对抗知识焦虑,从看懂这条开始
App 下载
苹果桌面超算突现:雷雳5解锁万亿模型,挑战何在?
桌面高性能计算|RDMA over Thunderbolt|Kimi K2 Thinking|Mac Studio|大语言模型|先进材料|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载桌面高性能计算|RDMA over Thunderbolt|Kimi K2 Thinking|Mac Studio|大语言模型|先进材料|前沿科技|人工智能
在书桌一角,四台银色的Mac Studio静静堆叠,几乎听不到风扇的转动声。然而,这片静谧之下,一股磅礴的算力正在涌动。它们并非在剪辑视频或处理图像,而是在本地运行一个参数高达万亿的AI模型——Kimi K2 Thinking。这曾是只有在耗电巨大的数据中心才能上演的场景,如今却在一套总功耗不足500瓦的桌面系统上成为现实。这戏剧性的一幕,源于苹果在macOS 26.2系统更新中悄然植入的一项颠覆性技术:RDMA over Thunderbolt。它如同一声低语,却预示着桌面高性能计算(HPC)的风暴即将来临。
这场变革的核心,是远程直接内存访问(RDMA)技术与雷雳5(Thunderbolt 5)接口的结合。想象一下,传统计算机集群的节点间通信,如同在城市高峰期开车,数据需要在CPU和操作系统这两个“交通枢纽”间反复绕行、等待。而RDMA则为数据开辟了一条专属的“高速公路”,允许一台Mac直接读写另一台Mac的内存,完全绕过CPU和系统的干预。苹果的工程师们,成功将这条以往需要昂贵InfiniBand网络设备才能铺设的“高速路”,移植到了每台Mac标配的雷雳5接口上。
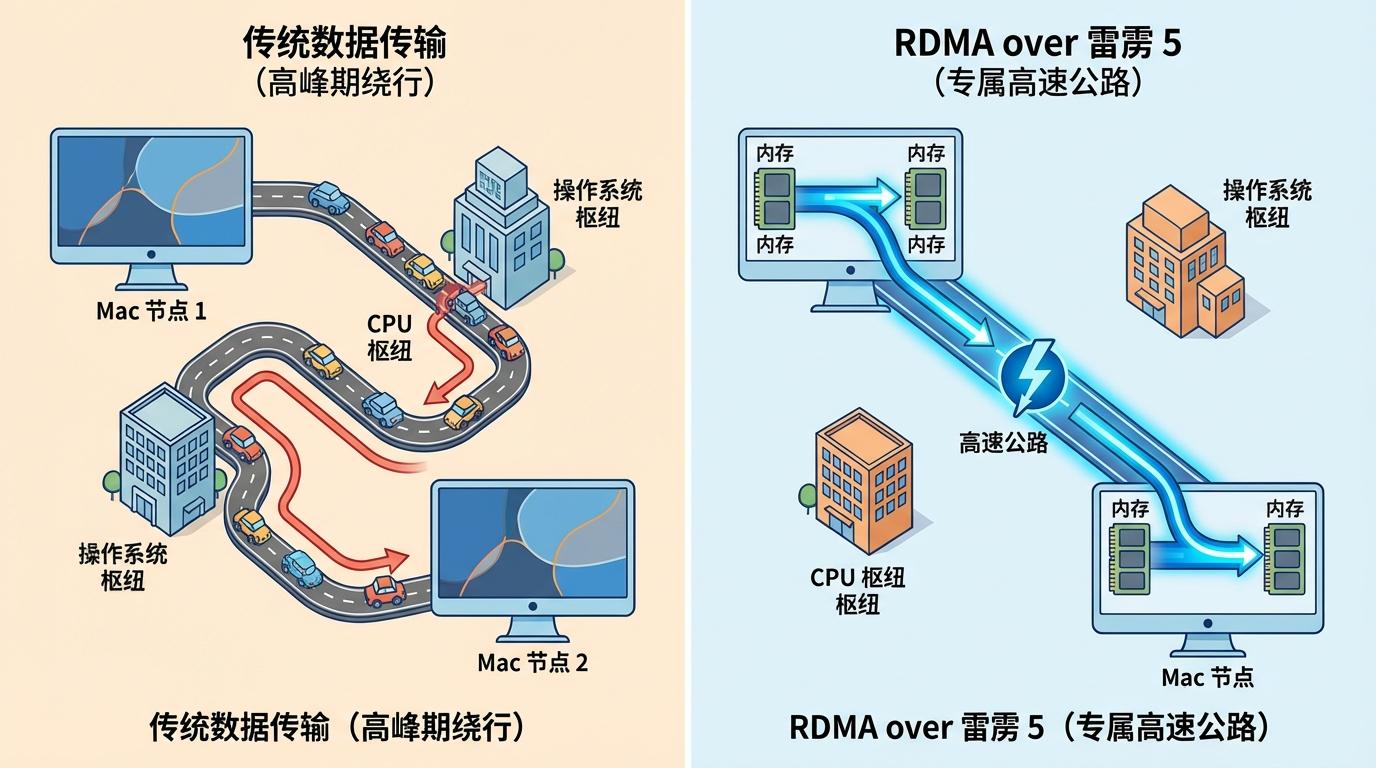
这一改变的效果立竿见影。在测试中,节点间的内存访问延迟从300微秒骤降至50微秒以下。这意味着什么?当四台Mac Studio通过雷雳5线缆相连,它们不再是孤立的个体,而是瞬间融合成一个拥有1.5TB共享统一内存池的“超级大脑”。AI模型可以自由地在整个内存池中调度数据,彻底打破了单台机器的物理内存瓶颈。
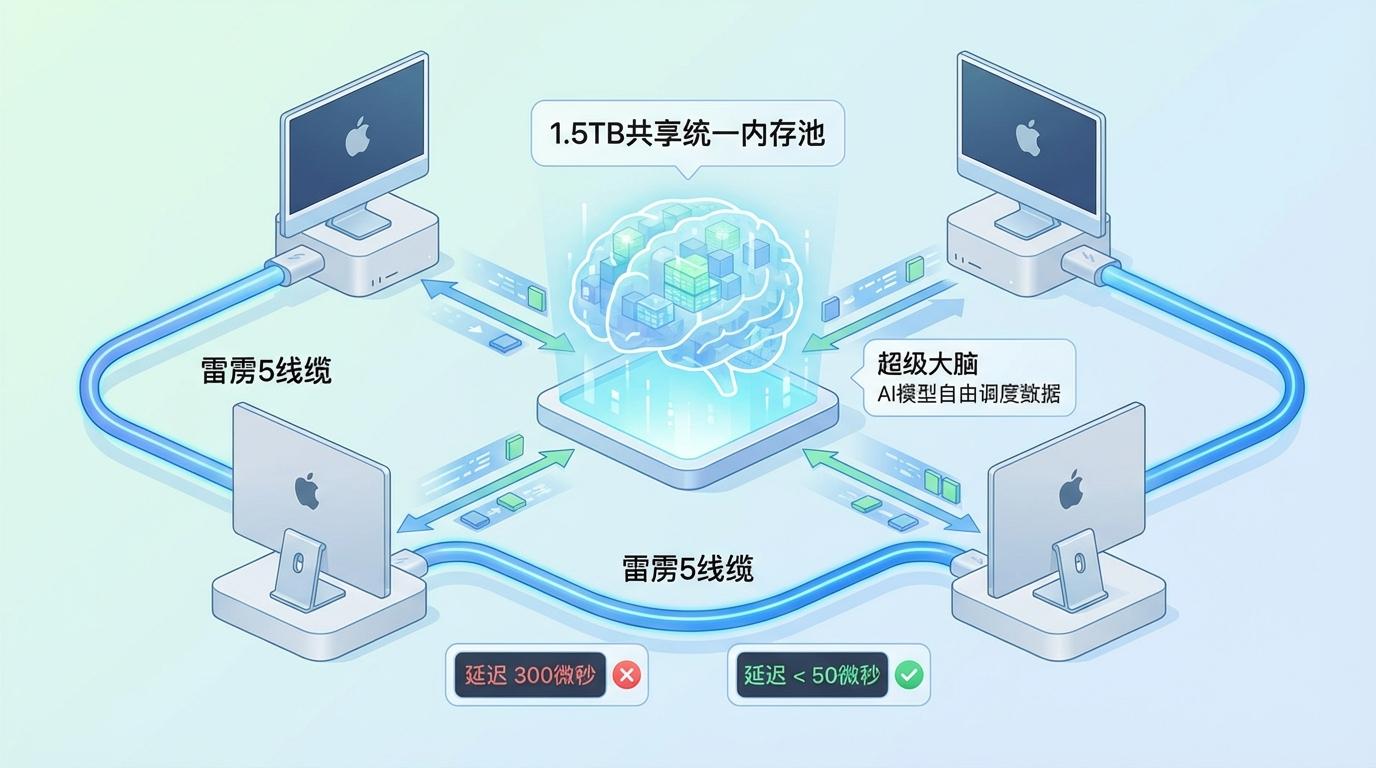
这套售价近4万美元的桌面集群,展现了惊人的潜力。
更令人惊叹的是其功耗奇迹。在满负荷运行时,整个集群的功耗被控制在500瓦以内,闲置时更是低至10瓦。相比之下,一套性能相近的传统GPU服务器集群,功耗动辄数千瓦。苹果自研芯片的极致能效比,在这一刻体现得淋漓尽致。它不仅是一头性能猛兽,更是一头冷静、高效的“静谧野兽”。
这并非苹果首次涉足高性能计算领域。早在本世纪初,苹果曾推出Xserve服务器和Xgrid集群软件,但最终在市场上反响平平,黯然退场。然而,二十年后的今天,历史以一种意想不到的方式重演。
这次的回归,似乎并非苹果深思熟虑的战略布局,更像是一场由技术演进和市场需求共同推动的“意外之旅”。苹果M系列芯片的统一内存架构,为本地运行大型AI模型提供了得天独厚的优势。而以牛津大学研究员Alex Cheema为代表的Exo Labs团队,则敏锐地捕捉到了这一潜力,率先探索出将多台Mac串联成AI集群的方案,向业界展示了“桌面超算”的可能性。可以说,是社区的创新“拉动”了苹果,最终促使其在操作系统层面正式赋能这一应用场景。
尽管前景光明,但通往桌面HPC的道路并非一片坦途。当前的方案仍面临三大挑战:
眼前的局限也催生了对未来的遐想。苹果会如何解开这些束缚?
或许,未来的Mac Pro会重新拥抱PCIe插槽,为用户提供接入InfiniBand等专业网络的选择。又或者,苹果会在下一代Mac Studio上做出妥协,加入一个QSFP端口,以满足专业集群的需求。软件层面,llama.cpp等更多AI框架对RDMA的支持,以及SMB Direct协议的引入,将极大地拓展Mac集群在AI推理和高性能文件共享(如影视后期制作)领域的应用。
这一切都指向一个核心问题:苹果是否愿意为这个小众但极具影响力的市场,做出超越消费级产品的改变?
苹果此次在桌面AI集群上的突破,最精妙之处在于其双重价值。即使AI的热潮褪去,这些Mac Studio依然是顶级的创意工作站,安静、高效、强大,能出色地完成视频剪辑、3D渲染等专业工作,其价值不会因单一趋势的兴衰而消散。
与过去自上而下的宏大战略不同,苹果似乎正在以一种更务实、更贴近用户需求的方式,悄然构建其在AI时代的新生态。它没有直接对标数据中心,而是将目光投向了无数个创意工作者、小型研究团队和注重数据隐私的企业。通过雷雳5这根不起眼的线缆,苹果正在重新定义“个人超级计算机”,将曾经遥不可及的HPC能力,带到了每个人的桌面上。这或许是一场意外的革命,但它的影响,才刚刚开始显现。