对抗知识焦虑,从看懂这条开始
App 下载
AI有了"脑内剧场"?这居然是科学家在发力的方向!
数学结构学习|虚拟梦境训练|物理规则模拟|世界模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载数学结构学习|虚拟梦境训练|物理规则模拟|世界模型|大语言模型|人工智能
当你在脑子里预演“伸手去接掉落的杯子”时,你调用的不是记忆,而是大脑里的“世界模型”——一套能模拟物理规则、预测未来的隐形引擎。这正是今天的AI最缺的东西:它能算出杯子落地的时间,却没法像人一样“想象”出接杯子的完整过程。
为了给AI装上这颗想象力引擎,全球顶尖团队趟出了三条路。有人让AI在虚拟梦境里反复试错,有人喂给它千万小时的真实视频,还有人干脆放弃像素,让AI直接学世界的数学结构。但没人想到,这些看起来前途光明的路线,最后全撞在了看不见的墙上。
2018年,Ha和Schmidhuber给AI找到了一个“做梦”的方法:不用让它模拟每一个像素,而是把画面压缩成极简的“脑内印象”——就像你回忆晚餐时,只会想起“一碗牛肉面”,而不是每粒米的位置。AI只需要预测下一个“印象”,就能在虚拟梦境里反复练习。
DeepMind的MuZero把这条路走得更远:它连画面印象都不预测了,只盯着对决策最重要的三个变量——赢面、奖励、下一步动作。就像一个棋手不用在脑子里还原整盘棋,只需要算清每一步的得失。结果MuZero在完全不知道游戏规则的情况下,把围棋、国际象棋等57个游戏玩到了超人水平,甚至能在《我的世界》里从零开始挖到钻石。
但这个在虚拟世界里呼风唤雨的AI,一碰到真实世界就露了怯。现实里的光影会变、噪声会干扰,哪怕初始预测只有0.1%的误差,推演几十步后也会像滚雪球一样放大成完全失真的画面——这就是让AI“抽风”的元凶:误差累积。虚拟梦境里的规则越清晰,和真实世界的鸿沟就越深。
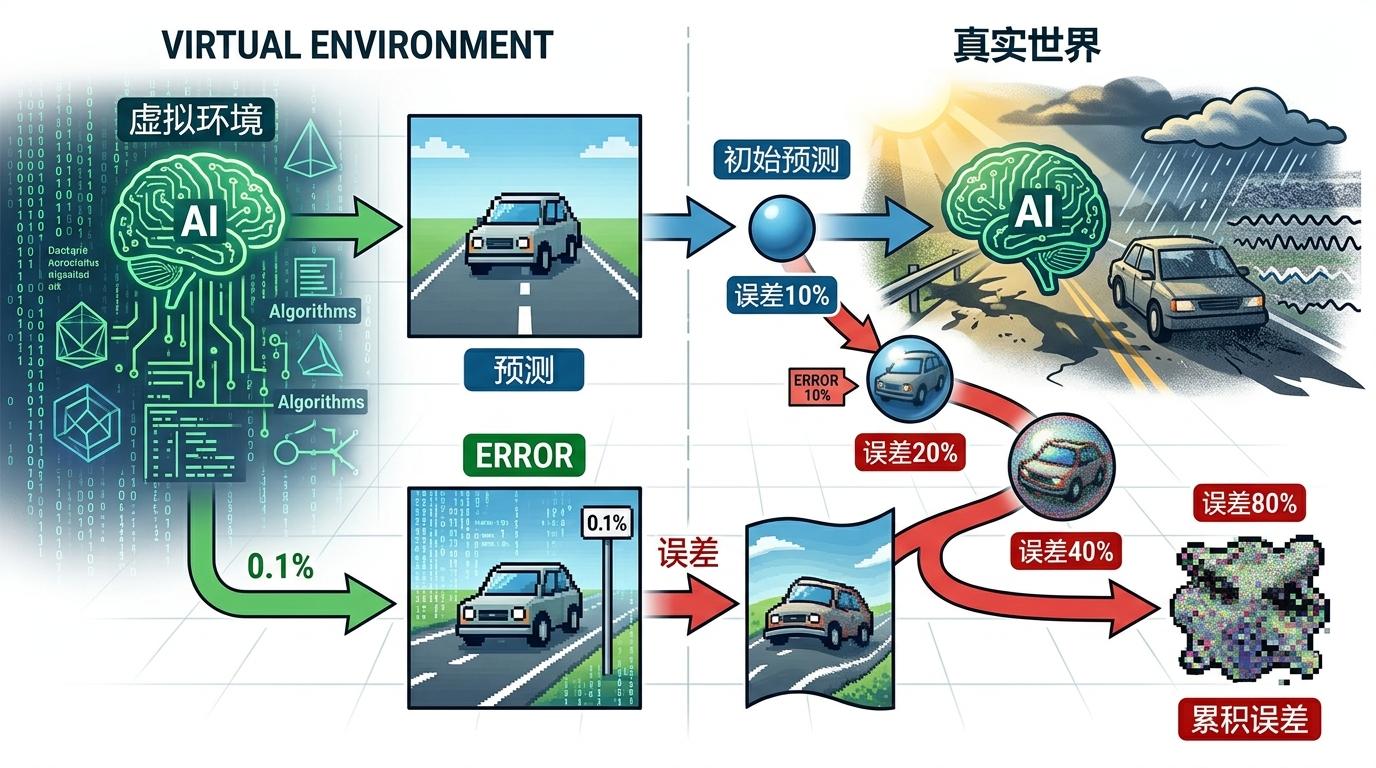
既然虚拟世界不够真实,那让AI直接看真实世界的视频总行吧?2024年,能生成逼真东京街头视频的Sora横空出世,整个行业都沸腾了:“视频生成模型就是世界模拟器!”几乎所有玩家都开始疯狂投喂视频、堆算力,以为AI看够了自然就懂物理了。
但几个月后,科学家给这些模型出了张初中物理试卷,结果是一场屠杀。AI能完美生成杯子掉落的画面,却不是因为懂重力,而是背下了几万个杯子掉落的视频——它记住了世界的样子,却没学会世界的规则。遇到没见过的场景,比如让杯子往斜上方飞,AI生成的画面里,物体直接穿过了桌面,液体像果冻一样悬浮在空中。
为了补上交互的短板,Google的Genie能从一张图片生成可操控的3D世界,你按左键角色就往左走,走到边界它还能自动脑补新区域。但代价是,空间越大,AI脑补的细节就越模糊——你要么选一个逼真但只能转圈圈的小房间,要么选一个能逛但像马赛克的大地图。更致命的是,实时生成这样的3D世界,需要的算力是天文数字,根本没法大规模落地。

就在所有人为像素疯狂时,图灵奖得主杨立昆掀了桌子:“预测每一个像素,是巨大的浪费。”他反问,你要判断杯子掉下来会不会碎,需要算清每一道光的折射角度吗?不需要,你只需要知道“杯子会掉,掉了大概率会碎”。
他提出的JEPA路线,让AI直接跳过像素,去学世界的抽象数学结构:物体在哪、关系是什么、下一步趋势是什么。如果说Sora是拍高清照片,JEPA就是画结构素描。Meta用超过一百万小时的视频训练出V-JEPA 2,它不输出任何画面,只输出一串串抽象编码,但就是这个“看不见”的模型,只看了62小时机器人操作视频,就能指导真实机械臂在从未见过的实验室里完成抓取任务。
但这条高效的路,却撞上了信任的墙。在一个“眼见为实”的时代,你怎么向普通人证明,一个什么画面都不输出的模型,真的理解了世界?没人能看懂那些抽象编码,也没人敢把真实世界的决策,交给一个“黑箱”里的数学公式。
最新测评显示,当前最先进的世界模型,在“长期规划”上只拿了17.3分——满分100。这意味着,AI离真正的“想象力”还远得很。它能算出下一步,但算不出一百步后的世界;它能模仿见过的场景,却没法想象没见过的未来。
人类的世界模型,花了几百万年才进化出来,它不仅能模拟物理规则,还能理解人的情绪、社会的逻辑。而AI的想象力引擎,现在还停留在“学走路”的阶段——摔了无数次,才终于能站稳,但要像人一样跑起来,还有无数堵墙要撞。
懂世界的规则,比记住世界的样子更重要。