对抗知识焦虑,从看懂这条开始
App 下载
36年前的8位游戏,教会AI怎么玩策略
结构化文字描述|智能感知接口|复古模拟器|PvP-AI|拉塞尔·哈珀|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载结构化文字描述|智能感知接口|复古模拟器|PvP-AI|拉塞尔·哈珀|大语言模型|人工智能
1990年,程序员拉塞尔·哈珀写完了一款8位对战游戏PvP-AI,却赶上经济衰退,连面世的机会都没捞着。36年后,一款复古模拟器让这款老游戏重见天日——更离谱的是,它成了测试AI策略能力的绝佳实验场。
哈珀没有让AI直接盯着像素画面猜指令,而是给它装了一套“智能感知”接口:把游戏里的子弹位置、角色血量、敌人动向全转成结构化的文字描述。就像给蒙着眼的玩家递了份实时战报,AI不用再费力“看”游戏,只需要专心想怎么赢。结果出人意料:经过三局对战,GPT-4o居然摸出了一套稳赢的策略。
这背后藏着的,是AI与游戏交互的全新逻辑——为什么文字比像素更适合AI玩游戏?
你可以把传统AI玩游戏的方式想象成:让一个从没接触过游戏的人,盯着满是雪花的老电视屏幕,猜按哪个键能躲开子弹。像素画面里的每一个点都是噪音,AI得用庞大算力把这些噪音拼成有意义的信息,往往还没等它“看”明白,游戏里的角色已经挂了。
但智能感知接口完全跳过了这个麻烦。它就像游戏里的内置作弊器,直接把所有关键信息整理成清晰的文字:“玩家位于(120,80),血量70%;右侧30像素处有1个敌人,正向左移动;当前有2发子弹可用”。
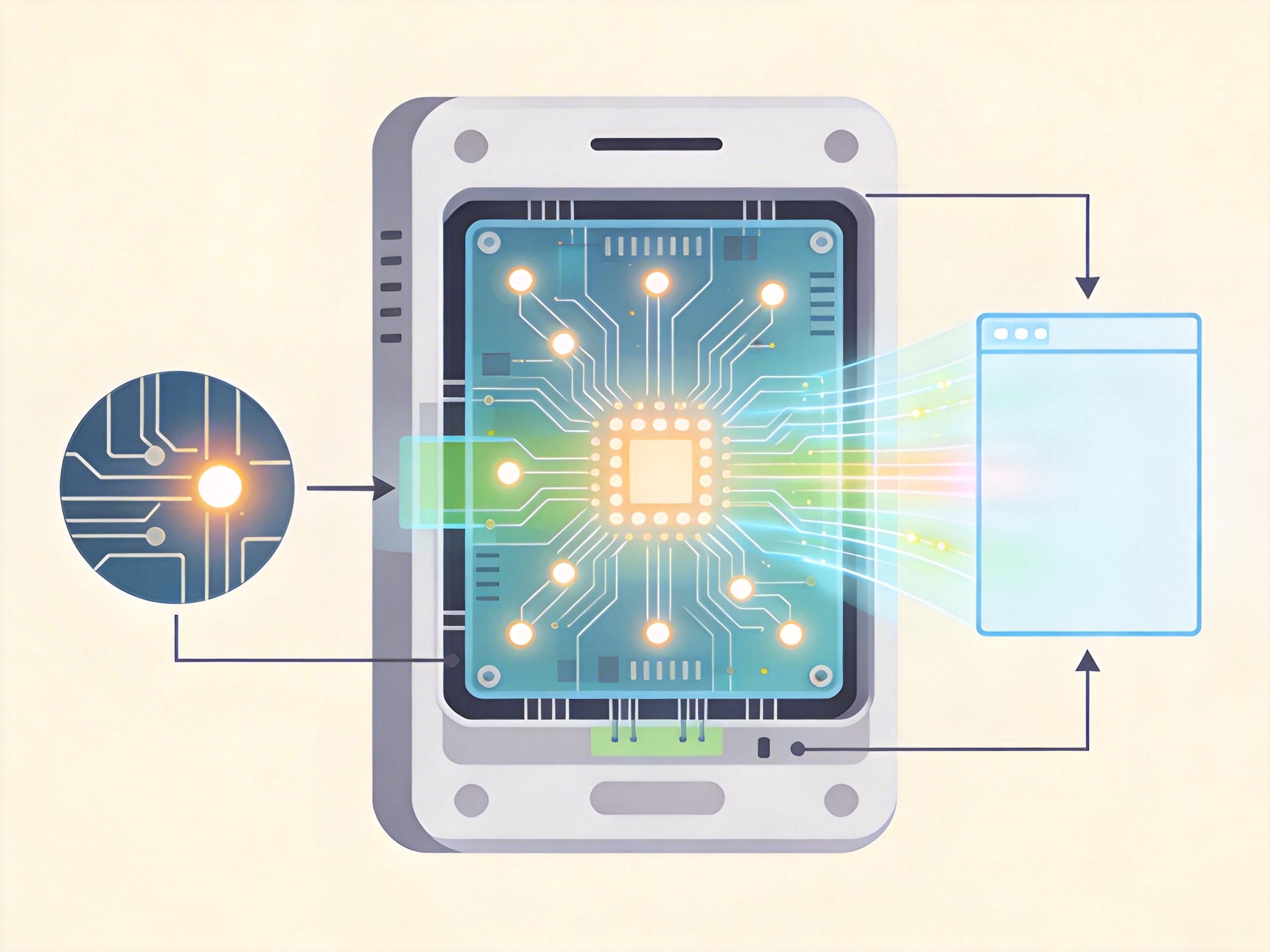
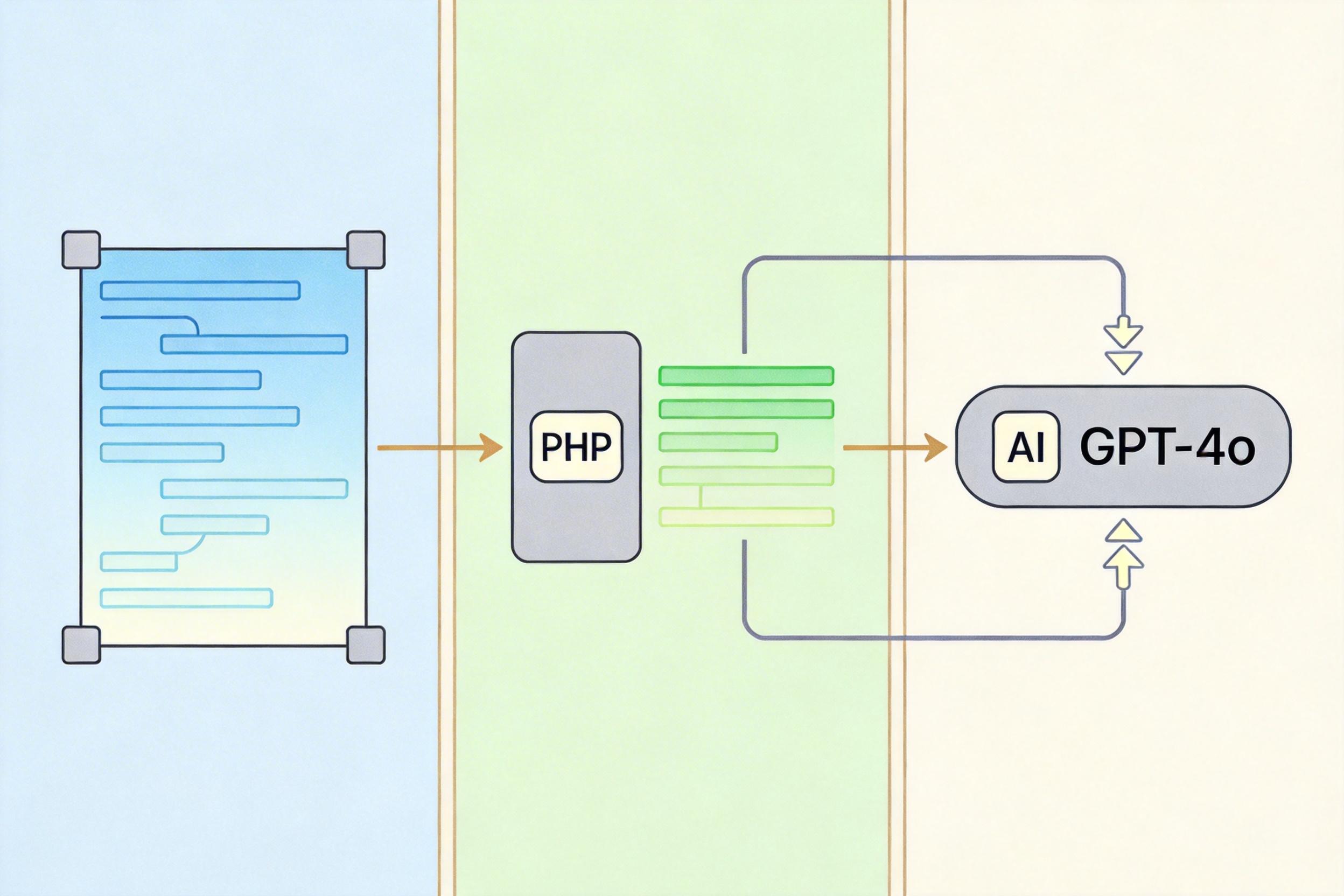
但真实的机制比这更精确。这个接口会在每两帧(为了平衡成本)就从模拟器里提取一次结构化数据,通过PHP中间层传给GPT-4o。AI不用再处理任何视觉或音频信号,只需要基于这些文字做两件事:分析当前局势,然后输出“左移”“射击”这类极简指令。这套流程把AI的算力消耗砍掉了大半——它不用再当“视力障碍者”,而是直接拿到了上帝视角的战报。
更关键的是,这让AI的优势真正发挥了出来。LLM本来就擅长基于文字做逻辑推理和策略规划,现在不用被感知任务拖后腿,它能专注于思考“什么时候躲、什么时候射”,甚至能从多局对战里总结出敌人的行动规律。
要让AI的指令真的操控游戏,还得打通一条从云端到模拟器的双向链路——这才是整个项目最容易卡壳的地方。
哈珀最初卡在了PHP和x16模拟器的通信上:前者是网页开发常用的脚本语言,后者是复古电脑的模拟器,两者本来就不是一个世界的东西。直到他给模拟器加了一个VIA2-socket的新功能——你可以把它想象成在两个完全不兼容的设备之间,插了个万能转接头。
这条链路的运行逻辑简单直接:
为了控制成本,哈珀特意把API调用频率设为每两帧一次,而不是每一帧。就像看球赛时每两分钟听一次解说,既不会错过关键信息,也不会花冤枉钱。测试下来,这套链路在模拟器上能跑到8.6帧每秒,足够支撑AI做出连贯的策略——哪怕在真实硬件上因为图形模块的问题降到4帧每秒,AI的策略逻辑也不受影响。
有意思的是,这套链路的兼容性意外地好。只要把游戏状态的输出格式统一,它能对接几乎任何LLM,也能适配其他复古游戏模拟器。
哈珀记录了GPT-4o和PvP-AI对战的三局完整过程,结果像极了一个新手玩家的成长曲线。
第一局,AI完全在瞎试:乱开枪,乱走位,没两分钟就被敌人打爆了。但它把这局的所有战报都记在了“脑子里”——第二局,它开始有意识地躲敌人的子弹,还会在敌人靠近时连续射击。到了第三局,它已经摸出了敌人的行动规律:敌人会每隔三秒从右侧出现,移动速度固定。AI干脆提前蹲在敌人的必经之路上,等敌人一露头就开枪,直接把胜率拉到了100%。

这不是AI学会了“玩游戏”,而是它学会了“基于规则做最优决策”。在结构化的文字信息面前,游戏里的所有变量都成了可计算的参数:敌人的移动速度是X,子弹的飞行速度是Y,那么最佳射击时机就是X/Y秒之后。LLM的逻辑推理能力,在这个简化的环境里被放大到了极致。
但它也暴露了LLM的局限:一旦游戏里出现随机事件,比如敌人突然改变移动路线,AI的策略就会瞬间失效。它擅长基于已知信息推理,却不擅长应对“意外”——这也是为什么它在需要协调的博弈游戏里表现糟糕。
当我们还在惊叹AI能画出生动的图片、写出流畅的文章时,这款36年前的8位游戏已经悄悄展示了AI的另一种可能:它不需要“看懂”世界,只需要“理解”规则。
智能感知接口的本质,不是让AI更像人,而是让AI更像AI——把它从低效的感知任务里解放出来,专注于它最擅长的逻辑推理。这就像给一个数学家递上一张已经整理好的试卷,而不是让他自己去辨认模糊的手写题目。
文字比像素,更懂AI的语言。
未来的AI或许不会像人类一样“体验”游戏,但它会比任何人类玩家都更懂游戏里的规则与策略——而这,可能才是AI真正统治游戏的开始。