对抗知识焦虑,从看懂这条开始
App 下载
自动化工具揪出8年前帕金森研究数据漏洞
马库斯·恩格伦德|自动化检测工具|数据造假|肠道微生物组|帕金森病|计算科学|神经生物学|生命科学|数理基础
对抗知识焦虑,从看懂这条开始
App 下载马库斯·恩格伦德|自动化检测工具|数据造假|肠道微生物组|帕金森病|计算科学|神经生物学|生命科学|数理基础
2016年,一篇发表在《Cell》的论文震动了神经科学界——它首次提出帕金森病起源于肠道而非大脑,随后被引用超过3000次,直接推动了肠道微生物组治疗帕金森的新方向。但这份支撑起整个理论的关键数据集,躺在开放数据仓库Dryad上8年,直到2024年才被一款自动化软件揪出问题:两组完全不同实验小鼠的行为数据,出现了整段的复制粘贴。没人知道,这8年间有多少后续研究,建立在这组掺了水的数据之上。为什么如此明显的漏洞,整整8年都没人发现?
程序员马库斯·恩格伦德开发这款自动化检测工具的初衷,只是好奇——2023年诺贝尔得主托马斯·聚德霍夫实验室、蜘蛛生态学家乔纳森·普鲁伊特的造假案,都是靠公开数据里的整段复制粘贴暴露的,为什么没人用工具批量筛查? 他拉上几个志愿者,把程序对准了Dryad上的600个公开Excel数据集。结果让他们意外:18个数据集存在严重的数据异常,占比3%。除了那篇帕金森论文,还有鸵鸟与蛇类的毒素耐受性数据高度相似,疑似复制后手动微调;克隆鱼行为研究里,体长数据和行为数据完全错位,导致每条鱼的体长被重复分配给了4个不同个体。
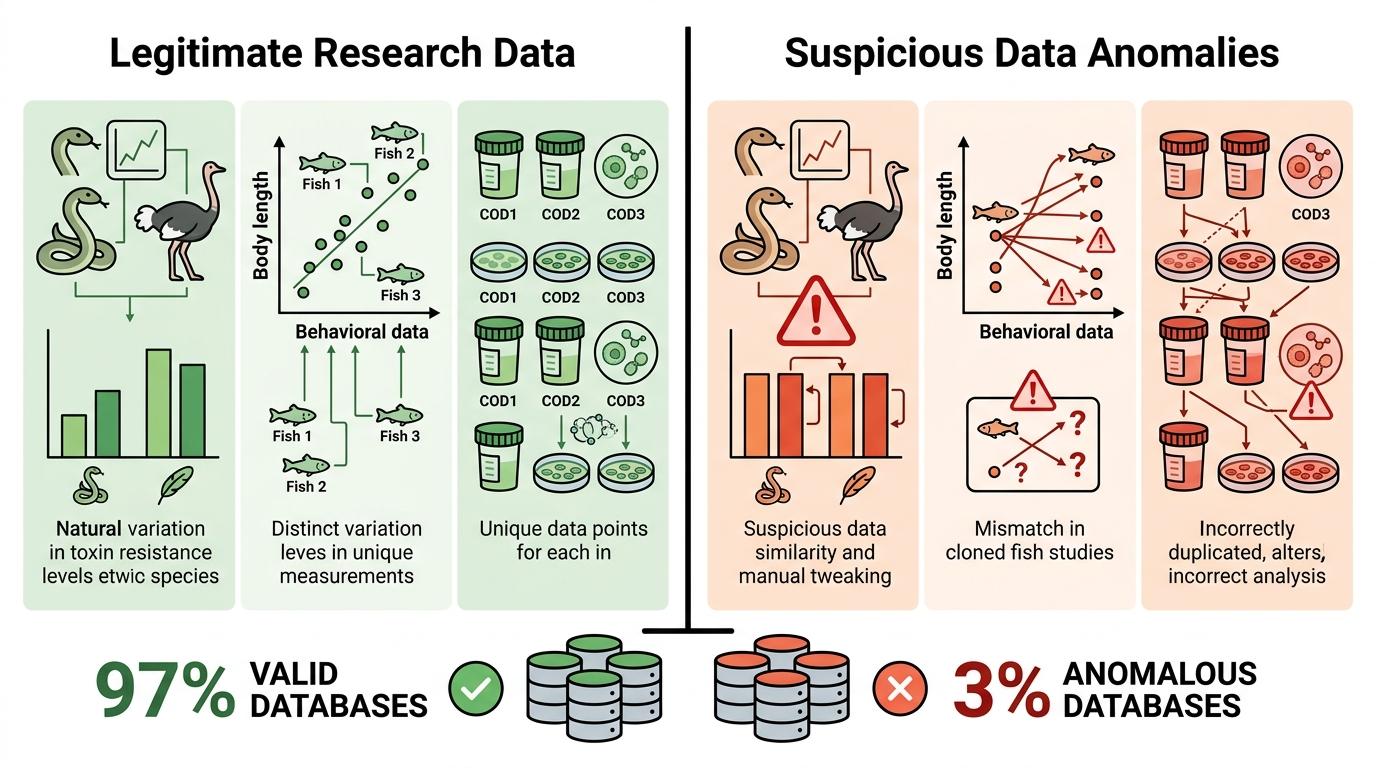
这些问题里,有的是无心之失——比如克隆鱼研究的作者承认,是合并两个数据文件时的ID对齐错误;有的则疑点重重——帕金森论文的作者至今未回应,而那组重复数据占了对应实验组样本的40%到50%,直接影响核心结论的可信度。
要理解这场“数据扫雷”的前提,得先搞懂Dryad这类开放数据仓库的作用——它是科研界的“公开档案柜”,要求作者发表论文时同步上传原始数据,任何人都可以下载验证。 这原本是为了让科研更透明:其他研究者能重复实验、验证结论,避免错误结论流传。但现实是,大部分公开数据上传后就成了“死数据”——没人会花时间逐行核对Excel表格,期刊的同行评审也只看论文结论,不会去验证原始数据。那篇帕金森论文的数据漏洞,就是最好的例子:8年里,3000次引用,却没人点开过Dryad上的那个Excel文件。 但正是这份“透明”,给了自动化工具可乘之机。恩格伦德的程序不需要理解实验逻辑,只需要识别数据里的异常模式:比如不同实验组出现连续5个完全相同的数值,或者某列数据的最后一位数字诡异一致——后者正是鸵鸟与蛇类数据的疑点之一,作者解释为仪器测量误差,但统计学上这种巧合的概率几乎为零。
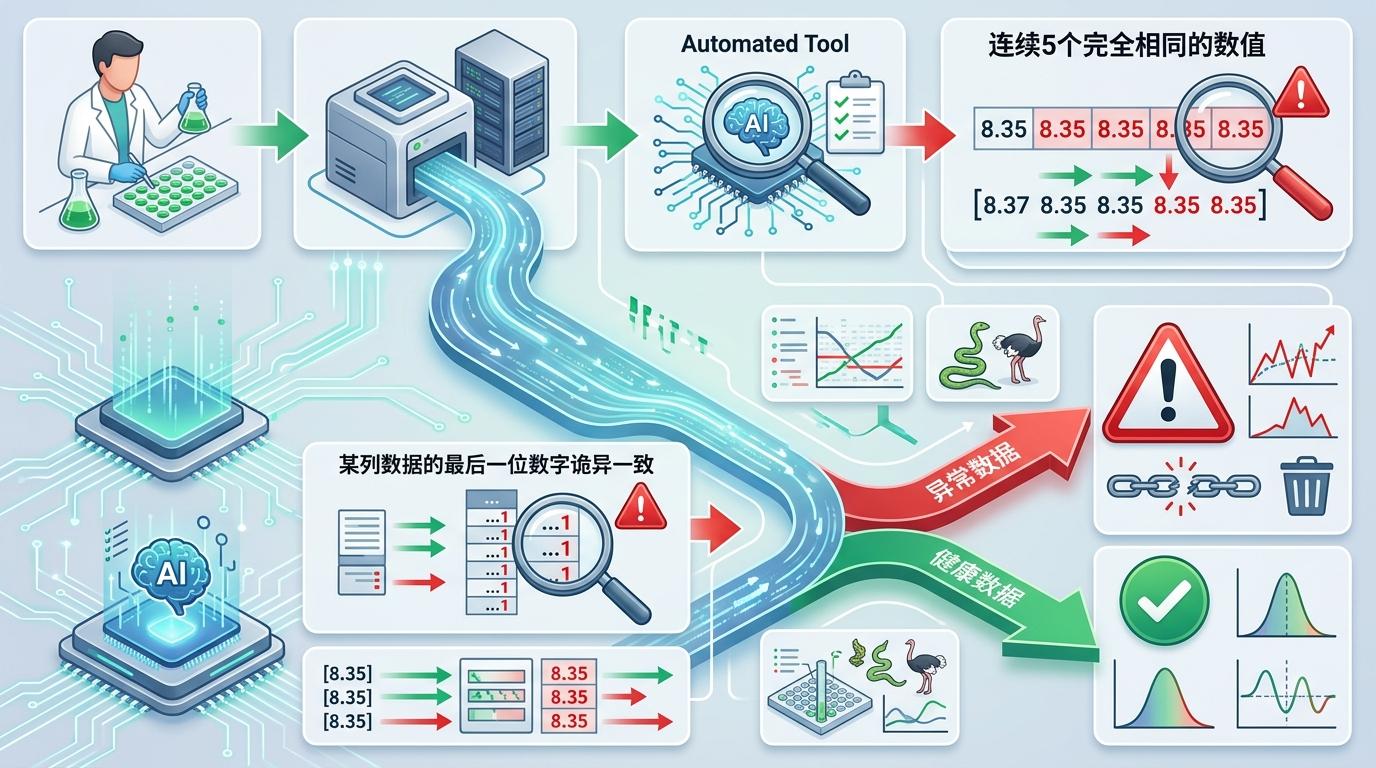
其实早有类似的自动化检测工具,比如针对图像造假的Proofig AI,已经被《Science》等顶级期刊采用,能识别图像的克隆、拼接甚至旋转后的重复。但针对数值数据的检测,一直是空白。 这背后是科研体系的深层问题:“发表即胜利”的评价体系下,研究者忙着产出新论文,没人愿意花时间去“找茬”;期刊和机构更在意论文的引用量和影响力,而不是数据的真实性——毕竟揭露错误会影响期刊的声誉,也会让资助机构显得浪费了钱。 恩格伦德的团队能推进这项工作,全靠志愿者和一笔5万美元的私人资助。他们已经把15个异常案例发布到学术评论平台PubPeer,Dryad也在配合联系期刊和作者要求修正,但进展缓慢:有的作者承认错误并修正了数据,有的则选择沉默。按照3%的比例估算,Dryad上剩下的24000个数据集里,还藏着约700个类似的“数据炸弹”。
当恩格伦德的程序扫过那些沉睡的Excel表格时,它揪出的不只是几个数据错误,更是科研界长久以来的自欺欺人——我们默认同行评审能把关,默认作者会诚实,却忘了最基础的“验证”二字。 自动化工具成了科研诚信的意外守门人,但它终究只是工具。真正的改变,得从科研体系的底层逻辑开始:当我们不再只看论文数量,而是看数据的真实性;当期刊把原始数据验证纳入评审流程;当研究者愿意花时间去重复别人的实验——那时,科学才真正配得上“严谨”二字。 数据的透明,才是科学的底色。