对抗知识焦虑,从看懂这条开始
App 下载
一行代码漏写,半个社交平台停摆8小时
系统故障|bind: address already in use|端口耗尽|Bluesky|软件工程|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载系统故障|bind: address already in use|端口耗尽|Bluesky|软件工程|前沿科技
2026年4月6日周一,美国社交平台Bluesky的用户发现,自己刷不到新动态,发不出帖子,服务时断时续整整8小时——一半以上用户陷入无网可用的窘境。
工程师们最初以为是网络线路故障,直到翻到日志里一行不起眼的报错:「bind: address already in use」——端口被占满了。没人想到,这场波及百万用户的灾难,源头是一行被注释掉的代码;更没人料到,端口耗尽只是开始,真正让系统彻底瘫痪的,是一个自我强化的「死亡螺旋」。
你可以把网络端口想象成家里的插座——每个插座一次只能插一个设备,整个房子的插座数量是固定的。在计算机网络里,每个对外连接都需要一个「端口插座」,Linux系统默认只有约2.8万个可用的临时端口,相当于一个小户型的插座总数。
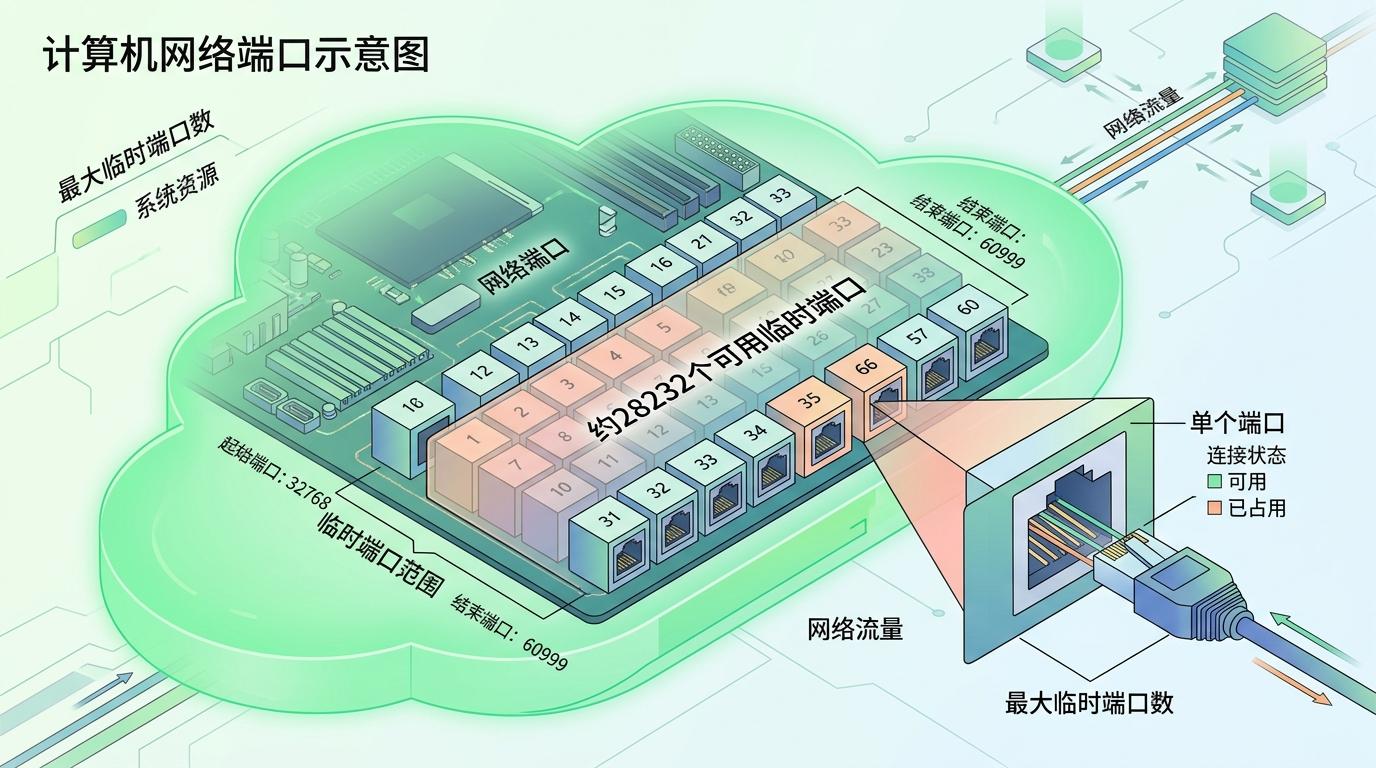
Bluesky的问题出在一个批量查询接口:它一次要处理1.5万到2万个请求,且没有设置并发限制——相当于同时插上1.5万个电器,瞬间把插座占满。这些请求都是短连接,用完就断开,但TCP协议有个「TIME_WAIT」机制:断开后端口会被系统保留1到4分钟,防止旧数据干扰新连接,就像拔下插头后,插座要冷却一会儿才能再用。
1.5万个请求瞬间生成1.5万个TIME_WAIT端口,直接耗尽了2.8万个的总配额。新的连接请求过来时,系统找不到可用端口,只能返回「地址已被占用」的错误。
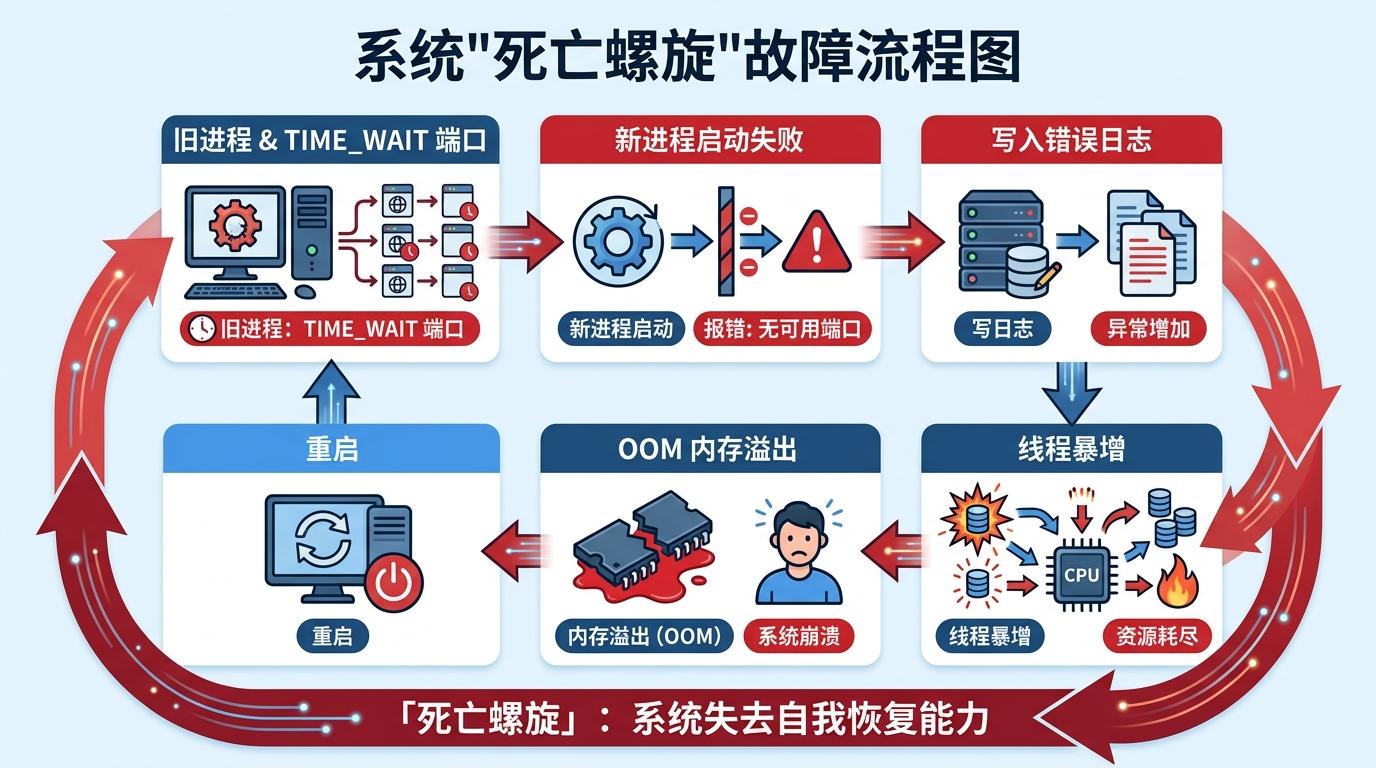
端口耗尽已经够糟,但真正的灾难是随之而来的负反馈死循环。
当memcached缓存服务因为端口连不上报错时,系统会自动记录错误日志。而Bluesky每秒要处理数百万次缓存请求,端口耗尽后,错误日志的生成量直接飙升到每秒数百万条。Go语言的日志写入是阻塞式的——每写一条日志,就会占用一个系统线程,导致Go运行时被迫创建出10倍于正常水平的线程(从150个涨到1500个)。
线程暴增直接压垮了垃圾回收机制:Go的垃圾回收需要暂停所有线程(STW),线程越多,暂停时间越长——最长的一次暂停达到了数秒,用户请求彻底被卡住。同时,团队之前为了优化性能,把内存限制调得非常严格,线程暴增直接触发了内存溢出(OOM),服务开始频繁重启。
但重启解决不了问题:旧进程留下的TIME_WAIT端口还没释放,新进程启动后依然找不到可用端口,只能继续报错、写日志、炸线程、OOM——系统陷入了「报错→日志→线程暴增→OOM→重启→继续报错」的死亡螺旋,彻底失去了自我恢复的能力。
工程师们最初的临时补丁堪称「野路子」:他们给memcached客户端加了一个自定义拨号器,每次连接都随机选一个本地回环IP(比如127.1.1.1、127.2.2.2)。这相当于给房子多装了几百个虚拟插座——每个IP都有2.8万个端口可用,瞬间把总配额扩大了上百倍,暂时缓解了端口耗尽的问题。
但真正的修复只需要一行代码:在批量查询接口里加上「errgroup.SetLimit(50)」,把并发请求限制在50个以内。就像给电器加个智能插排,一次只允许50个设备通电,既满足需求,又不会耗尽插座。
这场故障暴露的远不止一行代码的疏漏:团队的监控系统没有追踪每个客户端的请求量,导致最初找不到端口耗尽的源头;日志系统没有做限流,反而成为压垮系统的最后一根稻草;内存限制和并发控制的参数设置过于激进,没有留足容错空间。
当我们谈论分布式系统的稳定性时,总喜欢强调「高可用」「弹性扩容」这些宏大的概念,却常常忽略了端口、线程、日志这些看似琐碎的细节。就像一座摩天大楼,再坚固的地基,也抵不过某一层的插座过载引发的火灾。
系统的韧性,藏在被忽略的细节里。
Bluesky的这场故障,是所有高并发系统的一面镜子:它提醒我们,再先进的架构,也需要为极端情况留足容错空间;再微小的代码疏漏,也可能引发蝴蝶效应式的灾难。在追求性能和效率的同时,别忘了给系统留一条「逃生通道」——毕竟,比起极致的速度,用户更需要的是稳定的服务。