
8 天前
8 天前
2026年3月的某个工作日,一位程序员像往常一样打开AI工具写代码,刚接了个10分钟的电话回来,就发现自己的订阅配额快见底了——而他上周还从来没碰过限额。与此同时,他的API账单比上个月涨了32%。
没人通知他规则变了。直到他导出了近12万条调用数据才发现,AI服务端的缓存TTL(缓存存活时间,就是缓存内容能重复使用的时长),从1小时悄悄改成了5分钟。这个看似微小的参数调整,像一根隐形的针,扎中了所有依赖长会话的AI用户。为什么短短5分钟,会引发这么大的蝴蝶效应?
你可以把AI的缓存想象成外卖的「预包装餐」——第一次点单时,厨房要买菜、洗菜、炒菜,成本高、耗时久;但如果是半小时内复购同款,直接拿预包装好的加热就行,成本低、速度快。这里的「半小时」就是TTL,也就是缓存内容的有效期。
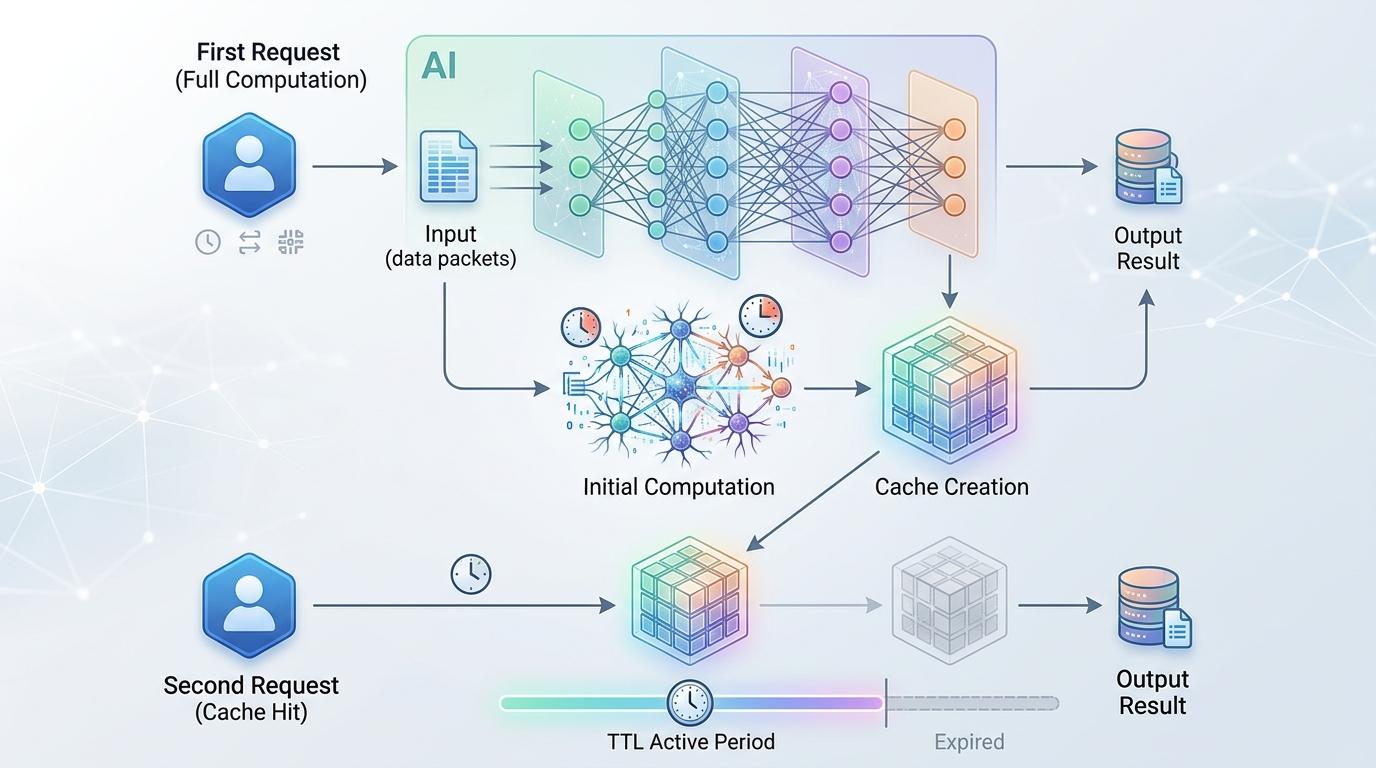
在AI系统里,「炒菜」就是缓存写入:把用户输入的上下文转换成模型能直接复用的格式,这个过程要消耗大量计算资源,所以收费是「加热」(缓存读取)的12.5倍。之前1小时的TTL意味着,只要你在1小时内继续对话,AI就会一直用「加热好的预包装餐」;改成5分钟后,只要你离开超过5分钟,回来就得重新「买菜炒菜」。
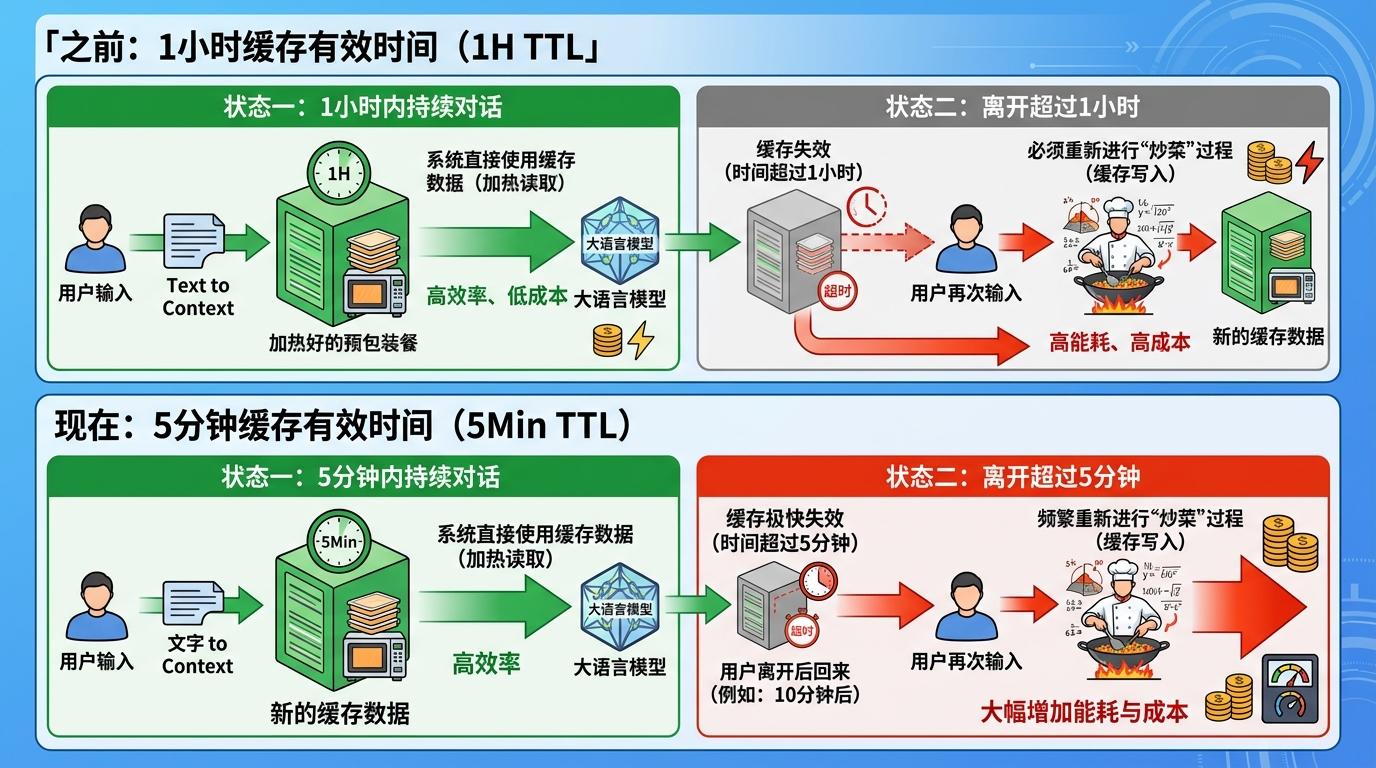
数据不会说谎:2月全用1小时TTL时,用户的成本浪费只有1.1%;3月改成5分钟后,成本直接涨了20%-32%,近三成的钱都花在了重复「炒菜」上。
对于用AI写代码、做长文档的用户来说,5分钟的TTL等于直接打断了他们的工作节奏。你不可能连续5小时盯着屏幕不眨眼——接杯水、开个短会、甚至只是起身伸个懒腰,回来就得看着AI重新加载所有上下文,响应速度从秒级变成了十几秒级。
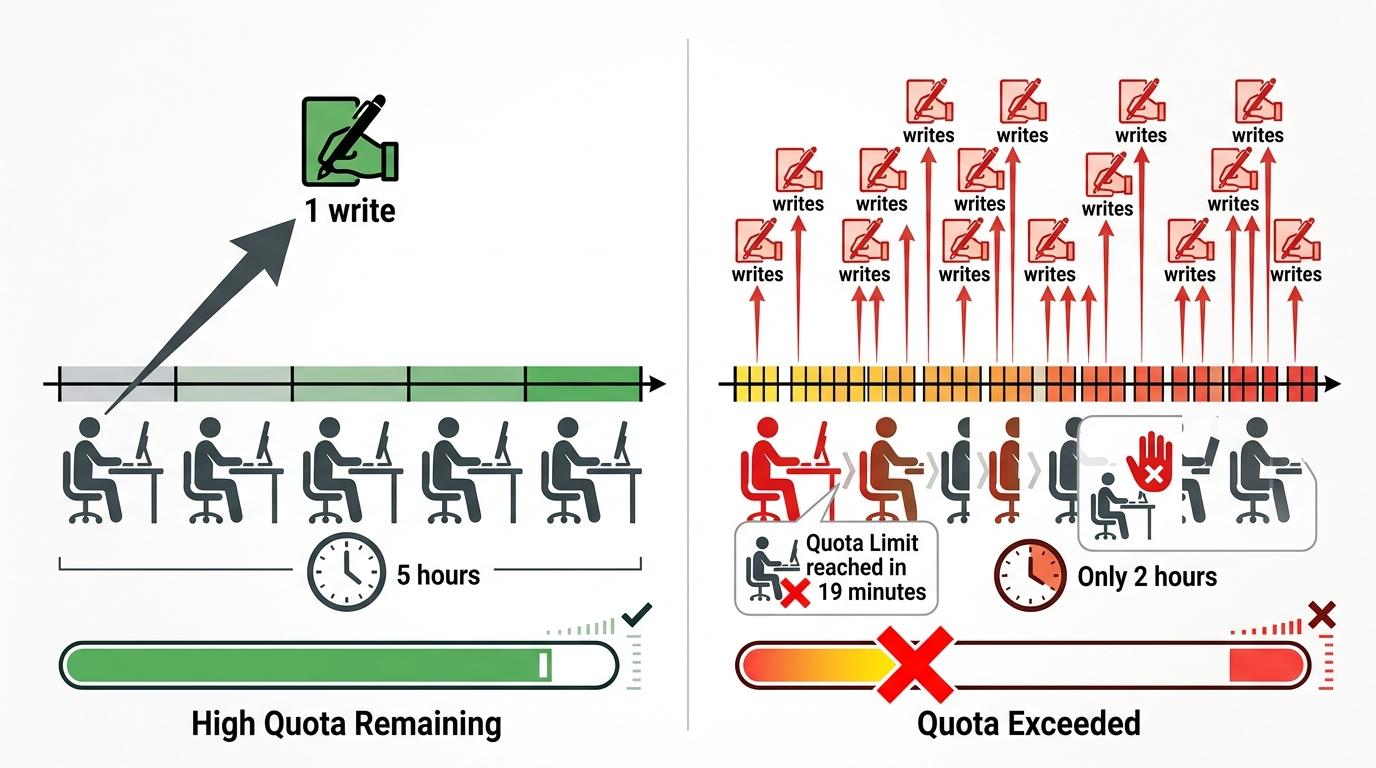
更糟的是配额耗尽的恐慌。订阅用户的配额是按「炒菜次数」(缓存写入)算的,「加热」几乎不占配额。之前1小时TTL时,一个5小时的长会话可能只需要1次写入;改成5分钟后,每中断一次就多一次写入,原本能用5小时的配额,现在可能连2小时都撑不到。有用户统计,自己的Max订阅从能连续用5小时,变成了19分钟就触顶。
最让用户愤怒的不是规则变化,而是变化的「无声无息」——没有公告,没有弹窗,甚至没有邮件提醒,直到账单和配额报警才发现不对劲。这种「暗箱操作」式的调整,让用户完全失去了成本预判的可能。
从技术角度看,缩短TTL确实能降低AI服务商的缓存存储压力——毕竟缓存要占服务器内存,有效期越短,需要存的内容就越少。但这本质上是把成本从服务商转移到了用户身上,而且是以牺牲用户体验为代价。
更棘手的是缓存一致性的难题:如果要恢复1小时TTL,服务商得解决「缓存内容过时」的问题;但如果继续用5分钟TTL,又要面对用户的信任危机。目前行业里还没有完美的平衡方案,有的服务商开始尝试动态TTL——根据用户的使用频率自动调整有效期,高频对话给长TTL,低频对话给短TTL,但这种智能调整又带来了新的透明度问题:用户怎么知道自己的TTL是多少?
这场由5分钟引发的风波,其实暴露了AI服务的一个核心矛盾:当AI从「工具」变成「基础设施」,用户需要的就不只是功能,更是稳定、透明的规则——毕竟没人愿意在看不见的地方,为别人的成本优化买单。
当我们谈论AI的「大模型」「大参数」时,往往忽略了这些像TTL一样的「小开关」——它们看似不起眼,却直接决定了用户的钱包和体验。
这场5分钟的风波,最终指向的是AI服务的「信任底线」:技术可以迭代,规则可以调整,但所有变化都应该摊在阳光下。毕竟,用户为AI付的不只是算力的钱,更是对服务稳定性的信任。
小参数,藏着AI服务的大良心。
点击充电,成为大圆镜下一个视频选题!