对抗知识焦虑,从看懂这条开始
App 下载
自闭症不是单一疾病,精准分型才是干预关键
行为边界|遗传亚型|精准分型|自闭症谱系障碍|神经退行性疾病|医学健康
对抗知识焦虑,从看懂这条开始
App 下载行为边界|遗传亚型|精准分型|自闭症谱系障碍|神经退行性疾病|医学健康
当一位妈妈带着3岁的孩子走进诊室,指着孩子重复转圈的动作问“这是不是自闭症”时,医生的回答往往带着不确定性——同样被诊断为自闭症谱系障碍,有的孩子能正常上学,有的却连基本语言都难以掌握;有的对声音极度敏感,有的却对疼痛反应迟钝。这种巨大的个体差异,让“自闭症”更像一个模糊的“筐”,而非精准的疾病定义。直到2025年国际自闭症研究协会年会上,一组研究数据打破了这个僵局:科学家终于在这个庞大的“谱系”里,划出了4个有着明确遗传和行为边界的亚型。这意味着,我们对自闭症的认知,终于从“一刀切”走向了“精准画像”。
过去我们总说“自闭症谱系”,但没人能说清这个谱系里到底藏着多少种不同的“疾病”。普林斯顿大学团队依托SPARK队列的5392名自闭症儿童数据,用239项行为和临床特征做了一次“精准拆解”,最终识别出4个稳定的亚型:
占比37%的“社会/行为挑战型”孩子,核心自闭症症状明显,常伴随多动症、焦虑等共病,但发育里程碑和普通孩子无异;19%的“混合型伴发育迟缓型”则刚好相反,语言、运动发育明显滞后,却很少出现情绪问题;34%的“中度挑战型”症状最轻,共病也最少;剩下10%的“广泛影响型”最为严重,不仅核心症状突出,还携带了最高负荷的罕见致病基因突变。
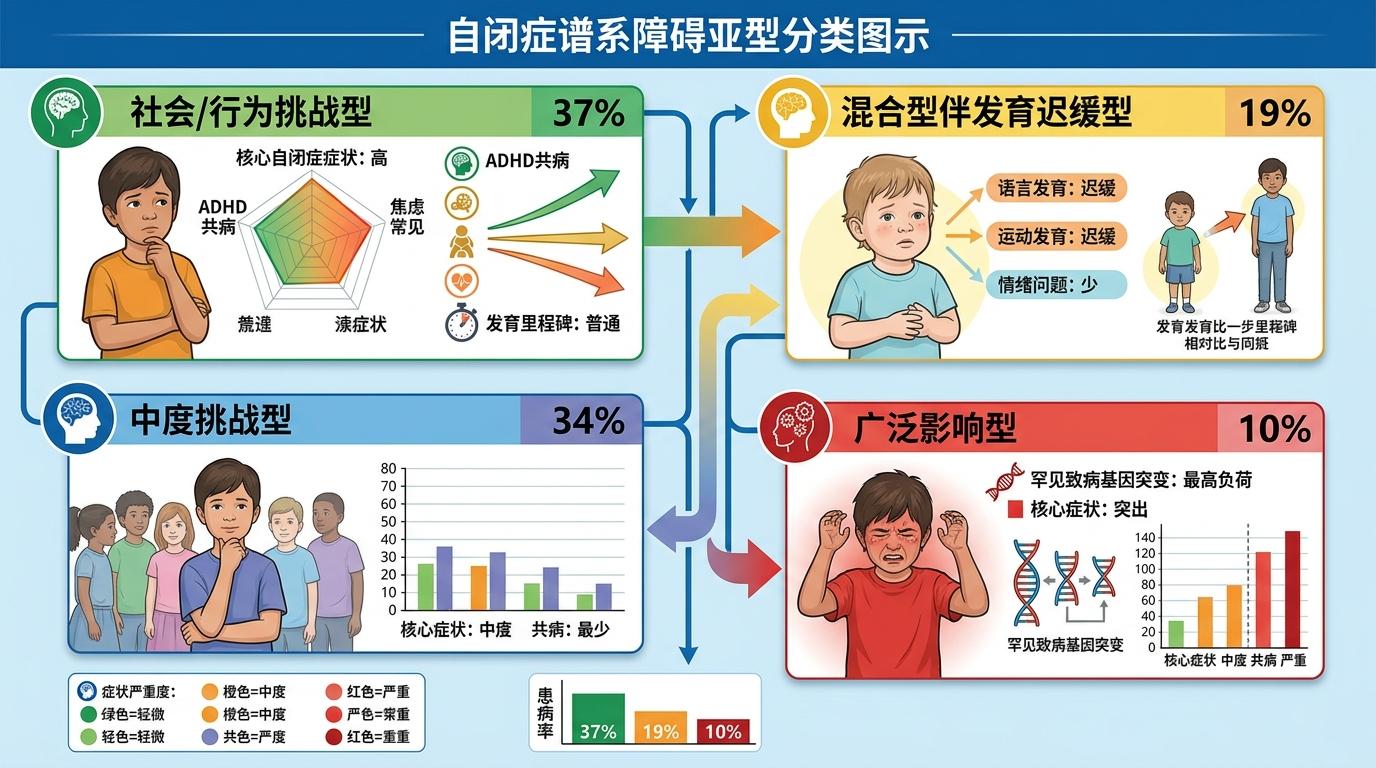
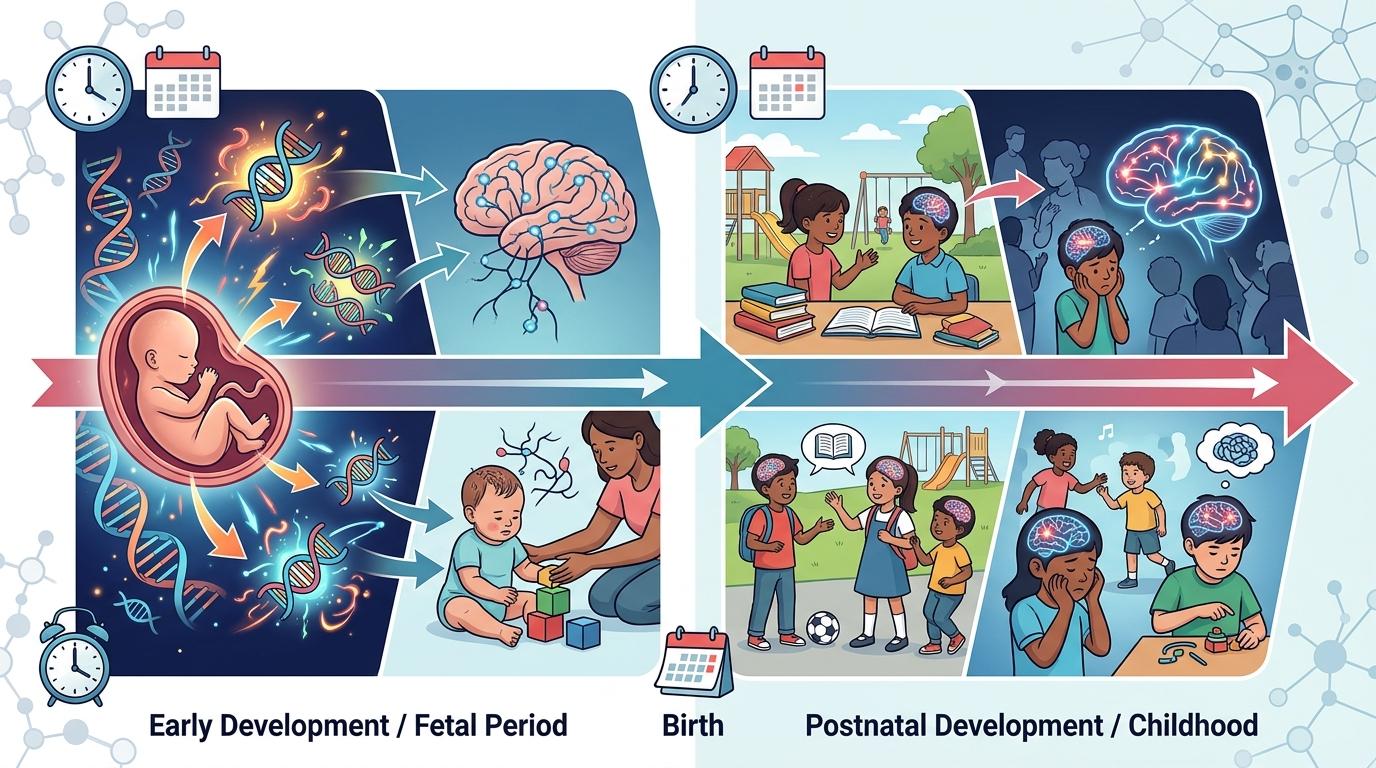
更关键的是,这些亚型的差异能直接追溯到基因表达的时间窗:发育迟缓亚型的致病基因多在胎儿期活跃,而社会/行为亚型的基因则在出生后才开始影响脑发育——这也解释了为什么有的孩子早早就被确诊,有的却要到学龄期才显现症状。
在分型研究之外,科学家们还在寻找能“一眼看穿”自闭症的生物标志物——毕竟靠行为观察诊断,不仅耗时,还容易受医生经验和环境影响。
美国ABC-CT项目耗时十年追踪了700多名孩子,终于从数十项指标里筛选出两个靠谱的标记:一个是脑电里的N170潜伏期,自闭症孩子识别面部时的脑电反应比普通人慢几十毫秒;另一个是眼动追踪里的OMI指数,他们盯着人脸的时间明显更短。这两个标记不仅能稳定区分自闭症和普通孩子,还能在不同年龄段保持一致。
但这些标记也有局限:它们只能说明“这是自闭症”,却没法区分属于哪个亚型。于是科学家开始尝试多模态融合——把基因数据、脑影像、眼动轨迹甚至血液代谢指标放进AI模型,让机器自动识别亚型。目前这类模型的准确率已经能达到85%以上,比传统的行为评估更客观、更高效。
不过,这些生物标记离真正走进临床还有距离:N170的检测需要专业设备,眼动追踪的结果也需要标准化解读,更重要的是,我们还没找到能预测干预效果的标记——毕竟精准医学的最终目标,是让每个孩子都能得到最适合自己的治疗。
精准分型和生物标记的突破,正在重构自闭症的诊疗逻辑,但这条路并不顺畅。
最大的争议来自伦理:当我们能通过基因检测提前判断一个孩子属于哪种亚型,会不会带来新的歧视?保险公司会不会拒绝为“广泛影响型”的孩子投保?更现实的问题是成本:全基因组测序、多模态AI诊断的费用不菲,普通家庭难以承受。
还有技术上的难题:现有的分型研究大多基于欧美人群的数据,对其他种族的适用性还没验证;很多生物标记在群体水平有效,但放到个体身上准确率就会下降。更关键的是,我们还没搞清楚不同亚型对干预的反应——比如同样是应用行为分析,对“社会/行为挑战型”有效,对“广泛影响型”可能就收效甚微。
不过这些挑战并没有挡住前进的脚步:全球多个研究中心已经开始共享标准化数据,AI模型也在不断优化以适应不同人群。更重要的是,自闭症社群的声音越来越被重视——研究不再是“科学家说了算”,而是有患者和家长参与设计,确保技术最终服务于人,而非相反。
当我们不再把自闭症当成一种单一疾病,而是一组有着不同病因、不同表现的神经发育障碍,那些曾经模糊的问题突然有了清晰的答案:为什么有的干预有效,有的无效?为什么有的孩子能融入社会,有的却需要终身支持?
“精准,才是对个体最大的尊重。”这句话不仅适用于自闭症,也适用于所有复杂疾病。未来的诊室里,医生或许不会再只说“你的孩子是自闭症”,而是会拿出一份详细的报告:他属于哪个亚型,致病基因是什么,哪种干预方法最有效,甚至能预测他的发育轨迹。
这一天或许还需要时间,但至少我们已经走在了正确的路上——从“模糊的谱系”到“精准的个体”,科学正在让每个独特的生命,都得到最恰当的照护。