对抗知识焦虑,从看懂这条开始
App 下载
20亿参数模型,追上百亿级多跳检索性能
上下文裁剪|推理成本|参数规模|多跳检索|Context-1模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载上下文裁剪|推理成本|参数规模|多跳检索|Context-1模型|大语言模型|人工智能
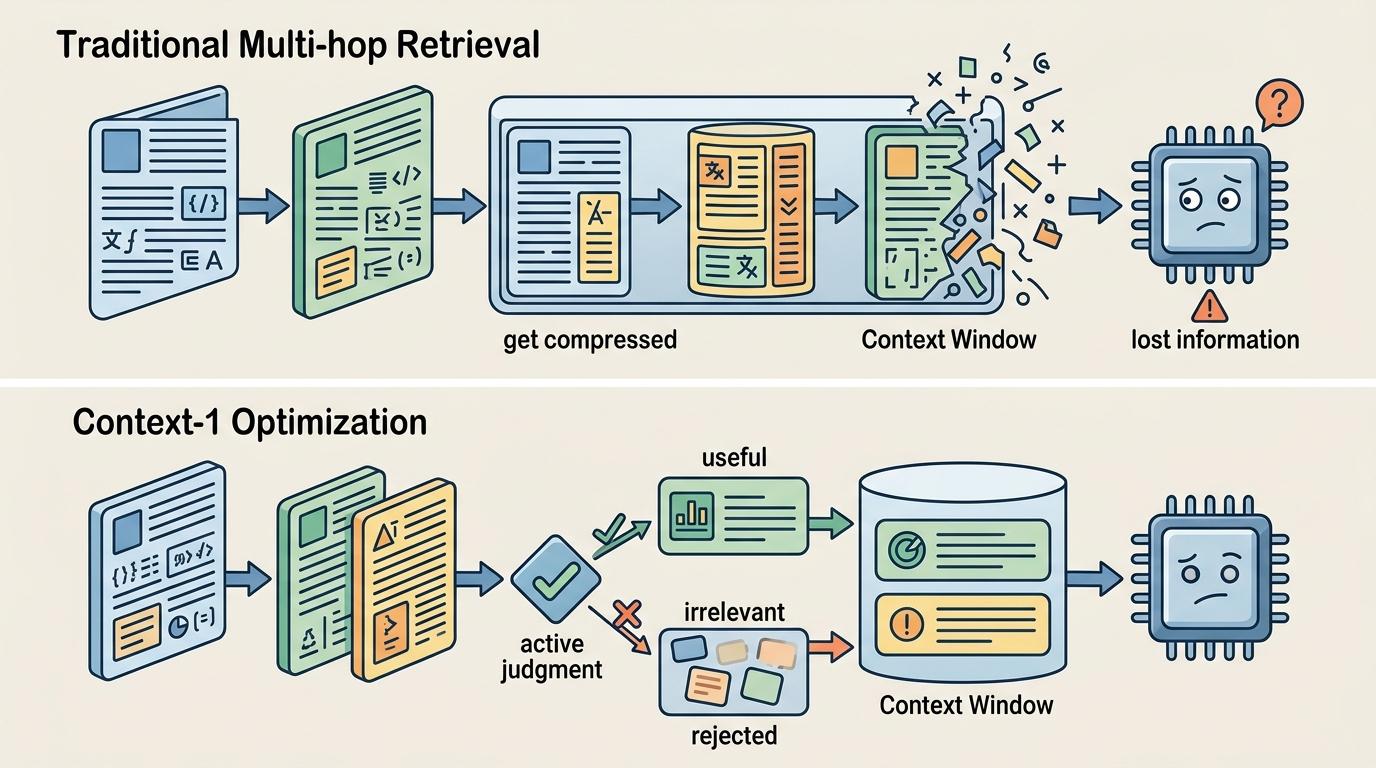
当你问AI“2024年获得诺贝尔文学奖的作家,其出生地曾出过哪一位19世纪的物理学家”时,它需要完成至少三次跳转:先找2024诺奖得主,再查其出生地,最后匹配该地区19世纪的物理学家——这就是多跳检索,曾是百亿级大模型的专属能力。但2026年春,一款仅20亿参数的中小模型Context-1,在多跳检索任务上追上了百亿级模型的精度,同时把推理成本砍到原来的十分之一。它靠的不是堆参数,而是让AI学会自己“整理抽屉”——主动裁剪冗余信息,只保留关键线索。
传统多跳检索就像往抽屉里塞文件:每跳一次就塞一份新文档,跳得越多,抽屉越满。当上下文窗口被冗余信息占满,AI要么被迫截断关键线索,要么被无关内容干扰得“迷失方向”——这就是行业里说的“上下文腐败”。Context-1的核心突破,是给AI装上了“抽屉整理术”:它会在每轮检索后主动判断哪些信息有用,哪些可以丢弃。
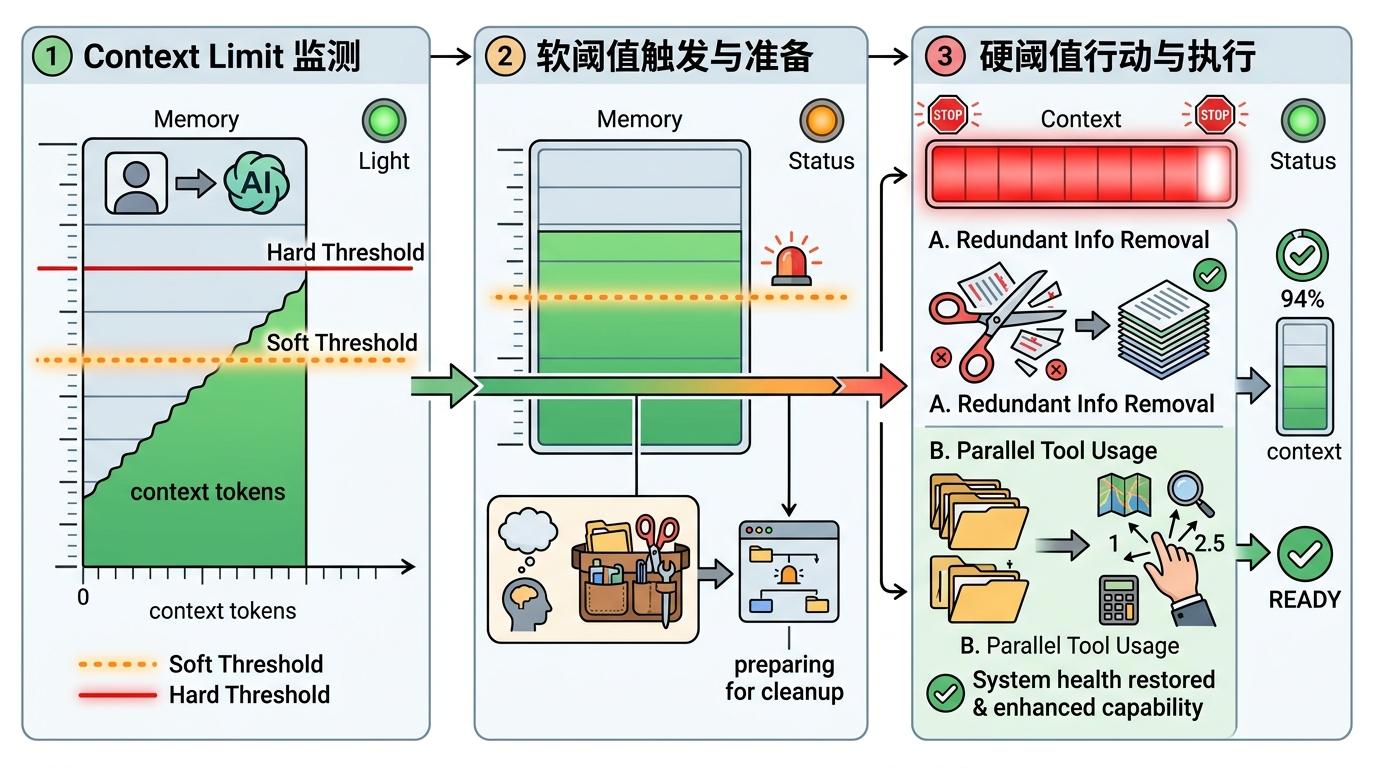
这套“自编辑上下文”机制靠软硬双阈值驱动:当上下文令牌数接近软阈值,AI会收到“该整理了”的提示;触发硬阈值时,除了裁剪操作,所有工具调用都会被拒绝。实验数据显示,Context-1的裁剪准确率高达0.94,能精准剔除94%的冗余信息,同时把单轮工具调用数从传统模型的1次提升到2.56次——相当于一边整理抽屉,一边同时打开多个文件夹找资料。
你可以把这个过程类比成写论文:初稿时你会收集所有相关文献,但修改时必须删掉无关引用,只保留支撑核心论点的证据。AI的“整理”也是同理,它会把分散的检索线索拼接成完整的推理链,同时把没用的信息全部清出上下文窗口。
Context-1能以小博大,离不开8000+高质量合成任务的训练。这些任务不是简单的问答对,而是模拟真实世界的复杂多跳场景——比如法律领域的“从判决书中找前置法律条文”,金融领域的“从财报数据推导公司战略调整”。每个合成任务都包含完整的推理链,AI在训练时不仅要学会找答案,还要学会拆解问题、规划检索路径。
它的训练采用了“先广撒网,后精筛选”的两阶段策略:第一阶段用监督微调(SFT)让AI学习基本的推理模式,哪怕检索结果有冗余也没关系;第二阶段用基于可验证奖励的强化学习(RLVR),给AI设定“召回率优先转向精度优先”的奖励机制——一开始鼓励它多找线索,后来要求它只留有用的。
在金融领域的数值语义匹配任务中,这种训练策略的效果立竿见影:Context-1的准确率达到90.3%,F1分数78.4%,比纯监督学习的模型高出10个百分点以上。更关键的是,它的推理速度比百亿级模型快10倍,显存占用减少30%-35%,单GPU就能高效部署。
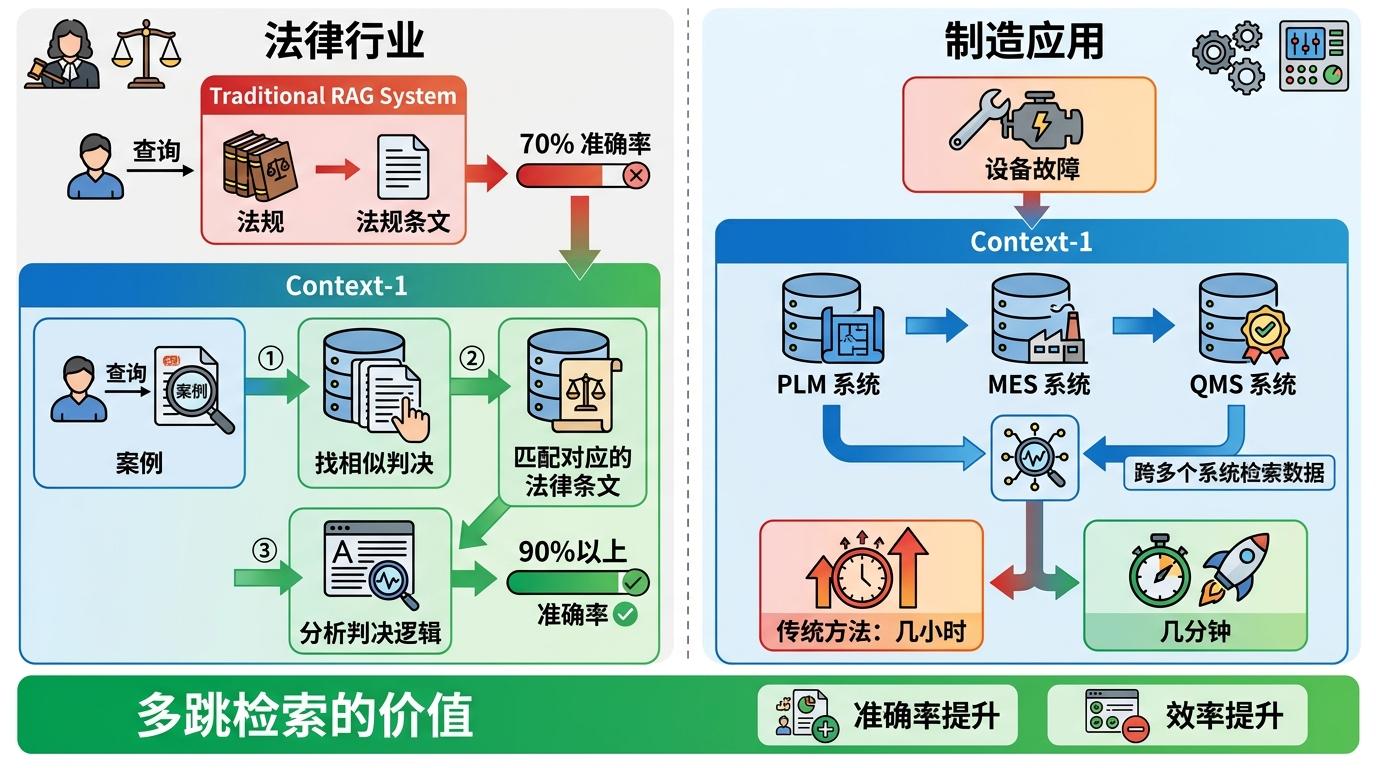
多跳检索的价值,在专业领域体现得最为直接。在法律行业,传统RAG系统只能单跳检索法规条文,而Context-1能完成“从案例中找相似判决,再匹配对应的法律条文,最后分析判决逻辑”的三跳推理,把法律问答的准确率从70%提升到90%以上。在制造业,它能跨PLM、MES、QMS等多个系统检索数据,把设备故障排查时间从几小时压缩到几分钟。
不过,这套系统也有局限:它目前擅长的是“深度型”多跳任务——比如找一个特定答案,但对“广度型”任务,比如“找出某公司所有违规操作”,还需要更完善的上下文管理策略。未来的方向,是把“整理抽屉”升级为“搭建书架”:用结构化笔记替代简单的信息裁剪,让AI把检索到的知识按逻辑分类存储,既能快速调用,又能避免信息丢失。
当人们还在争论“百亿参数模型和千亿参数模型谁更强”时,Context-1用20亿参数证明:AI的能力上限,从来不是由参数规模决定的,而是由它的“思维方式”决定的。让AI学会整理信息,比给它塞更多参数更重要。
这场中小参数模型的逆袭,本质上是一场“效率革命”——用更聪明的方法,解决更复杂的问题。未来的AI,或许不需要像大象一样拥有庞大的记忆,而要像狐狸一样,懂得如何精准找到自己需要的信息。
小模型,也能有大智慧。