对抗知识焦虑,从看懂这条开始
App 下载
AI网络安全的护城河,不在模型而在系统
小参数模型|FreeBSD远程代码执行|OpenBSD漏洞|Project Glasswing|Mythos模型|AI安全治理|人工智能
对抗知识焦虑,从看懂这条开始
App 下载小参数模型|FreeBSD远程代码执行|OpenBSD漏洞|Project Glasswing|Mythos模型|AI安全治理|人工智能
2026年4月,一款名为Mythos的AI模型引爆网络安全圈:它自主找出了27年未被发现的OpenBSD漏洞,17年的FreeBSD远程代码执行漏洞,甚至能自动写出绕过沙箱的复杂攻击链。研发方投入上亿美元,联合科技巨头启动Project Glasswing,宣称要靠这款前沿模型筑牢关键软件的安全防线。但就在所有人都以为超大模型就是AI安全的终极答案时,一组测试数据推翻了这个共识——用成本仅0.11美元/百万token的3.6亿参数小模型,居然复现了Mythos展示的大部分漏洞检测能力。
你可以把AI的网络安全能力想象成一把锯子——它不是平滑上升的斜坡,而是高低错落的齿峰。在基础漏洞检测任务里,比如FreeBSD的NFS缓冲区溢出,3.6亿参数的小模型能和Mythos这类前沿大模型做得一样好;但到了需要数学推理的复杂漏洞,比如OpenBSD的SACK整数溢出问题,部分小模型会直接“罢工”,而另一款5.1亿参数的模型却能完整还原漏洞链。
更反常识的是,在区分“伪漏洞”的测试中,小模型的表现居然超过了不少大模型。比如一段看似有SQL注入风险的Java代码,实际是安全的,多款小模型能精准判断,而部分前沿大模型却误判为高危漏洞。这就是AI安全能力的“锯齿性”:没有通吃所有任务的“全能模型”,只有在特定场景下表现突出的“专长模型”。

这种非线性的能力分布,直接打破了“模型越大,安全能力越强”的惯性认知。
真正的AI安全壁垒,从来不是某一个模型,而是一套把模型、工具、知识和流程拧成一股绳的系统——就像一台精密的流水线,模型只是其中的一个工位。
这套系统的核心是五个闭环环节:首先是用低成本小模型做“广撒网”式的代码扫描,快速定位高风险函数;接着用针对性模型做漏洞检测,识别异常代码;然后通过自动化工具验证真假漏洞,过滤掉90%以上的误报;再由AI生成补丁,最后把修复方案同步给开源项目维护者,建立长期信任。
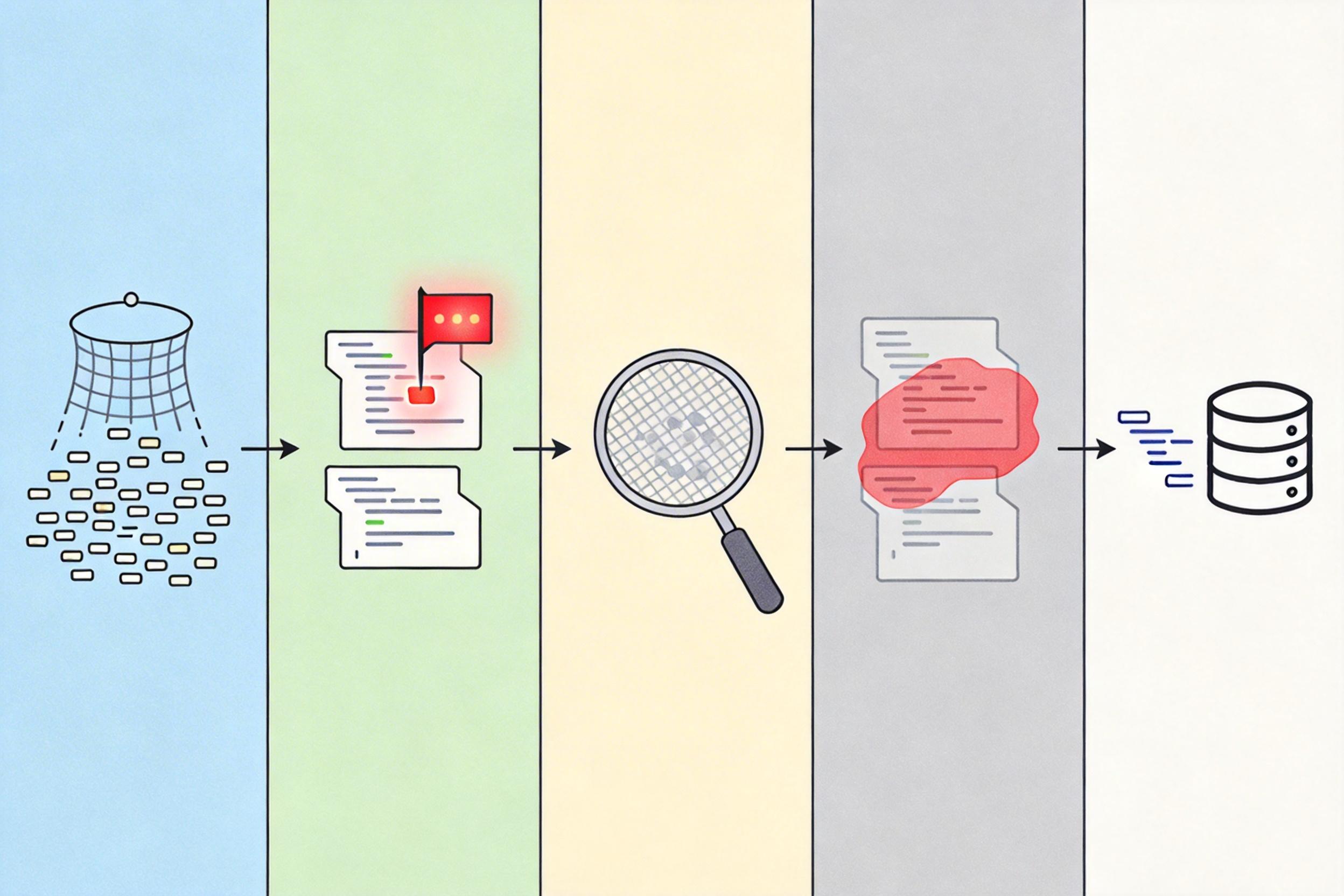
比如AISLE团队的实践,他们用小模型配合这套系统,一年里发现了180多个经外部验证的漏洞,还得到了OpenSSL官方的认可。而如果只靠单一大模型,不仅成本要翻几十倍,还会因为误报太多,被维护者当成“噪音”忽略。
这里的关键是“安全知识的嵌入”:系统里藏着安全专家的经验——比如哪些代码区域是攻击热点,什么样的漏洞会被攻击者优先利用,如何写补丁才能不引入新问题。这些知识不是模型能凭空学会的,而是要靠人把它变成系统里的规则、验证工具和反馈机制。
当然,前沿大模型也不是毫无不可替代性。在“漏洞利用”的环节,比如把一个单一漏洞变成能远程控制服务器的攻击链,Mythos这类模型展现出了小模型没有的创造力。
比如FreeBSD的NFS漏洞,溢出空间只有304字节,放不下完整的攻击代码。Mythos想出了一个巧妙的办法:把攻击链拆成15段,通过15次RPC请求分批写入内存。这种“化整为零”的思路,是小模型目前还学不会的。但要注意,这种能力更多是“攻击端”的突破,而对于防御方来说,更核心的需求是快速发现漏洞、生成可靠补丁、获得维护者信任——这些恰恰是系统能解决的问题。
而且,大模型的这种创新能力,也不是完全不可替代。如果给小模型配上工具调用的能力,比如让它自己运行代码、调试攻击,差距可能会进一步缩小。
Mythos的出现,本质上是给AI安全领域做了一次“能力科普”:原来AI能做到这么多事。但它也让我们看清了一个更重要的真相:AI安全的未来,不是比谁的模型更大,而是比谁的系统更高效、更可信、更能把人和AI的优势结合起来。
就像古代的护城河,不是靠一道墙就能守住城池,而是要靠城墙、护城河、吊桥、士兵和瞭望塔的协同防御。AI安全的“护城河”,是模型、工具、流程和人的合力。
模型是武器,系统才是堡垒。