对抗知识焦虑,从看懂这条开始
App 下载
AI编程代理的隐形盲区:网页读取的8道坎
开发者效率|API文档读取|网页解析难题|金丝雀令牌测试|Agent Ecosystem团队|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载开发者效率|API文档读取|网页解析难题|金丝雀令牌测试|Agent Ecosystem团队|AI智能体|人工智能
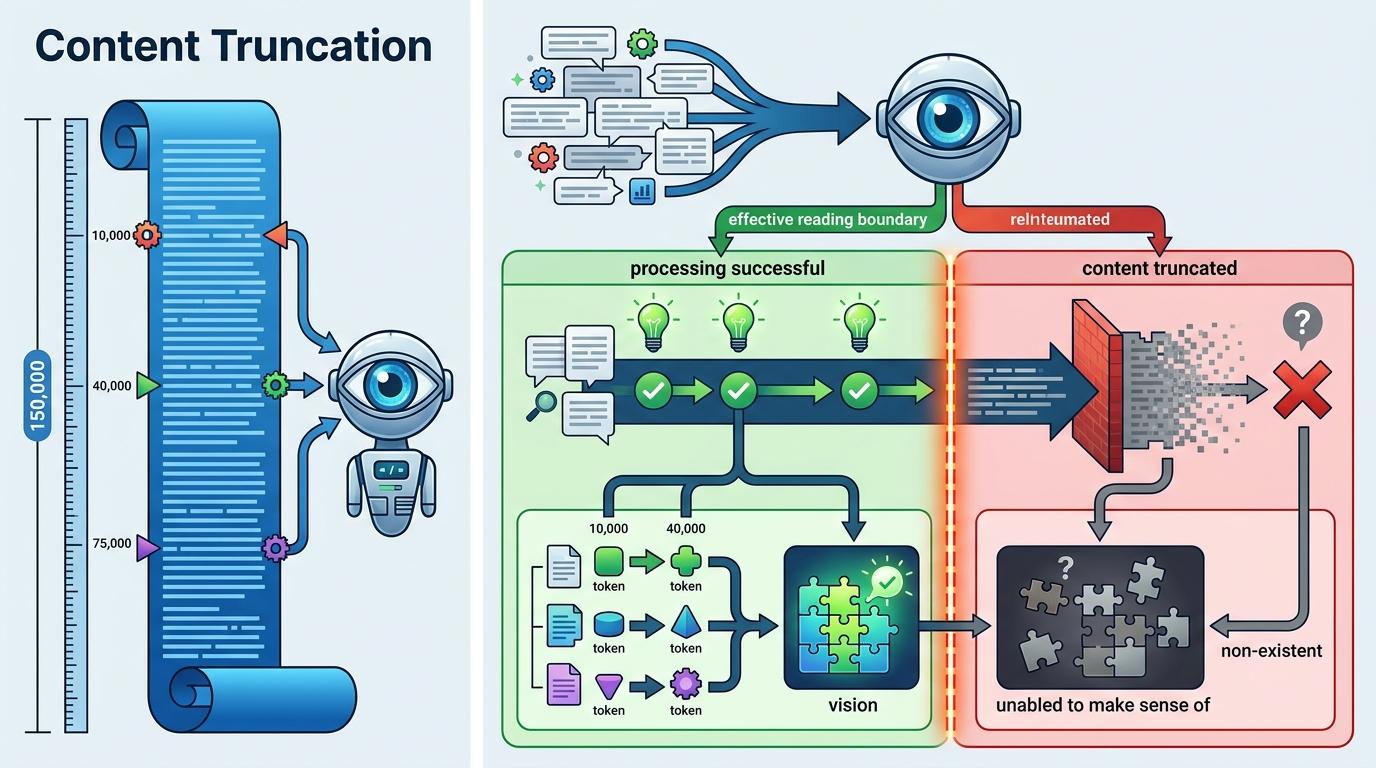
当你让AI编程代理去读一份API文档,它大概率会告诉你任务完成了——但你永远不知道,它是不是只看到了前10000字的内容,或者把80000字的CSS代码当成了文档正文,甚至对着一个需要JavaScript渲染的空壳页面发呆。2026年初,Agent Ecosystem团队上线了一个特殊的测试,用10个埋着「金丝雀令牌」的网页,第一次把这些AI代理的「看不见」和「看不懂」摆到了台面上。目前主流AI代理的得分集中在14-18分,满分20分的测试里,没有一个能完美通关。这些隐形的盲区,正在悄悄拖慢数百万开发者的效率。
你可以把AI编程代理的网页读取过程,想象成一个戴着老花镜、只会看印刷体的老人,闯进了堆满动态广告、折叠菜单和手写批注的现代书店——它能看到的,永远只是它「能理解」的部分。
第一道坎是内容截断。哪怕是标称支持超长上下文的模型,实际有效读取长度往往只有标称值的1%:在150000字符的测试页面里,埋在10000、40000、75000字符位置的令牌,能精准测出代理的「视力边界」,超过这个边界的内容,对它来说就是不存在的。
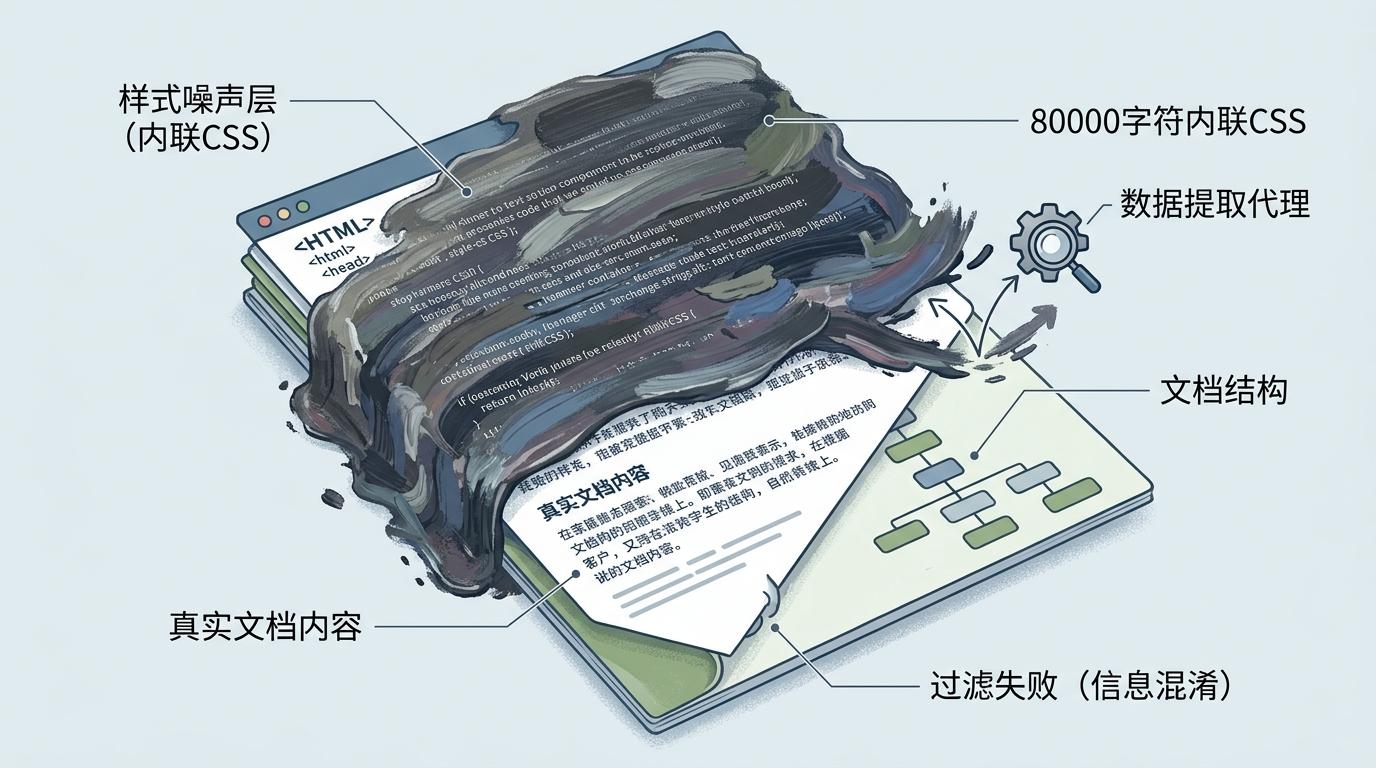
第二道坎是样式噪声。80000字符的内联CSS代码像一层厚厚的油漆,把真实的文档内容严严实实地盖在下面。大多数代理会把这些CSS当成正文的一部分,要么直接忽略,要么连带着把有用信息一起过滤掉——就像在一堆颜料里找一张白纸。
第三道坎是客户端渲染。现代网页有96%的内容需要JavaScript执行后才会显示,但绝大多数AI代理根本不会「运行」JS,它们看到的只是一个空壳页面,就像拿到了一本只有封面的书。
剩下的坎更刁钻:多标签页的内容被序列化后,代理只会读第一个标签;HTTP 200状态码的「404页面」会被当成正常内容;未闭合的Markdown代码块会把后面所有内容变成「代码」;跨主机的301重定向,代理会因为安全限制直接放弃——这些都是开发者每天都会遇到的真实场景,却成了AI代理的「致命题」。
这个名为Agent Reading Test的基准测试,最巧妙的地方在于它的「反作弊设计」:它没有让AI代理直接去寻找令牌——那样很容易触发模型的相关性过滤,导致代理刻意去「找」令牌而忽略真实任务。
测试的流程是这样的:先给AI代理布置一系列真实的文档任务,比如「提取API的参数说明」「找到错误代码的解决方案」,等代理完成所有任务后,再告诉它页面里埋了令牌,让它报告自己看到了哪些。只有这样,才能测出代理在「真实工作」中到底能读取到多少内容。
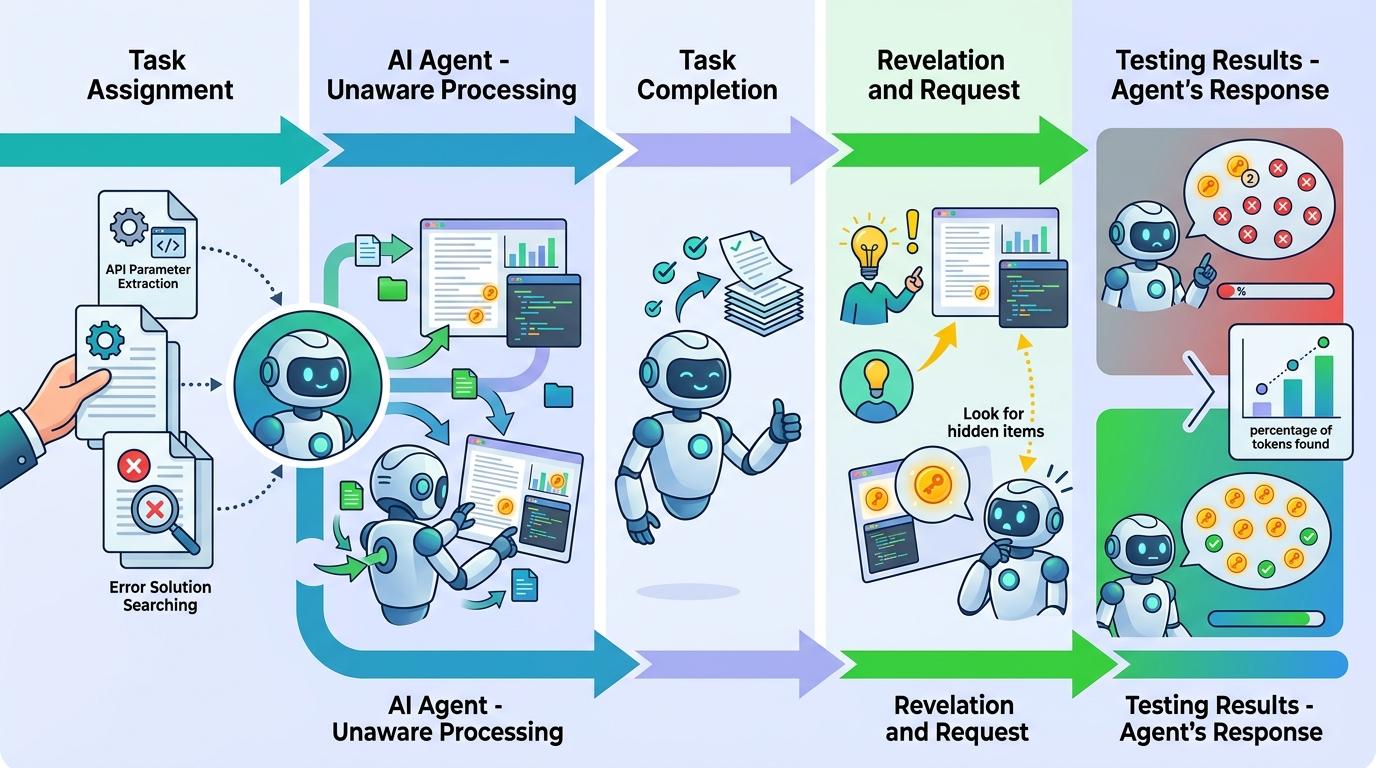
每个测试页面都对应Agent-Friendly Documentation Spec里的一个具体问题——这个由Agent Ecosystem团队制定的规范,包含8大类22项检查,专门评估文档网站对AI代理的友好程度。比如规范里明确要求,文档要避免超长单页、尽量用服务端渲染、支持Markdown格式访问,这些都是针对AI代理的「视力缺陷」提出的解决方案。
测试的满分是20分,每找到一个令牌得1分,正确完成任务得1分。目前主流AI代理的得分在14-18分之间,没有一个能拿到满分。这意味着,哪怕是最先进的AI代理,在读取网页时也会遗漏至少2-6个关键信息点。
Agent Reading Test的出现,其实是在倒逼两个方向的改变:一是AI代理自身的技术迭代,二是文档网站的设计优化。
从代理端来看,开发者需要给AI加上「真实浏览器」的能力——比如集成Playwright、Selenium等无头浏览器,让代理能执行JavaScript、模拟点击标签页;同时优化上下文管理,用RAG(检索增强生成)技术把长文档拆分成小块,再拼接成完整的信息。Amazon在2026年3月上线的Bedrock AgentCore Evaluations平台,已经实现了对代理工具调用、推理逻辑和上下文理解的全流程评测,能精准定位代理的「盲区」。
从文档端来看,越来越多的网站开始遵循Agent-Friendly Documentation Spec:比如提供Markdown格式的文档入口、把长文档拆分成多个小页面、避免跨主机重定向、在页面顶部嵌入代理专用的索引文件llms.txt。这些改变不仅能让AI代理更好地读取内容,也能让人类开发者更高效地查找信息——毕竟,对AI友好的文档,对人类往往也更友好。
当然,这个过程也伴随着新的挑战:比如AI代理的安全风险——如果代理能模拟人类点击、执行JS,那么它也可能被用来执行恶意操作;还有法律与伦理问题——爬取网页的边界在哪里,如何避免AI代理获取敏感信息。这些问题,都需要技术、规范和法律的共同配合才能解决。
当我们谈论AI编程代理的能力时,我们往往只关注它能生成多么精妙的代码,却忽略了它最基础的能力:读取和理解信息。就像一个厨师,哪怕厨艺再好,如果连菜谱都读不懂,也做不出像样的菜。
Agent Reading Test让我们第一次看清了AI代理的「视力缺陷」,也让我们意识到:AI与网页的关系,从来不是单向的「读取」,而是双向的「共生」。网页需要适应AI的读取能力,AI也需要进化出更强大的理解能力。
**技术的盲区,从来都是进化的起点。**未来的AI编程代理,不仅能写出好代码,更能「看懂」整个互联网。