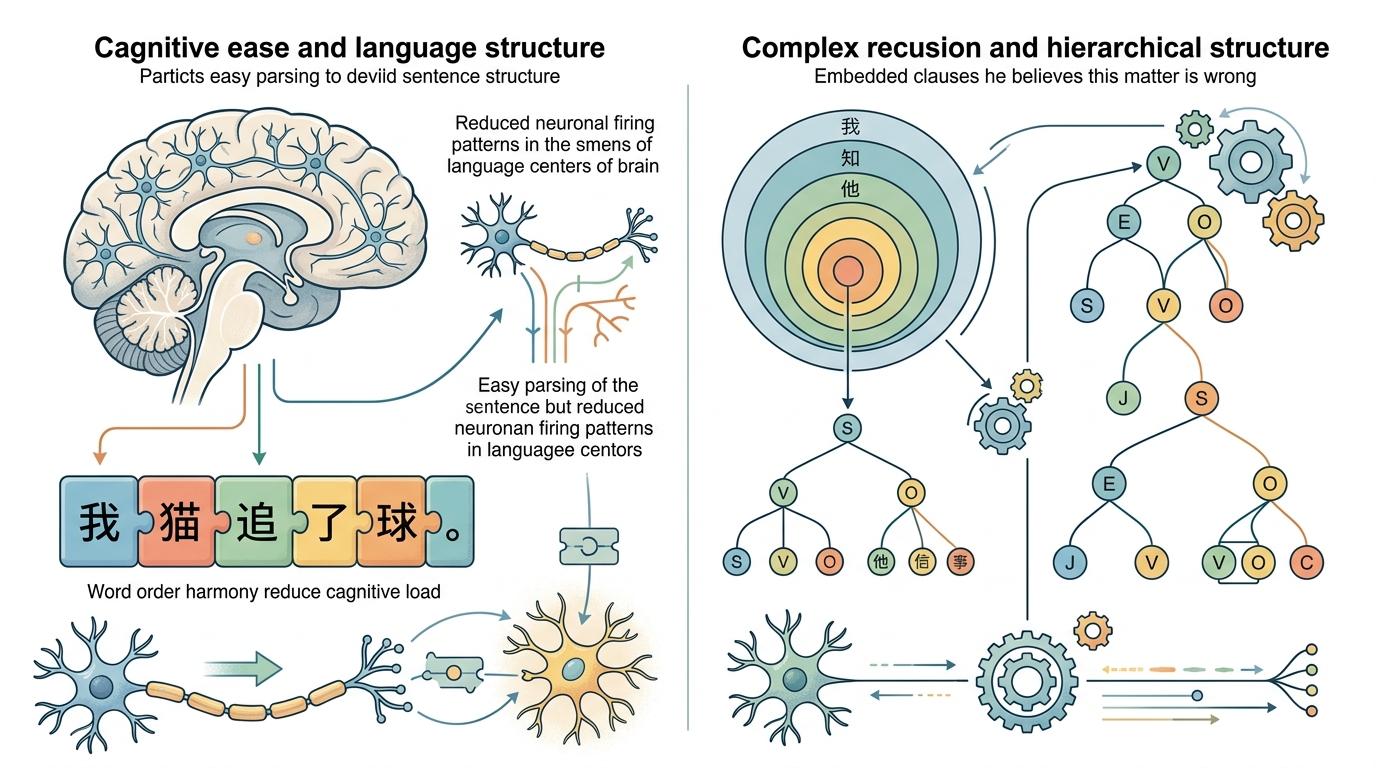
从交流层面看,语言要在“简洁”和“清晰”之间找平衡:过于简洁会导致歧义,过于繁琐又会降低效率。比如很多语言里的复数标记,哪怕上下文能看出数量,依然会保留,这就是为了避免误解的“有效冗余”。而高频词更短、低频词更长的规律,也是为了在节省精力和传递信息之间达成最优解。
不过,认知和交流压力不是唯一的驱动因素。社会结构、地理环境甚至技术发展都会影响语言演化:比如使用人数多、接触频繁的语言,形态往往更简单;而互联网催生的网络用语,则是语言适应快速交流的新形态。
当我们谈论语言时,我们其实在谈论自己——谈论人类共享的认知边界,也谈论不同族群的文化选择。这项研究没有终结语言多样性的浪漫,反而让那些看似随机的语法差异,有了更深刻的参照:每一种语言都是在“普遍认知框架”下,长出的独特枝干。
未来,语言学家还会继续用更精细的模型,探索剩下三分之二未被证实的规律,甚至发现新的普遍特征。而对于我们普通人来说,下次听到一门完全陌生的语言时,或许可以多一份好奇:它的语法里,藏着哪些和我们一样的“人类共性”?
语言的共性,是人类最隐秘的集体签名。
点击催更,成为大圆镜下一个视频选题!