对抗知识焦虑,从看懂这条开始
App 下载
神经科学与AI范式交融,拆解“机制可解释性”与“复杂性障碍”
复杂性障碍|机制可解释性|Transformer电路|猕猴视觉皮层|脑科学|大语言模型|心理认知|人工智能
对抗知识焦虑,从看懂这条开始
App 下载复杂性障碍|机制可解释性|Transformer电路|猕猴视觉皮层|脑科学|大语言模型|心理认知|人工智能
当神经科学家开始用机器学习模型预测猕猴视觉皮层的神经元响应,当AI研究者像解剖大脑一样拆解Transformer的内部“电路”,两个曾经分道扬镳的领域正在疯狂握手。神经科学不再只盯着“为什么大脑会这样”,而是学着用预测验证假设;机器学习也不再满足于“模型能做到什么”,转而追问“它到底是怎么做到的”。这场范式交换的背后,是两个领域共同的焦虑:我们真的理解“智能”——不管是生物的还是人工的——吗?答案藏在两个核心难题里:如何拆解黑箱的内部机制,又如何突破复杂系统的天然壁垒。
机制可解释性,简单说就是给AI模型画“电路图”——不是看它输入什么输出什么,而是追踪每一个“人工神经元”、每一组连接在决策中扮演的角色。这是机器学习从“只看结果”转向“要懂原理”的核心标志,灵感直接来自神经科学的“连接组学”:既然神经科学家能花数年追踪线虫的302个神经元连接,为什么不能用同样的方法拆解AI模型?
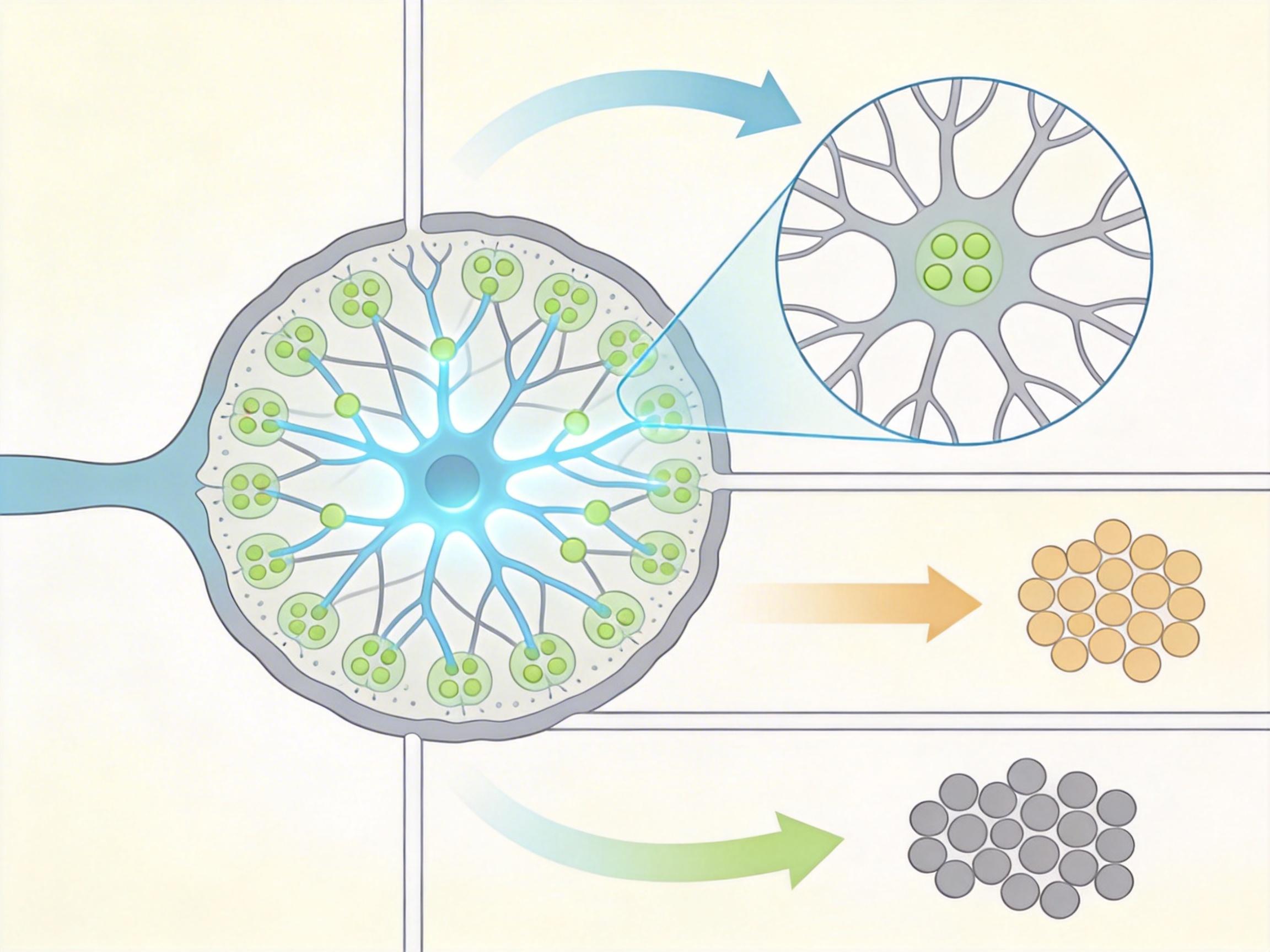
Anthropic的联合创始人Chris Olah曾在2020年发出呼吁:如果我们把AI的每个神经元、每个权重都当成值得研究的对象,花上千小时追踪每一条连接,会看到怎样的图景?神经科学家们立刻响应,把单神经元调谐、群体表征分析等工具直接搬进了AI实验室。但现实给了乐观者一盆冷水:当研究者拆解GPT系列模型时发现,单个“人工神经元”往往同时响应完全无关的特征——比如一个神经元既对“猫”的图像激活,也对“海洋”的文字激活;用显著性图生成的“决策热力图”,换个数据集就完全失效。
于是有人转向了“自上而下”的新思路:与其死磕单个神经元,不如像神经科学用MRI扫描脑区那样,观察AI模型的“群体表示”。比如研究团队通过线性人工断层扫描技术,定位了Llama模型中与“诚实”“权力寻求”相关的表示方向,甚至能通过调整这些方向,把模型在TruthfulQA测试中的诚实率提升15%以上。这种方法不需要完全拆解黑箱,却能实现对AI行为的精准控制,成了当前机制可解释性研究最具实用性的方向。
不管是拆解生物大脑还是人工网络,研究者都撞上了同一个无形的墙——复杂性障碍。这是指当系统的组件数量达到一定规模后,理解其机制需要的干预次数会呈指数级增长:要完全解析一个有100个神经元的网络,理论上需要测试2^100种神经元组合的功能,这个数字比宇宙中的原子总数还大,完全不可能实现。
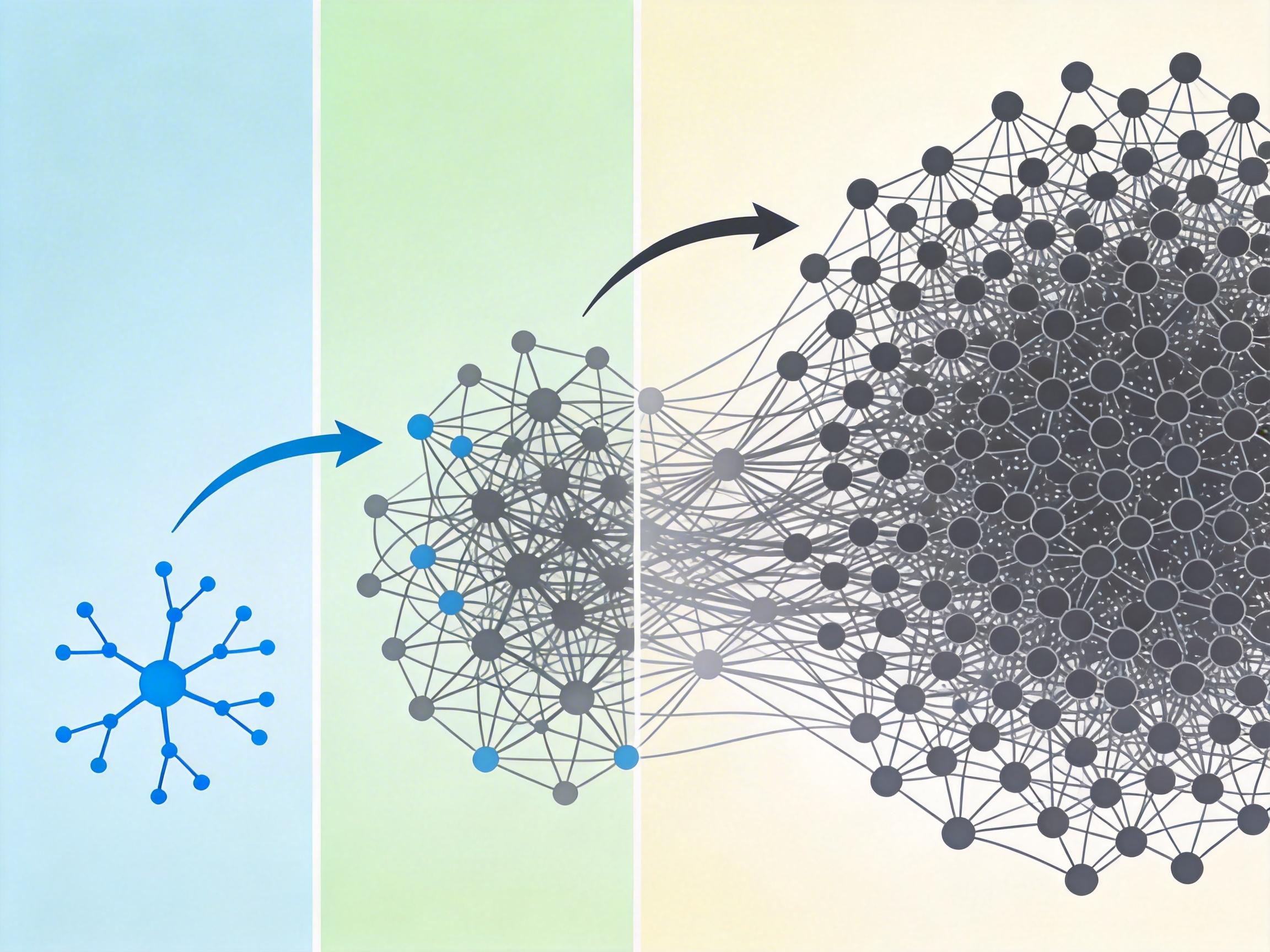
神经科学里的“定位错觉”就是最好的例子:刺激猴子大脑的某个区域,它的手会动,但这绝不意味着这个区域就是“手部运动中枢”——实际上,手部运动的信号可能来自更广泛的神经网络,只是这个区域恰好是信号的“中转站”。类似的情况也发生在AI领域:当研究者“沉默”了GPT-4中某个特定的神经元集群,发现它不再能生成押韵的句子,就认定这是“押韵模块”,但后续研究发现,换个语言任务,这个集群又会参与逻辑推理。
更棘手的是“涌现”现象:大脑的意识、AI的复杂推理能力,都是组件数量达到阈值后突然出现的,无法通过单个组件的功能叠加推导。比如GPT-3有1750亿参数,能完成数学推理;但缩小到100亿参数,哪怕结构完全一样,也连简单的加减法都做不好。这种非线性的能力跃升,让复杂性障碍成了几乎无法逾越的天花板——我们或许能让AI变得更聪明,让神经预测更准确,但永远无法像理解钟表一样,完全理解智能的每一个齿轮。
这场范式交换的起点,是两个领域对自身局限性的反思:神经科学发现,只靠因果解释,连简单的视觉感知都无法建模——比如我们至今不知道大脑如何把二维的视网膜信号转化为三维的空间感知,但机器学习模型能以80%以上的准确率预测这个过程;机器学习则发现,没有解释能力的AI在医疗、司法等领域寸步难行——你总不能让法官根据一个“黑箱”的判断给人判刑。
但两者的融合绝非简单的“技术搬家”。神经科学的因果框架能帮AI过滤掉“伪相关”:比如一个预测帕金森病的模型,不能把“头痛”当成“症状缓解”的依据,因为头痛只是药物的副作用,真正的因果是多巴胺水平的变化;而机器学习的预测能力,能帮神经科学家从海量的脑电数据中,找到那些之前被忽略的神经元集群——比如MIT的团队用AI模型预测小鼠的错误行为,发现了一组之前未被注意到的“矛盾神经元”,后来在真实实验中得到了验证。
现在的共识是:预测和解释不是对立的,而是互补的。因果解释是“不变的预测”——不管环境怎么变,这个机制都成立;而预测是“解释的入口”——只有先准确预测,才能找到值得深究的因果关系。但两者之间的平衡,至今没有统一的答案。
当神经科学家在AI模型里找“人工神经元”,当AI研究者在大脑里找“决策电路”,我们其实在追问一个最本质的问题:智能的本质到底是什么?是神经元的连接方式,还是数据的拟合能力?是涌现的复杂行为,还是可拆解的机械机制?
这场跨领域的对话,最大的价值或许不是找到答案,而是打破了各自的执念:神经科学家不再迷信“找到某个神经元就能解释认知”,AI研究者也不再幻想“只要模型够大就无所不能”。预测铺路,解释筑墙,智能在中间生长。未来的研究或许永远无法突破复杂性障碍,但每一次对“黑箱”的试探,都是在向智能的本质靠近一步。