对抗知识焦虑,从看懂这条开始
App 下载
AI的"通感"有多神奇?竟能打破感官隔阂!
模态共享坐标系|上下文理解|通感|家用AI安防系统|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模态共享坐标系|上下文理解|通感|家用AI安防系统|多模态视觉|人工智能
2024年的一个普通下午,有人在厨房举着刀切西瓜,家用AI安防系统突然触发了暴力警报——它只认出了刀,却看不见厨房、西瓜和正常的切水果动作。这不是AI的粗心,而是单模态时代的致命局限:早期AI像一群互不说话的偏科生,视觉模型只懂像素,语言模型只认文字,永远无法理解人类习以为常的「上下文」。正是这场离谱的误判,让业界彻底意识到:要让AI真正看懂世界,必须先让它拥有「通感」——像人类一样,把眼睛看到的、耳朵听到的、文字读到的信息拧成一股绳。
你没法直接比较一张猫的照片和「猫」这个词——前者是像素矩阵,后者是符号序列,它们活在完全不同的数学空间里。模态对齐要做的,就是给这些「语言不通」的信息,建一套能互相看懂的公共坐标系。
2021年OpenAI的CLIP模型,第一次拿出了成熟的解法。它先让两个「翻译官」分别干活:图像编码器把照片压缩成一串数字坐标,文字编码器把描述也转换成同维度的向量。接着,它用4亿对图文数据做「连连看」训练:配对的图文就把坐标拉近,不配对的就狠狠推开。
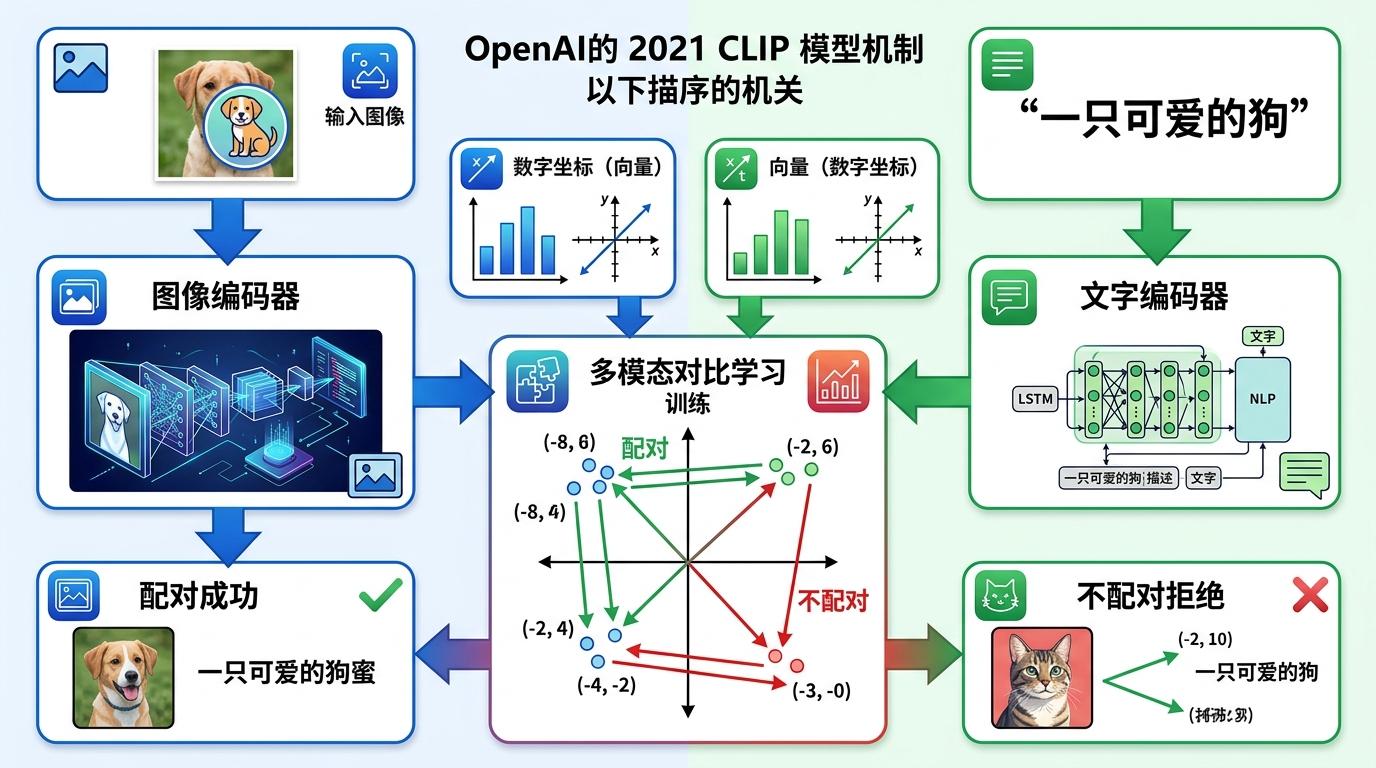
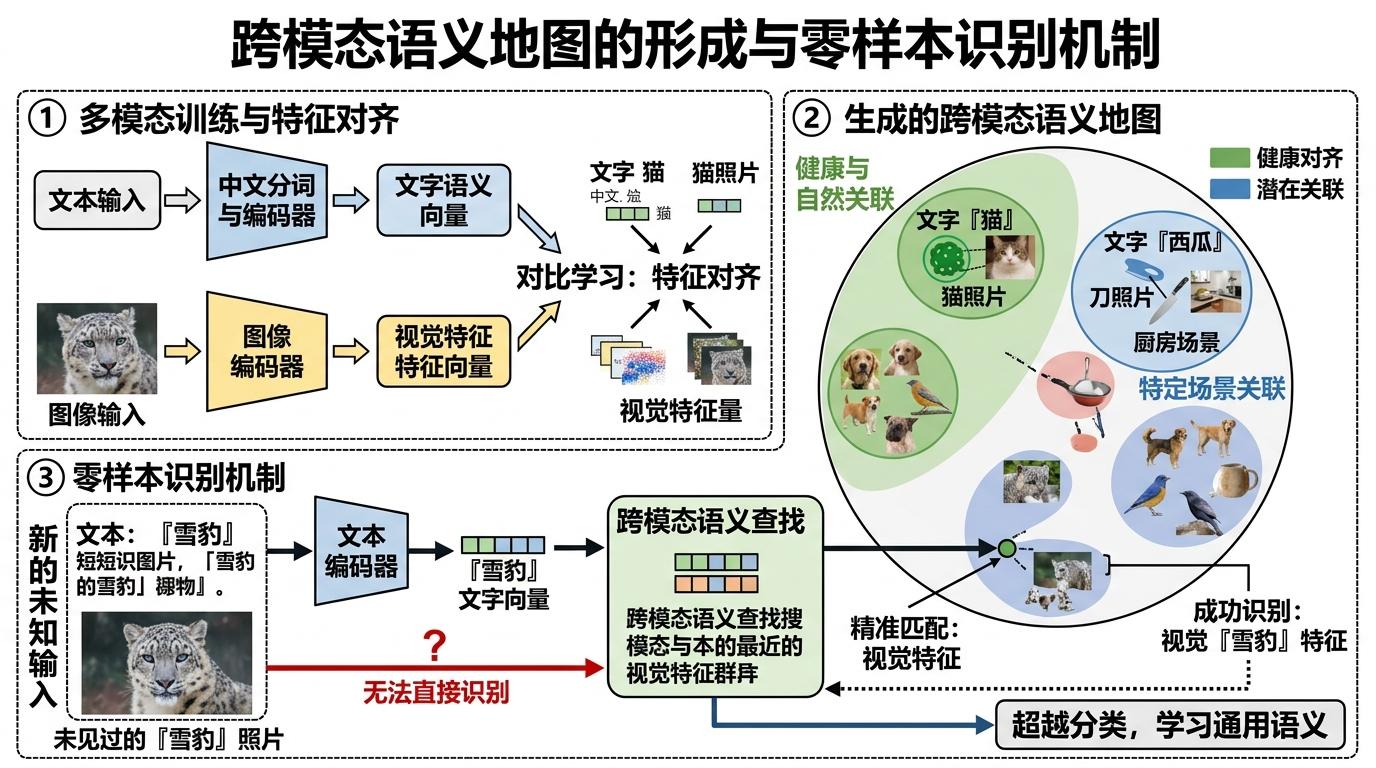
训练结束后,一张奇妙的跨模态地图诞生了:「猫」的文字向量会和猫照片的向量紧紧靠在一起,「西瓜」和「刀」在厨房场景里也会形成关联的簇。更惊喜的是「零样本识别」——哪怕从没见过雪豹的照片,输入「雪豹」的文字描述,模型也能在地图里精准找到对应的视觉特征。它学的不再是死板的分类,而是跨越模态的通用语义。
如果说对齐是让不同模态住进了同一个城市,融合就是让它们坐下来聊同一场天。业界摸索出了三条融合路径,本质都是在回答同一个问题:不同模态该在什么时候相遇?
LLaVA走的是「翻译官带话」的路子:它先把图像编码成和文字一样的Token,直接喂给语言模型,就像给外国人发了份中文译本——模型几乎不用改就能处理视觉信息,但深层理解还是有限。Flamingo则选择了「层层对话」:在语言模型的每一层都插了视觉处理的「插槽」,文字每思考一层,就和图像信息核对一次,这种深层交互让理解更细腻,但要给模型做大手术。
而GPT-4o这类最新模型,干脆让模态彻底「无界」:它把图像切成像素方块,和文字Token混在一起直接输入,从头到尾都不区分谁是图谁是字。就像人类吃饭时,不会特意区分米饭和菜的味道,只会直接感知「这顿饭香不香」。当然,这种原生融合的效果最好,训练成本也最高——毕竟要重新打造一套能兼容所有感官的「大脑」。
但无论选哪条路,都绕不开跨模态注意力机制。当你问「图中左边穿红衣服的人在做什么」,文字里的「左边」和「红衣服」会自动锁定图像对应的区域,不需要额外指令,模型靠注意力权重就能完成精准定位。这也是Transformer架构能成为多模态AI核心的原因——它天生就擅长在混乱的信息里,找到最相关的那部分。
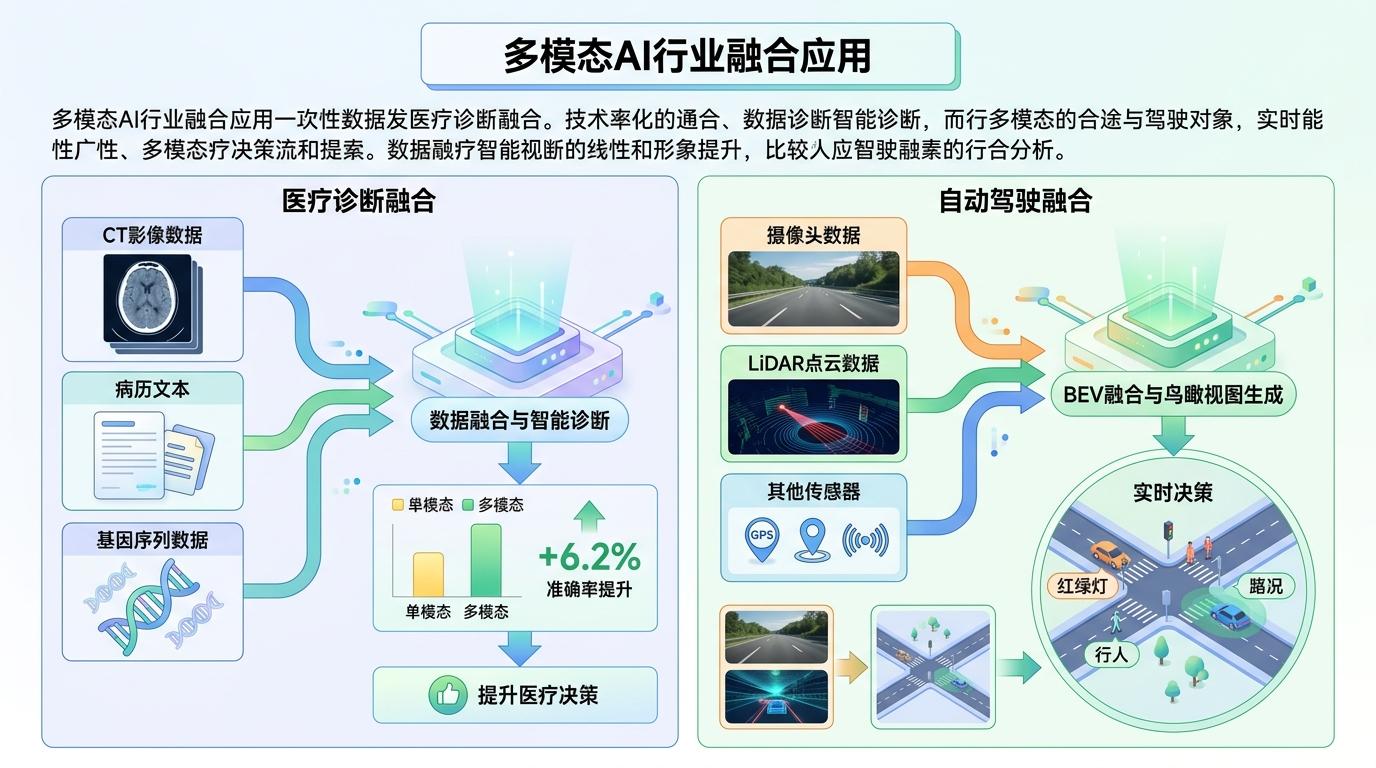
多模态AI已经开始改变行业:在医疗领域,它能把CT影像、病历文本和基因数据融合,诊断准确率比单模态模型高6.2个百分点;在自动驾驶领域,BEV融合技术把摄像头、LiDAR的信息统一到鸟瞰视角,让AI能像人类司机一样,同时看懂红绿灯、行人和路况。
但它离真正的「通感」还有距离。第一道坎是隐私——多模态AI要处理大量敏感数据,人脸、语音、医疗记录混在一起,泄露风险比单模态高得多。第二道坎是偏见——如果训练数据里的厨房场景全是白人,它可能就认不出黑人在切西瓜的正常场景,甚至叠加文本和图像的偏见,造成更严重的歧视。第三道坎是可解释性——当AI做出一个诊断,医生没法知道它是靠影像还是靠病历得出的结论,这种「黑箱」特性,让它很难进入高风险领域。
有意思的是,业界的解法正在向人类学习:比如用联邦学习在不共享数据的前提下训练模型,用多样化的数据集模拟人类的多元认知,用注意力可视化让AI的决策过程变得可追溯。
从切西瓜的误判,到能同时看懂90分钟视频的Gemini,AI用了不到3年时间,就从「偏科生」变成了「通感体」。它不再是只会识别单个物体的机器,而是开始理解「在厨房用刀切西瓜」这件事的完整语境。
未来的AI不会是某个单一感官的专家,而是像人类一样,用所有感官去拼凑世界的全貌。通感不是AI的终点,而是它理解世界的起点。当它能像我们一样,同时看到、听到、感受到同一个场景时,我们或许才能真正和AI对话——不是用代码,而是用一种更接近人类的方式。